因果推理综述——《A Survey on Causal Inference》一文的总结和梳理
因果推理
本文档是对《A Survey on Causal Inference》一文的总结和梳理。
简介
关联与因果
先有的鸡,还是先有的蛋?这里研究的是因果关系,因果关系与普通的关联有所区别。不能仅仅根据观察到的两个变量之间的关联或关联来合理推断两个变量之间的因果关系。

对于两个相互关联的事件A和B,可能存在的关系
- A造成B
- B造成A
- A和B是共同原因的结果,但不互相引起。
- 其他
用一个简单的例子来说明关联关系和因果关系之间的区别:
随着冰淇淋销量的增加,溺水死亡的比率急剧上升。如果根据关联关系来判断,冰淇淋的畅销会导致溺水的多发。显然,这种结论非常荒谬,根据我们的常识来判断,溺水事件的多发是因为气温升高(游泳的人数激增)带来的影响,而冰淇凌的销量的增加也是因为天气炎热,所以在这里,气温是冰淇凌销量和溺水事件数目的共同原因,实际上冰淇凌和溺水并无直接的因果关系。
事实上,相关性是对称的(双向箭头),而因果关系是不对称的(单向箭头)
因果关系
Pearl在《The Book of Why: The New Science of Cause and Effect》一书中将因果关系分为三个层次(他称之为“因果关系之梯”)。自底到顶分别是:关联、干预、反事实推理。最底层的是关联(Association),也就是我们通常意义下所认识的深度学习在做的事情,通过观察到的数据找出变量之间的关联性。这无法得出事件互相影响的方向,只知道两者相关,比如我们知道事件A发生时,事件B也发生,但我们并不能挖掘出,是不是因为事件A的发生导致了事件B的发生。第二层级是干预(Intervention),也就是我们希望知道,当我们改变事件A时,事件B是否会跟着随之改变。最高层级是反事实(Conterfactuals),也可以理解为“执果索因”,也就是我们希望知道,如果我们想让事件B发生某种变化时,我们能否通过改变事件A来实现。

研究因果关系最大的一个目标,就是找出事物之间真正的因果关系,去掉那些混杂的伪因果关系。
因果推理
简介
因果推理是根据一个结果发生的条件对因果关系得出结论的过程。
几十年来,因果推理的研究涉及到了统计学、计算机科学、教育、公共政策和经济学等多个领域的重要研究课题。
研究方法
存在两种研究方法
- 实验性研究 —— 需要做大量随机对照试验,实验中的控制变量也是随机指定的,但这么做往往会涉及到伦理的问题。例如,当我们要研究吸烟对肺部健康的影响时,我们不可能要求原本都不吸烟的一群人中的一部分人去吸烟已到达实验目的,这是不现实且反道德及伦理的。此外,进行大量的随机对照试验代价昂贵且费时费力。
- 观测性研究 —— 从已有的能观测到的数据中进行因果关系的研究。主要方法有因果图模型和潜在结果框架。观测性研究的好处在于,简单高效且易于理解。
基本概念
模型与框架
因果图模型
因果图是基于DAG(有向无环图)构建的,它是一种概率因果模型,被用来编码有关数据生成过程的假设。
有向无环图拥有非常丰富的内涵。我们可以通过这种图的形式洞悉变量之间的相互独立关系或者条件独立关系。
结构因果模型(SCM)
因果定义
研究 \(X\) 和 \(Y\) 的因果关系
-
直接原因: \(Y=f(x)\) 或 \(Y=f(x,z,\cdots)\)
\(X \rightarrow Y\) 或 \(X \rightarrow Y \leftarrow Z\)
-
间接原因: \(Y=f(g(x))\)
\(X \rightarrow Z \rightarrow Y\)
结构化因果模型包含两类变量以及函数集合
- 外生变量 —— 对应DAG图的结点,没有祖先
- 内生变量 —— 对应DAG图的节点,至少是一个外生变量的后代
- 函数集合 —— 对应DAG图的边集合,每条边代表了一个变量之间的函数关系

