Spark离线项目创建和运行步骤
一、安装maven
1.解压maven安装包,将加压后的安装包放在没有中文路径的目录下
2.创建仓库文件夹repository(理论上任何位置都是可以的,建议和maven文件夹同级别,这样好管理一些)
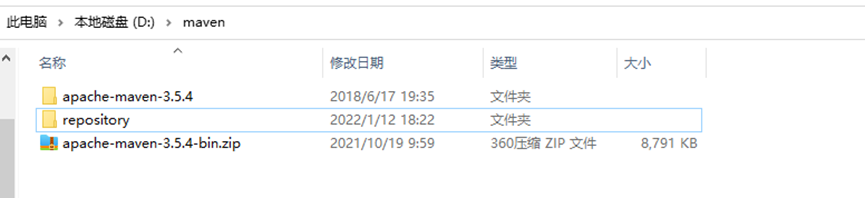
3. 要修改settings文件,进入到 apache-maven-3.5.4\conf目录下
4. 修改settings文件,要修改的地方有两个,分别为localRepository与mirror两个位置
5.我们可以把原来自带的localRepository哪一行注释掉,然后复制一行出来,中间的值填写2中刚才仓库的位置路径
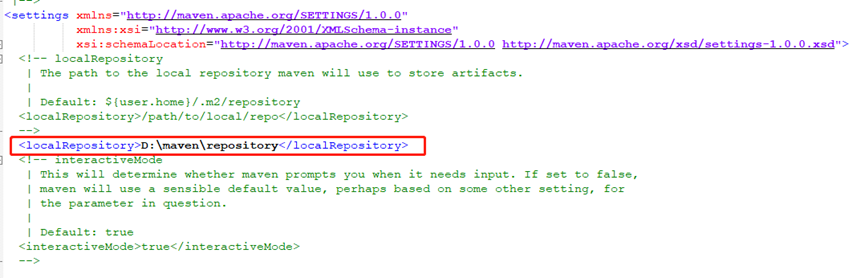
找到<mirrors>标签,在其中添加以下镜像,分别为阿里云和官方仓库
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*,!cloudera</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
<mirror>
<id>mirrorId</id>
<mirrorOf>*,!cloudera</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
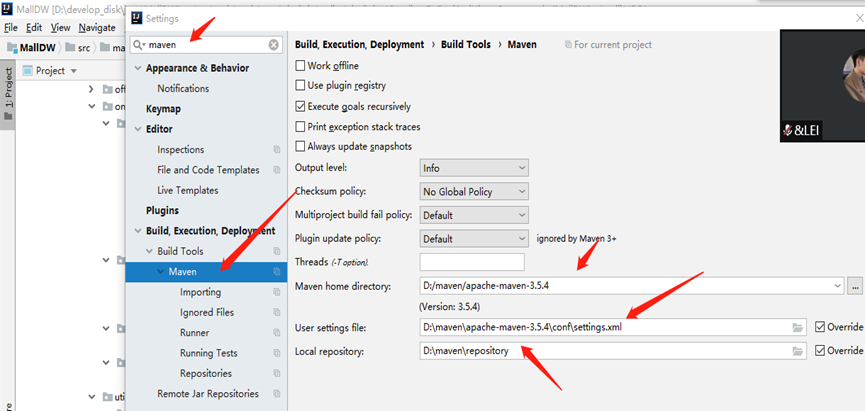
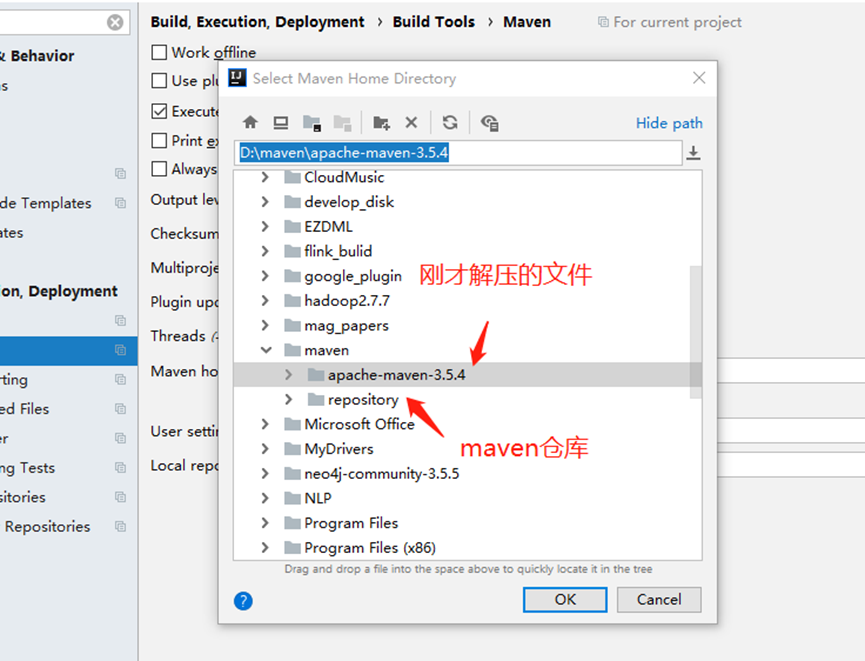
6. 在idea配置maven
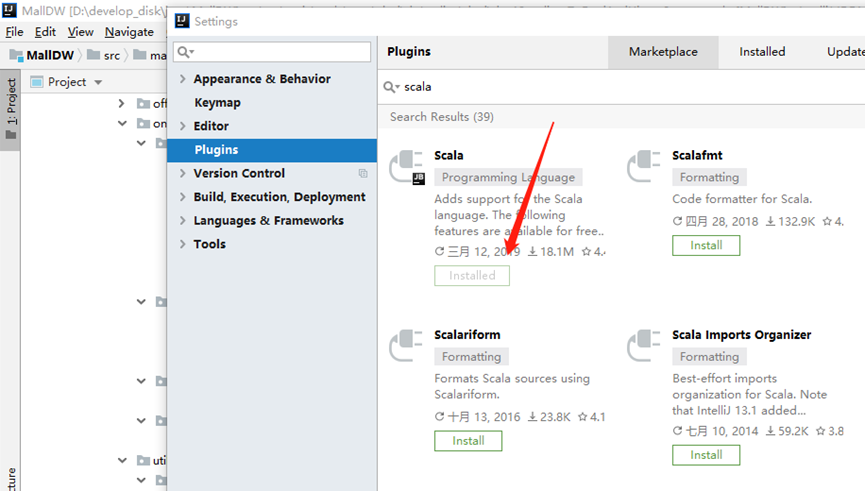
二、安装scala插件
三、安装scala sdk
https://cloud.tencent.com/developer/article/1979321
四、创建项目
1. 创建一个普通的maven项目
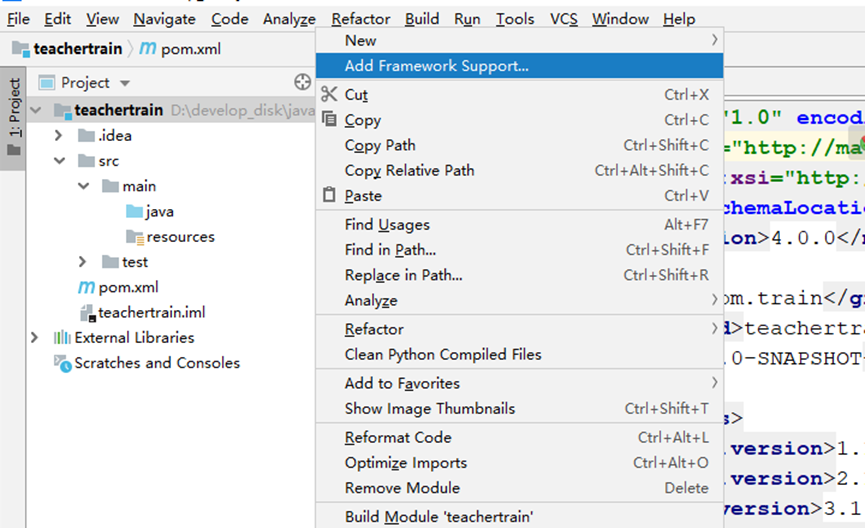
2. 项目添加scala框架支持
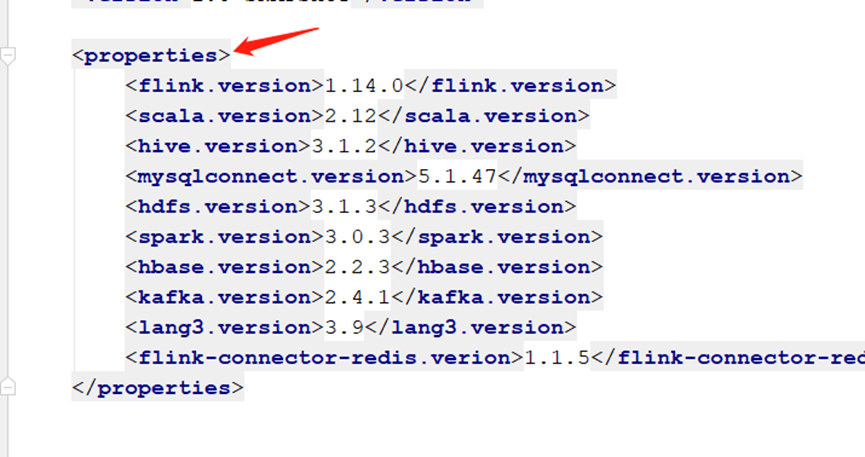
3. 修改pom.xml文件
这个是pom.xml文件
最下面的build部分要根据自己的情况来(因为可能会出现在Maven中Package后classes可能会出现两个重复的文件的情况)
不懂Mavern的话建议看一下Maven的生命周期(联想到跟自己的年龄大小一样,上面表示已经度过了,也就是说,例如下面的Package会把之前干的事情都给包含下来)Maven 构建生命周期 | 菜鸟教程 (runoob.com)
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.14.0</flink.version>
<scala.version>2.12</scala.version>
<hive.version>3.1.2</hive.version>
<mysqlconnect.version>5.1.47</mysqlconnect.version>
<hdfs.version>3.1.3</hdfs.version>
<spark.version>3.0.3</spark.version>
<hbase.version>2.2.3</hbase.version>
<kafka.version>2.4.1</kafka.version>
<lang3.version>3.9</lang3.version>
<flink-connector-redis.verion>1.1.5</flink-connector-redis.verion>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}.12</version>
