
threading库的使用笔记
threading库的使用
参考文章:
第一篇:一篇文章搞懂Python多线程简单实现和GIL (qq.com)
第二篇:python多线程详解 - luyuze95 - 博客园 (cnblogs.com)
第三篇:Python 多线程 start()和run()方法的区别(三) - ihoneysec - 博客园 (cnblogs.com)
第四篇:一篇文章理清Python多线程同步锁,死锁和递归锁 (qq.com)
一、线程的创建
1.1 普通使用(创建)线程的方式
import threading
import time # 之后不再重复引用
def run(n="t1",time_=1):
print("我是{}".format(n))
time.sleep(time_)
print("我是{}--过了{}秒后".format(n,time_))
if __name__ == '__main__':
t1 = threading.Thread(target=run, args=("t1",3)) # 当函数只有一个参数时,要保证唯一参数后面要加“,”,其他情况可省略
t2 = threading.Thread(target=run, args=("t2",))
t1.start()
t2.start()
threading.Thread()中,target为需要创建线程的函数,agrs为要传入函数的参数。
1.2 用继承的方式使用(创建)线程的方式
class MyThread(threading.Thread): # 继承threading.Thread类
def __init__(self): # 重写__init__方法
super(MyThread,self).__init__() # 调用父类的__init__()方法
#super().__init__() # 在python3中可以这样用,上面的是python2中的写法
#threading.Thread.__init__() #也行,看网上说这样可能会出现问题(俺也不知道咋回事儿)
def run(self): # 重构run函数必须要写,run()就相当于线程启动时的“__init__()”,在线程被start()时,run()中的代码会跟着运行
self.fun()
def fun(self): # 自定义的线程操作函数,可以定义多个,如果要运行在线程中,记得写在run()函数中呦。
print("啊哈,我是用继承的方式创建的!")
mythread = MyThread() # 创建线程
二、线程功能的使用
2.1.1 守护线程
默认情况下,主线程(产生线程的进程)将在所有非守护子线程结束后结束(主线程执行了print操作和主线程结束不是一个概念),主线程可以被称为主进程,线程是进程的执行单元
守护线程,守护的是主线程,无论守护线程是否运行完成,只要主线程结束守护线程也跟着结束,换一种说法就是:主线程只会等待非守护线程都结束后再结束,不考虑守护线程的状态。
def run(n="t1",time_=1): # 后续将不再重复定义
print("我是{}".format(n))
time.sleep(time_)
print("我是{}--过了{}秒后".format(n,time_))
if __name__ == '__main__':
t1 = threading.Thread(target=run,args=('“守护线程”',4)) #Thread是一个类,实例化产生t1对象,这里就是创建了一个线程对象t1
# t1.setDaemon(True) # 设置线程t1为守护线程
t1.start() #线程执行
t2 = threading.Thread(target=run, args=('普通线程',3)) #这里就是创建了一个线程对象t2
t2.start()
# t1.join() # 运行线程t1的join()方法
print("=========程序结束==========")
以上代码未将t1设置为守护线程,此时输出为:

将t1设置为守护线程后,输出为:
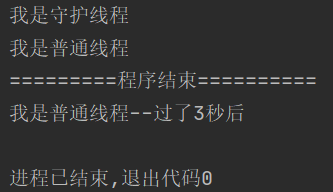
可以看到,将线程t1设置为守护线程后,主线程(进程)将不再等待t1运行完成后,再结束了。
我希望,“程序结束”这句提示是真的表示程序结束了,这时就需要join()的帮助了
2.1.2 join()
每个定义的线程(例如t1),都有一个join()方法,当这个方法被运行后,不论这个线程是不是守护线程,都将阻塞(不在继续自上而下的运行代码,而是在原处等待)主线程,直到运行join()的线程结束后才会取消对主线程的阻塞。
2.1.1中的代码中,将t1设置为守护线程后,再将倒数第二行的t1.join()取消注释,输出为:

可以明显看出,守护线程是被完整运行了的
如果将t1.join(),改为t2.join(),输出为:

现在“程序结束”这句提示是真的表示程序结束了。
2.2 线程与threading模块的部分方法
每一个线程都有join()方法的同时他们还具有以下方法:
| 方法名 | 含义 |
|---|---|
| run() | 线程开始执行,类似普通函数调用,用此种方式启动的线程和直接调用函数无异 |
| start() | 启动线程活动,正常的启动线程,如果想使用多线程,必须使用这种方法启动线程活动 |
| is_alive() | 线程是否是活动的,活动返回True,注意: 旧版本中为isAlive() |
| getName() | 返回线程名字,名字指定方式:threading.Thread(name=<自定义名称>) |
| setName() | 设置线程名,t1.setName("<自定义名称>") # 应该不用解释t1是啥吧,, |
threading模块提供的一些方法:
| 方法名 | 含义 |
|---|---|
| currentThread() | 返回当前的线程变量,方法current_thread()和其作用一致(至少现在的我感觉他俩一样),使用方式可以看我引用的第三篇文章,里面的示例代码中演示了使用方法 |
| enumerate() | 返回一个包含正在运行的线程list。只包括运行这段代码的那个时刻正在运行的线程 |
| activeCount() | 返回正在运行的线程数量,与len(threading.enumerate())结果相同 |
三、GIL(Global Interpreter Lock) 全局解释器锁
3.1 不符合直觉的结果与解决办法
GIL是为了解决多个线程同时操作公共资源时产生的不符合直觉的结果的问题而存在的
不符合直觉的结果例子:
import threading
import time
class MyThread(threading.Thread):
def __init__(self):
super(MyThread,self).__init__()
def run(self):
self.fun()
def fun(self):
global a
a1 = a
time.sleep(0.01) # 此处等待0.01s是为了让其他线程也进行‘a1 = a’操作
a = a1 + 1 # 之所以不用 a +=1,是因为这种情况下a是直接从全局变量中取值后进行计算的,这个速度会很快,很难达到让两个线程中的a同时取到相同的值,因此用a1对a的值进行临时存储,在其sleep()的时间中,其他线程中的a1将会取到相同的值
a = 0
thread_list = []
for i in range(100):
my_thread = MyThread()
my_thread.start()
thread_list.append(my_thread)
for i in thread_list:
i.join() # 执行全部线程的join()方法,否则最后的print()表示的将不是全部线程运行完后,a的结果
print("a的值为:{}".format(a))# 这是主线程的部分,如果不执行全部线程的join()方法,此句将在全部线程创建完成后就开始打印,此时线程们还没有完成对a的处理,所以打印出的结果不正确。
在上面的例子中,我创建了100个线程,每个线程做的事情都是将全局变量a加一后返回,从代码上看,结果理所应当是“a的值为:100”,但实际上的结果为:

产生这种情况的原因就是某个时刻a的值同时被多个线程进行访问,比如有两个线程取到的a值都为1,那么这两个线程结束后,返回的a值均为2(实际上经过两次加1,结果应该为3),这就造成了不符合直觉的结果。
使用GIL即可解决这种问题,在 线程1 对a进行处理时,我们将 线程n(其他线程) 对a的处理暂停,直到 线程1 对a的处理完成后,线程n(其他线程) 再继续。
没错,GIL将多线程变成了单线程,但这种多线程并不是没有意义的,每个线程只有在访问共享资源的时候才会用到GIL进行“单线程“处理,其他逻辑都是可以继续多线程的。因为GIL是会影响性能的,所以在什么地方加GIL也是一门学问。
GIL在threading库中有两种,一种是Lock(),另一种是RLock()
3.1.1 Lock() 同步锁(我管它就叫 锁)
lock = threading.Lock() # 创建锁
lock.acquire() # 上锁
lock.release() # 解锁(释放)
当一个锁被 线程1 上锁后,线程n(其他线程) 中的‘lock.acquire()'将会等待 线程1 中的锁被解锁(释放)后,再继续运行。
用此类锁解决不符合直觉的结果的问题:
import threading
import time
class MyThread(threading.Thread):
def __init__(self):
super(MyThread,self).__init__()
def run(self):
self.fun()
def fun(self):
global a
lock.acquire() # 上锁
a1 = a
time.sleep(0.01) # 此处等待0.01s是为了让其他线程也进行‘a1 = a’操作
a = a1 + 1
lock.release() # 解锁(释放)
a = 0
lock = threading.Lock() # 创建同步锁
thread_list = [] # 用于存储全部的线程对象
for i in range(100):
my_thread = MyThread()
my_thread.start()
thread_list.append(my_thread)
for i in thread_list:
i.join() # 执行全部线程的join()方法,否则最后的print()表示的将不是全部线程运行完后,a的结果
print("a的值为:{}".format(a))# 这是主线程的部分,如果不执行全部线程的join()方法,此句将在全部线程创建完成后就开始打印,此时线程们还没有完成对a的处理,所以打印出的结果不正确。
此时,a的结果满足预期(直觉)

此处我曾有个疑问:上锁是给什么上锁,锁锁住了什么呢?
我现在给自己的答案是:锁住的是后续的操作(代码),不是某个变量或资源。在调用某个公共资源的代码前,加入一个同名的锁,当一个线程中的锁被锁住之后,其他线程运行到“上锁”的步骤时,就会等待其他线程的锁“释放”后才会继续后面的操作,进而达到了“锁住公共资源”的目的。如果我们希望某段代码在其他操作完成之后再继续,我们也可以在那段代码前加入锁,这时锁住的就不止是 公共资源 了。
上面的例子中,我们只定义了一个锁,实际上锁的数量是没有限制的,同时“每把锁都可以锁住不同的门”
单独的一个锁,可以称为 “同步锁”,与之对应的还有“死锁”,“递归锁”,想要了解这些,建议直接看我的参考文章第四篇。
首先“同步锁”就是普通的锁,“死锁”出现是因为“同步锁”的嵌套使用,是一种情况。“递归锁”是为了解决“死锁”情况而独立出来的一种锁,是一个功能,不是情况。
3.1.2 RLock() 递归锁(啊,这个我也管它叫 递归锁【狗头】)
额,解释看我参考的第四篇文章吧,不是很明白这个锁的应用场景,文章中举例完全可以用一个互斥锁达到目的,搜索了其他的演示递归锁的例子,我发现也都可以用互斥锁解决例子中的问题,使用递归锁完全就是多输入了几遍acquire()和release()。
所以我并不理解递归锁存在的意义,求教!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号