上图的DAG图就对应一个结构因果模型:
集合 \(U=\left \{X,W \right \}\) 为外生变量集合,集合 \(V=\left \{ Z,Y \right \}\) 为内生变量集合,集合 \(F=\left \{ f,g \right \}\) 为函数集合
潜在结果模型
潜在结果模型的主要贡献者是哈佛大学著名统计学家唐纳德·鲁宾(Donald B.Rubin),因此该模型又被称为鲁宾因果模型(Rubin Causal Model)。其核心是比较同一个研究对象(Unit)在接受干预(Treatment)和不接受干预(对照/控制组)时结果差异,认为这一结果差异就是接受干预相对于不接受干预的效果。
对于同一研究对象而言,通常我们不能够既观察其干预的结果,又观察其不干预的结果。对于接受干预的研究对象而言,不接受干预时的状态是一种“反事实”状态;对于不接受干预的研究对象而言,接受干预时的状态也是一种“反事实”状态;所以该模型又被某些研究者称之为反事实框架(Counter factual Framework)。
基本概念
-
Unit —— 单元,原子研究对象
-
Treatment —— 干预/治疗,施加给一个原子对象unit的行为。在二元Treatment的情况下(即$ W=0 $ 或 \(1\) ),Treatment组包含接受Treatment为 \(W=1\) 的unit,而对照组包含接受Treatment为 $ W=0 $ 的unit。
-
Outcome —— 结果,在对unit进行Treatment或者仅仅作为对照之后unit随后产生的反应/结果,一般用 \(Y\) 表示
-
Treatment Effect —— 因果效应,对unit进行不同Treatment之后unit产生的Outcome的变化,这种效应可以定义在整体层面、treatment组层面、子组层面和个体层面
-
整体层面 —— Average Treatment Effect(ATE),平均干预效果
$$ ATE = E[Y(W = 1) - Y(W = 0)] $$
-
Treatment组层面 —— Average Treatment Effect on the Treated Group (ATT),Treatment组中的平均干预效果
\[ATE=E[Y(W=1) \mid W=1]-E[Y(W=0) \mid W=1] \] -
子组层面 —— Conditional Average Treatment Effect (CATE)
\[CATE=E[Y(W=1) \mid X=x] - E[Y(W=0) \mid X=x] \] -
个体层面 —— Individual Treatment Effect (ITE)
$$ ITE_{i} = Y_{i}(W=1) - Y_{i}(W=0) $$
-
-
Potential Outcome —— 潜在结果,对于每对unit-treatment,当对unit施加相应的treatment之后产生的结果
-
Observed Outcome —— 观测结果,已经发生的事实,对unit施加某个treatment之后产生的能观测到的结果
-
Counterfactual Outcome —— 反事实结果, 已经发生事实的其他对立面,也即对某个unit未采用的其他treatment带来的潜在结果
典型研究案例
任务:利用观察数据,如电子健康记录(EHR),评估几种不同药物对一种疾病的治疗效果
观测数据:
- 患者的人口统计信息
- 患者服用特定剂量的特定药物
- 医学测试结果
- 其他
研究对象:病人
干预:不同药物
结果:恢复/血样测试结果/其他
三个重要假设
-
稳定单位干预值假设(Stable Unit Treatment Value Assumption)
任何一个单元的潜在结果不会因分配给其他单元的treatment而有所不同,并且对于每个单元,每个treatment级别没有不同的形式或版本,不会导致不同的潜在结果。
这个假设强调以下几点:
- unit之间都是相互独立的,unit之间不会存在相互作用
- 同一treatment仅能存在一个版本。例如,在该假设下,不同剂量的同一种药物代表不同的治疗方法
-
可忽略性假设(Ignorability)
给定背景变量 \(X\) , 干预分配 \(W\) 与潜在的结果无关
例如,由上文的药物治疗的例子来看,如果两个患者有相同的背景变量 \(X\) ,无论治疗任务是什么,他们的潜在结果应该是相同的
类似地,如果两个患者具有相同的背景变量值,那么他们的治疗分配机制应该是相同的,无论他们有什么潜在的结果
-
正值假设(Positivity)
对于X的任何一组值,处理分配不是确定的:
\[P(W=w \mid X=x) > 0 \]如果某些X值的治疗分配是确定的,那么至少一种治疗的结果永远无法观察到。那么估计因果关系是不可能也没有意义的,这意味着干预组和对照组的“共同支持”或“重叠”。忽略性和积极性假设一起也被称为强可忽略性或强可忽略性治疗任务
一般的研究方法
核心问题:如何估计特定人群的平均潜在治疗/控制结果?
想当然的解决方案: 计算平均治疗和对照结果之间的差异,即ATE
存在的问题:由于混杂因素(confounders)的存在,这种解决方案是不合理的
混杂因素
混杂因素(Condounders)是同时影响干预分配和最终结果的变量
举例说明
在下图中,展示的是两种治疗方案对年轻/年老两种病人群体的治疗效果