</dependency>
<!--kafka-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_${scala.version}</artifactId>
<version>${kafka.version}</version>
</dependency>
<!--flink 实时处理-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop2</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</exclusion>
</exclusions>
<version>${flink-connector-redis.verion}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>${lang3.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.version}
</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--mysql连接器-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysqlconnect.version}</version>
</dependency>
<!--spark处理离线-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
</exclusion>
</exclusions>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
</exclusion>
</exclusions>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- hadoop相关-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hdfs.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>${hdfs.version}</version>
</dependency>
<!--hbase 相关-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<directory>src/main/scala</directory>
</resource>
<resource>
<directory>src/main/java</directory>
</resource>
<resource>
<directory>src/main/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<configuration>
<recompileMode>incremental</recompileMode>
</configuration>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
</plugin>
</plugins>
</build>
</project>
复制pom文件部分内容到idea中pom文件中。然后让maven下载依赖。
内容 从<properties>开始到</build>结束。
4、提供hive支持
把hive110/conf/hive-site.xml文件拷贝到resources资源包中
https://zhuanlan.zhihu.com/p/343132450
5. 导入数据库
6. 创建scala文件
D文件
object D {
def main(args: Array[String]): Unit = {
//创建sparksession对象
val conf = new SparkConf()
.setAppName("task1_modelB_task1_job1")
.setMaster("local[*]")
val ss = SparkSession.builder()
.config(conf)
//.enableHiveSupport()
.getOrCreate()
//连接mysql
val base_orders = ss.read.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", "jdbc:mysql://127.0.0.1:3307/shtd_store?user=root&password=root&useSSL=false&useUnicode=true&characterEncoding=utf8")
.option("dbtable", "ORDERS")
.load()
base_orders.createOrReplaceTempView("mysql_orders")
var sql1=ss.sql("select * from mysql_orders limit 10").show()
//
}
}
可以直接运行
E.scala文件
object E {
def main(args: Array[String]): Unit = {
//创建sparksession对象
val conf = new SparkConf()
.setAppName("task1_modelB_task1_job1")
.setMaster("local[*]")
val ss = SparkSession.builder()
.config(conf)
.enableHiveSupport()
.getOrCreate()
//连接mysql
val base_orders = ss.read.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", "jdbc:mysql://127.0.0.1:3307/shtd_store?user=root&password=root&useSSL=false&useUnicode=true&characterEncoding=utf8")
.option("dbtable", "ORDERS")
.load()
base_orders.createOrReplaceTempView("mysql_orders")
//向hive的ods.orders表插入10条记录,并存储在20221019分区中
ss.sql(
"""
|insert into table ods.orders partition(dealdate = 20221019)
|select *
|from mysql_orders limit 10
|""".stripMargin)
}
}
6. 项目打jar包
使用maven方式
第一步 compile 第二步 package
7. 将打好的jar包拷贝到linux机器上,启动spark,使用命令运行jar文件
到spark安装目录的bin目录下,cmd进入命令行,
spark-submit --class 主类名含包名 --master local jar包位置
(没用的话试试在spark前面加入 ./)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号