Self-Attention
前言必读:
参考:https://www.cnblogs.com/dogecheng/p/11614843.html
参考2:https://zhuanlan.zhihu.com/p/48508221
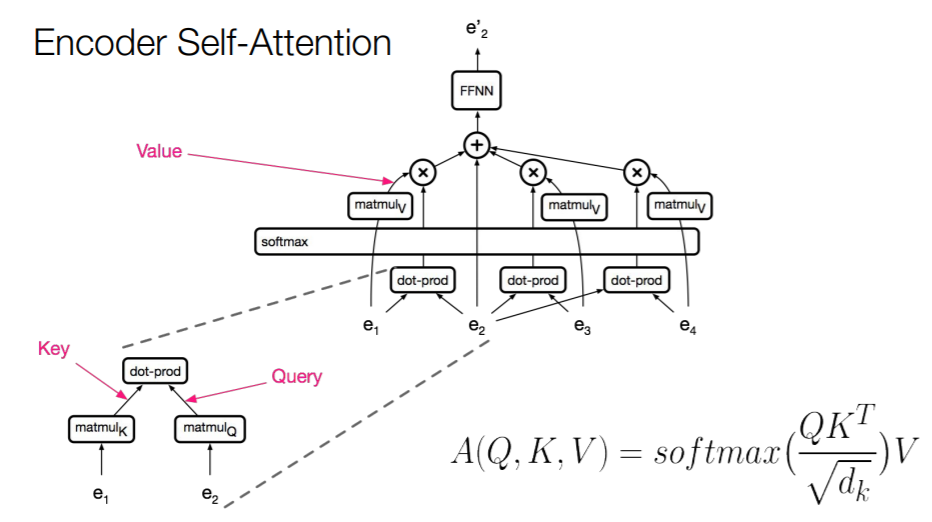
- 为什么要对 \(a_i\) 进行线性变换到 \(q_i\) 、 \(k_i\) 和 \(v_i\) ?
- 进行线性变换到 \(q_i\) 和 \(k_i\) ,相当于将向量投影到一个其他空间,在那个空间中,dot-product可以很好的代表相似度(similarity)。
- \(Attention(Q,K,V)=softmax({QK^T\over \sqrt{dk}})V\) 中,为什么要除以 \(\sqrt{dk}\)?注,\(d_k\) 是k的维度(知乎那篇文章里就是64)
- 确保dot-product不会膨胀,是一个scale factor。
- 为什么可以self-attention如此有吸引力?(可以并行化)
- 可以通过使用GPU,同时对所有位置(all positions)计算这两个乘法和一个softmax。
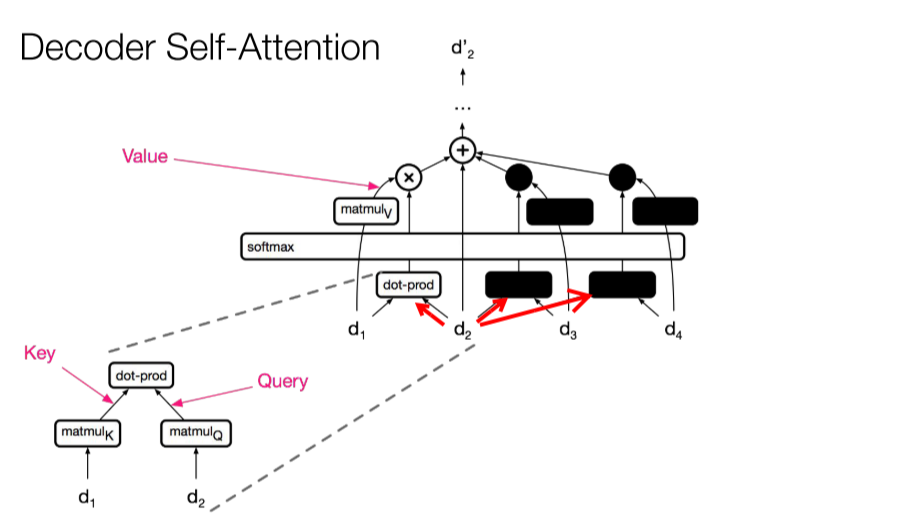
- decoder 中的 masking?
- masking, masking 的作用就是防止在训练的时候使用未来的输出的单词。 比如训练时,第一个单词是不能参考第二个单词的生成结果的。 Masking就会把这个信息变成0, 用来保证预测位置 i 的信息只能参考比 i 小的输出。
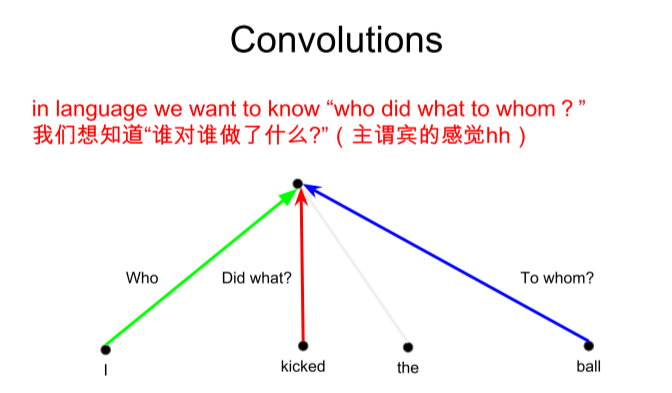
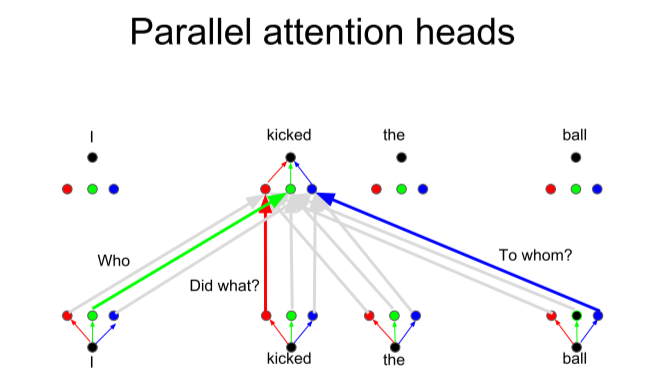
- 为什么提出 Multi-Head Attention?
- 因为如果是convolutional sequence model可以通过不同的filter,来学习不同的"feature",比如下图1中关于一个sentence中的“who”、“did what”、“to whom”。(Different linear transformations by relative position)
- 但是对于self-attention,我们使用的combination,相当于对于所有位置应用了一样的线性变换(对于所有位置 \(a_i\) 都是应用了三种相同的线性变换到 \(q_i\) 、 \(k_i\) 和 \(v_i\),一样的 \(W_q\)、\(W_k\) 和 \(W_v\)),可以把一个attention layer看作某种feature detector,我们如果想学习多个“feature”,就需要多个heads(下图右,就是3-heads,分别用三组 \(W_q\)、\(W_k\) 和 \(W_v\) 进行了3次投影线性变换),每一个head就是a function of positions,以此来模拟convolution卷积。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号