从表格中我们显然可以看出,抛开年龄我们从整体上来看,不难得出结论:A治疗方案更好;但是考虑年龄的话,无论在是年轻的病患群体中还是年老的病患群体中,B方案的治愈率明显更高,由此得到结论:B治疗方案更好。这两种结论显然是互相矛盾的,但是为什么考虑年龄之后,会得出截然相反的结论呢?
实际上,这是一种名为辛普森悖论的现象。辛普森悖论指的是同一组数据,整体的趋势和分组后的趋势完全不同。也就是说,整体数据和分组数据产生的结论截然相反。
辛普森悖论的解释:
在上面的例子中,数据分组的指标是年龄,而年龄同时影响着恢复率和治疗方案的选择。从恢复率数据来看,无论是哪种治疗方案下,年轻组的恢复率普遍比年老组高得多,而从治疗方案的选择来看,年轻组更倾向于选择A治疗方案,而年老组则更倾向于选择B治疗方案。正是这种共同影响的存在,使得整体结果和分组结果完全不同。
在这个例子中,干预分配显然就是治疗方案的选择,最终结果就是治愈率,显然可以得知,年龄在这里就是混杂因子。混杂因子的存在导致辛普森悖论现象的产生,因此,在混杂因素存在的情况下,我们不能针对观测数据轻易下结论。
选择偏倚
混杂因子的存在影响着干预分配的选择,treatment组和对照组的分布有可能不一致,因此导致出现偏差,这也使得反事实结果估计更加困难。
因果推理方法
- Re-weighting(重加权算法)
- Stratification(分层算法)
- Matching(匹配算法)
- Tree-based(基于树的方法)
- Representation Learning(表示学习)
- Multitask Learning(多任务学习)
- Meta-learning(元学习)
重加权算法
思想
干预组和对照组观测数据的分布不同,这就是选择偏倚带来的挑战。为了克服选择偏倚,可以考虑对样本进行重新加权。
通过给观察数据集中的每个样本分配适当的权重,可以创建一个伪总体,使得干预组和对照组的分布相似。然后根据重加权后因果效应的评估。

上图展示了重加权的过程,当存在年龄Age这个混杂因子时,选择偏倚使得干预组和对照组的分布存在一定差异,对样本重新分配权重后(右图加粗部分,可以认为是增加了权重),使得干预组和对照组的分布相似,从而消除了混杂因子Age带来的选择偏倚。
倾向分数
它是给定观测协变量向量的特定干预分配的条件概率,反映出样本x选择treatment的可能性。
$$e(x)=Pr(W=1 \mid X=x)$$
反向倾向加权(IPW)
给每个unit指定的权重为:
$$ r = \frac {W} {e(x)} + \frac {1-W} {1-e(x)}$$
其中 \(W\) 是treatment, \(e(x)\) 是倾向得分。重加权后在整体层面对平均干预效果进行估计:
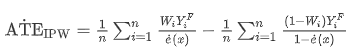
理论结果表明,调整倾向得分足以消除由于所有观测到的协变量而产生的偏差。但是这种加权方法高度依赖倾向性得分的正确性。
双保险估计/增广IPW
它将基于倾向得分加权的重加权算法和结果回归相结合
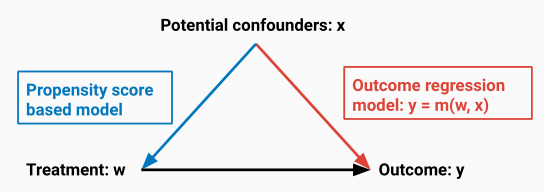
当倾向性得分或者结果回归中只要有一个是正确的,就能做到无偏估计。
协变量平衡倾向得分(CBPS)
倾向性得分既可作为干预分配的概率,又可作为协变量平衡得分,CBPS利用了这一双重特征,通过解决下面这一问题来估计倾向性得分:

数据驱动变量分解(\(D^{2}VD\))
假设:观测变量可以分解为混杂变量、调整变量和无关变量
目的:区分混杂变量和调整变量,同时剔除无关变量。

重加权算法总结

分层算法
通过将整个组分成子组来调整选择偏差,在每个子组中,treatment组和对照组在某些测量值下是相似的,干预效果的估计结果是所有子组的加权平均。

利用分层算法估计的平均干预效果:

匹配算法
干预评估
匹配算法使用下面的公式来估计后果
\(\hat{Y}_{i}(0)\) 代表对照组,\(\hat{Y}_{i}(1)\) 表示实验组。\(\mathcal{J}(i)\) 代表在相反的treatment组中和单位 \(i\) 距离最近的样本。
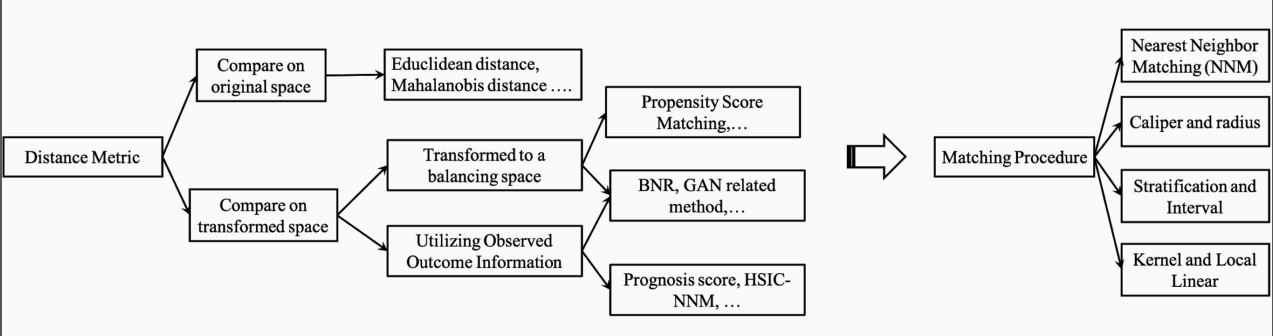
样本距离度量方法
- 欧氏距离
- 马氏距离
样本空间
- 原始空间
- 特征变换空间
- 基于倾向得分的转换空间
- 其他转换空间
基于倾向得分的匹配
基于倾向得分
定义两个units之间的距离
匹配算法
- 邻近算法
- Caliper算法
- 分层算法
- 核函数
匹配算法总结
其他算法
此外还有基于树的方法、表示学习、多任务学习、元学习,这里就不展开了。
实验指导
这一章节介绍当前研究可用的数据集、开源代码及研究框架。
数据集
由于反事实的结果永远无法被观察到,因此很难找到一个完全满足实验要求的数据集,即具有基本真实数据集 (ITE) 的观测数据集。
现在很多研究中使用到的数据集基本上都是半人工合成的数据集,合成的规则不尽相同,如IHDP数据集,是从随机数据集中按照一定的生成过程生成其观测结果,并去除一个有偏子集来模拟观测数据集中的选择偏差。一些数据集,如Jobs数据集,将随机数据集和观察控制数据集结合起来,产生选择偏差。
目前可用基准数据集
- IHDP
- Jobs
- Twins
- ACIC dataset
- IBM causal inference benchmark
- BlogCatalog
- Flickr
- News
- MVICU
- TCGA
- Saccharomyces cerevisiae (yeast) cell cycle gene expression dataset
- THE
- FERTIL2
代码
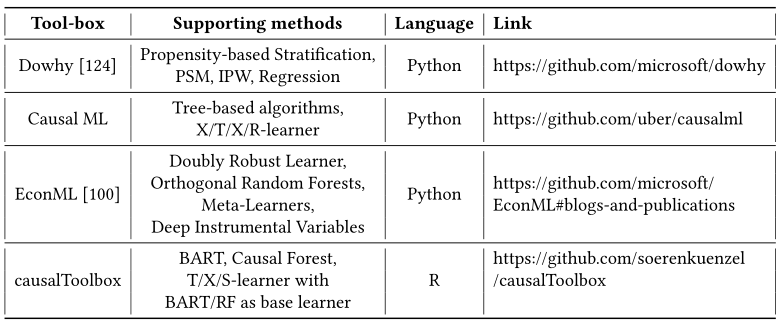
开源的研究框架(工具箱)
- Dowhy —— 微软研发,基于Python
- Causal ML —— Uber研发,基于Python
- EconML —— 微软研发,基于Python
- causalToolbox —— 基于R语言
开源因果推理方法
基于Python语言
- PSM1/PSM2
- Perfect Match
- CMGP
- BART
- GANITE
- BNN/CFR
- CEVAE
- SITE
- dragonet
- DRNets
- Network Decondounder
- Network Embeddings
- LCVA
基于R语言
- IPW
- DR
- Principal Stratification
- Stratification
- Matching based
- optimal matching
- CEM
- TMLE1/TMLE2
- BART
- grf
- R-learning
- Residual Balancing
- CBPS
- Entropy Balancing
应用
因果推理的应用可以分为三个方向
- 决策评估 —— 这与Treatment效果评估的目标是一致的。
- 反事实估计 —— 反事实学习极大地帮助了与决策相关的领域,因为它可以提供不同决策选择(或策略)的潜在结果。
- 处理选择偏差 —— 在许多实际应用程序中,出现在收集的数据集中的记录并不代表感兴趣的整个群体。如果不恰当地处理选择偏差,将影响训练模型的泛化。
下面是这三个方向适用的应用场景:

