


第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
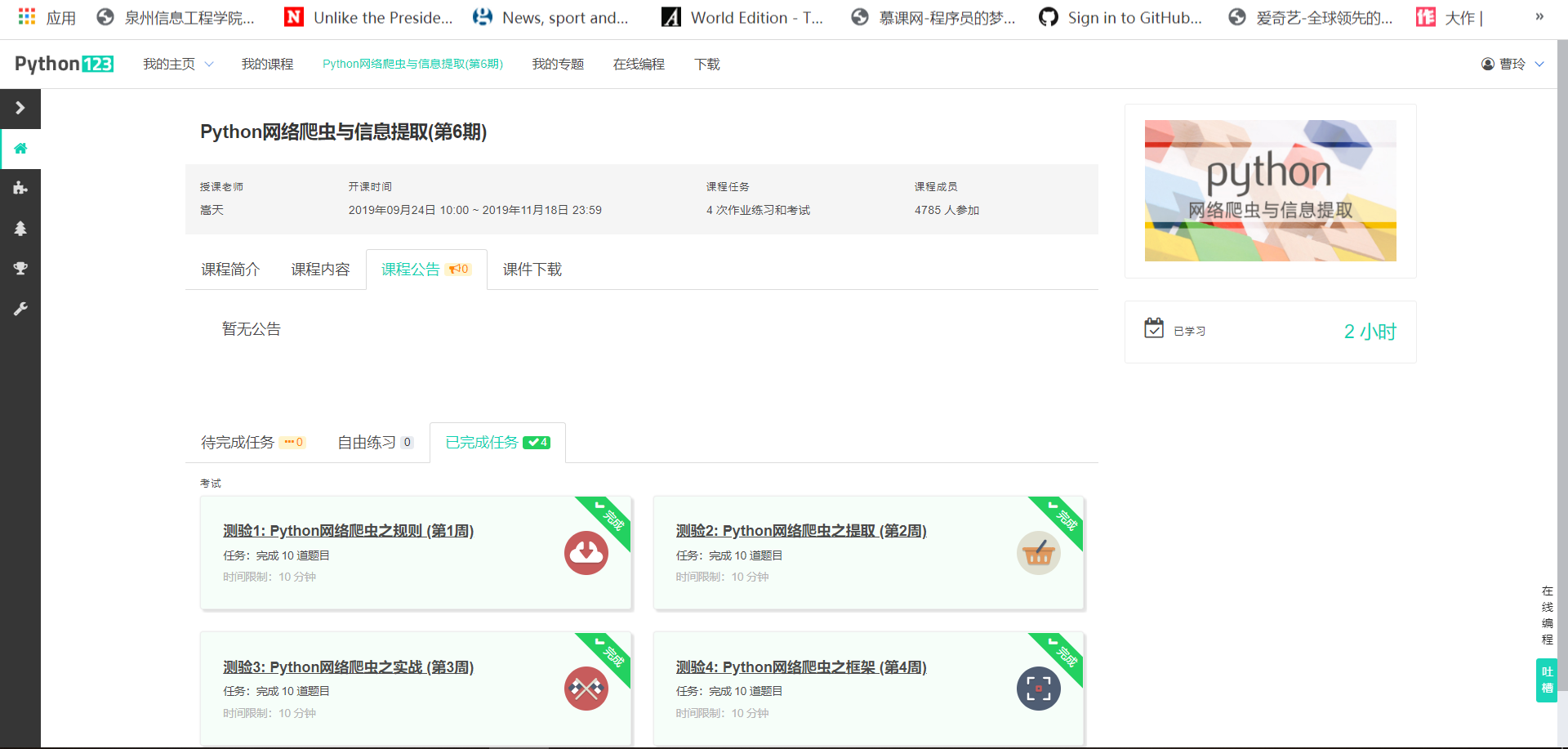
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
在未接触爬虫之前,听着爬虫感觉是很厉害的样子,学完python网络爬中与信息提取后,爬虫在我面前的神秘面纱就被揭开了,让我从一个爬虫的新手到最后写了自己的爬虫,感觉很好。所谓工欲善其事,必先利其器,选着一个适合自己的IDE,会让自己的开发效率事半功倍,我本人使用pycharm做为我的IDE,因为它debugger确实好,特别对于爬虫来说,在运行之前,先对程序进行一个debugger确定提取到的每个值是否有误,都能通过debugger方式排查出来。也可让我们尽可能的减少网络请求的次数。
这门课程有浅到深,先介绍了爬虫是什么,以及它能做什么,让我们先有个基本概念,在明白了爬虫是从网页上爬取数据下来后,使用了在爬虫开发中非常热门的一个库:requests,它主要的目的就是发起一个网络请求,然后通过text返回目标网页中信息,当然有爬虫,自然也就有反爬,因为对于有些网站,它不允许爬虫去爬取它的信息,其实爬虫对应有一个roboot协议,即哪些数据是允许爬虫爬取的,哪些是不允许爬取的,其实遵不遵守还是在于个人,既然我们是爬取数据,那么我们怎么知道数据爬取成功了呢,requets提供了statu_code,即状态码,当返回的是200时说明数据爬取成功,我们就可以开始提取到我们所需要的数据了,那么提取数据的库也就来了,我们学习了BeautifulSoup,让我们能从返回的网页信息中,提取出我们想要的数据,BeatifulSoup提供了很多的方式对于数据的提取,比较常用的就是find和find_all方法,前者只返回匹配到数据的第一项,后者则返回匹配到的所有项,通过两个方法中对应传递的参数来提取到满足条件的数据,通过实例中国大学排名,结合了requests和BeautifulSoup的使用,进一步加深了对这两个库的使用。第三周学习了正则表达式,是用来简介表达一组字符串的表达式,提供了六种形式来满足我们在不同场景下的应用。通过淘宝商品的定向爬取的案例,对正则表达式的应用有了进一步的了解,也知道了re在爬取到数据后,在对数据做进一步加工时非常重要,因此学会正则表达式就变得尤为重要了。通过一个小的综合案例股票的信息的定向爬取结合了全面所学的requests库,BeatifulSoup库,re,让我更是了解到三者的关系缺一不可,因为想要获取数据,就等发起网络请求,想提取某个特殊字段的信息,就得使用BeautifulSoup,想要进一步的精炼数据,re必不可少。
在课程的最后,我们通过学习了爬虫非常流行的框架,Scrapy,通过老师简单的介绍知道了Scrapy的5+2结构,需要用户编写的模块是spider和item Pipelines,当需要对请求进行特殊处理时,可以使用Downloader进行中间件的拦截请求,最后老师还是在原有股票的分析的基础上,用Scrapy进行了重写。
通过老师讲解Scrapy框架,让我理解到框架是一个集合,分工明确,如在spider只进行数据的提取,可在item中对数据进行进一步的加工,在itemPipelines中对数据进行持久化的操作,例如老师案例中将数据保存在文件中,当然也可以保存到数据库中,总之,有待学的东西还很多,老师的讲解带我入了门。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号