广告
决策评估
正确衡量广告活动的效果是品牌方成功营销的关键,如新广告是否增加点击量,或新广告是否增加销售额等。
衡量方法
-
随机试验 —— 成本高且耗时,不应采纳
-
从观察数据中估计广告效果
-
随机最近邻匹配法 —— 估计数字营销活动的治疗效果
-
协变量平衡广义倾向得分(CBGPS)—— 用于分析政治广告的有效性
-
处理选择偏差
由于广告系统中现有的选择机制,显示和未显示的事件之间存在分布差异。忽视这种偏差会使广告点击预测不准确,从而造成收入损失。
电子邮件营销
决策评估
目的:瞄准潜在客户,增加收入。
使用决策评估帮助在不同的促销电子邮件设计中进行选择。
推荐系统
决策评估
在推荐系统中给用户推送商品的过程,相当于给原子研究对象施加干预,通过用户的点击、消费等行为评估干预(推荐)的效果。
系统的推荐建议与评估的干预效果高度相关。

处理选择偏差
推荐系统中使用的数据集通常由于用户的自我选择而产生偏差。
例如,在电影收视率数据集中,用户倾向于对自己喜欢的电影进行评分:恐怖电影的收视率大多由恐怖电影迷制作,而浪漫电影的影迷则较少。
对于广告推荐,推荐系统只会将广告推荐给系统认为对这些广告感兴趣的用户。
在上面的例子中,数据集中的记录并不代表整个群体,这就是选择偏差。这种选择偏差给推荐模型的训练和评价带来了挑战。基于倾向得分的样本再加权是解决选择偏差问题的有效方法。
药物治疗
反事实估计
当可以估计不同的可用药物的疗效时,医生可以据此开出更好的处方。
教育
反事实估计
通过比较不同教学方法对学生群体的影响,可以确定一种更好的教学方法。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号