

Hadoop——HDFS异构存储&HBase冷热分离
前言
总体上HDFS异构存储的价值在于,根据数据热度采用不同策略从而提升集群整体资源使用效率。
对于频繁访问的数据,将其全部或部分保存在更高访问性能的存储介质(内存或SSD)上,提升其读写性能;
对于几乎不会访问的数据,保存在归档存储介质上,降低其存储成本。
但是HDFS异构存储的配置需要用户对目录指定相应的策略,即用户需要预先知道每个目录下的文件的访问热度(事先划分好冷热数据存储目录,设置好对应的Storage Policy,
然后后续相应的程序在对应分类目录下写数据,自动继承父目录的存储策略),在实际大数据平台的应用中,这是比较困难的一点。
一、异构存储是什么
所谓的异构存储就是将不同需求或者冷热的数据存储到不同的介质中去,实现既能兼顾性能又能兼顾成本。对于存储到HDFS的数据大致可以分下图的4个等级。
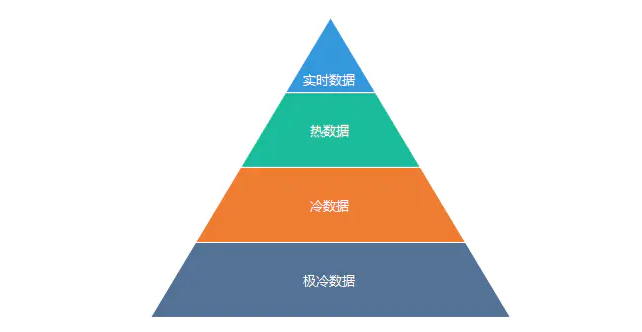
如果将这部分数据存储通过高压缩比,并且存储到普通的SATA大容量盘中去,能极大地节约成本。
对于热数据和实时数据,写请求比较高,读请求也很高,但是数据量很小。这个时候为了实现高并发低延迟,我们可以将这部分数据保存到SSD中。
Hadoop从2.6.0版本开始支持异构存储,HBase也从1.1.0开始支持将WAL的异构存储策略。
备注:这里面的难点是要对业务访问模式有足够的了解,提前确认好各个目录下的数据访问热度,以便规划好数据的存储策略。
二、HDFS异构存储类型和策略
存储类型
HDFS异构存储支持如下4种类型,分别是:
- RAM_DISK
- SSD
- DISK
- ARCHIVE
/data1/hbase/hdfs,/data2/hbase/hdfs,/data3/hbase/hdfs,/data4/hbase/hdfs,/data5/hbase/hdfs,/data6/hbase/hdfs,
/data7/hbase/hdfs,/data8/hbase/hdfs,/data9/hbase/hdfs,/data10/hbase/hdfs,/data11/hbase/hdfs,/data12/hbase/hdfs,
[SSD]/wal_data
这里前面12个盘都没有指定存储类型,则默认是DISK存储,而第13快盘指定了SSD存储类型。
这4种存储类型,按照RAM_DISK->SSD->DISK->ARCHIVE,速度由快到慢,单位存储成本由高到低。
存储策略
HDFS存储策略设置如下表:
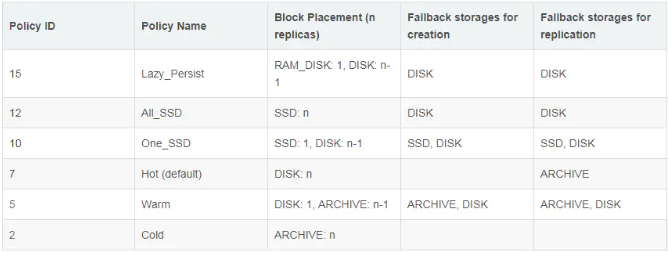
由上图,我们可以看出HDFS总共支持Lazy_Persist、All_SSD、One_SSD、Hot、Warm和Cold等6种存储策略,默认策略为Hot。
上图中的第三列是表示存储策略对应的存储类型,具体如下:
- Lazy_Persist : 1份数据存储在[RAM_DISK]即内存中,其他副本存储在DISK中
- All_SSD:全部数据都存储在SSD中
- One_SSD:一份数据存储在SSD中,其他副本存储在DISK中
- Hot:全部数据存储在DISK中
- Warm:一份数据存储在DISK中,其他数据存储方式为ARCHIVE
- Cold:全部数据以ARCHIVE的方式保存
上图中的第4、5列表示创建和写副本的时候,如果该存储策略对应的资源不足,比如磁盘不可用或者空间写满,则创建文件和同步副本的时候选择第4和第5列对应的存储类型,你可以理解为降级机制。
三、HDFS异构存储原理
对于HDFS异构存储的原理大致概括如下图所示:
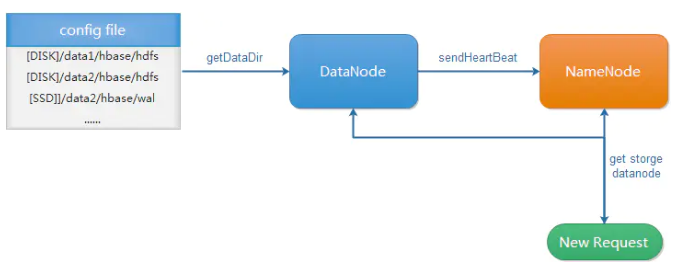
这里的原理简单概括如下:
1、在hdfs的配置文件hdfs-site.xml中配置对应的异构存储(后面配置部分有详细介绍)
2、DataNode启动的时候从配置文件中读取对应的存储类型,以及容量情况,并通过心跳的形式不断的上报给NameNode。
3、NameNode收到DataNode发送的关于存储类型、容量等内容的心跳包后,会进行处理,更新存储的相关内容。
4、写请求发到NameNode后,NameNode根据写请求具体的目录对应的存储策略选择对应的存储类型的DataNode进行写入操作。
备注:上面是根据自己的理解简单概括的大致调用过程,如果需要了解更详细的调用关系,可以阅读这篇文章,写得很详细:https://blog.csdn.net/androidlushangderen/article/details/51105876
四、HDFS异构存储的配置和策略设置
HDFS异构存的配置
每个磁盘单独挂载到不同目录,需要注意加上 noatime 选项。 首先配置 DataNode 的数据目录,只需要将对应的类型添加到dfs.datanode.data.dir的配置项中即可,
备注:也需要配置dfs.storage.policy.enabled为true,因为默认就是true,所以这里忽略。
配置的时候需要申明存储类型和对应的目录,存储类型需要用中括号括起来,存储类型有[SSD]/[DISK]/[ARCHIVE]/[RAM_DISK],如果不指定存储类型,则默认就是DISK。
比如我的机器中只配置了DISK和SSD的类型,范例如下:

通过上面的例子,前面12个盘,我没有设置存储类型,因为都是DISK,最后一个盘使用了SSD类型。
HDFS异构存储策略设置
HDFS提供了专门的命令来设置对应的策略,命令使用方法如下:
查看策略帮助信息:
hdfs storagepolicies -help
列出当前版本支持的存储策略:
hdfs storagepolicies -listPolicies
设置对应路径的策略:
hdfs storagepolicies -setStoragePolicy -path -policy
范例:
# 设置/hbase/data/default为Hot的策略
hdfs storagepolicies -setStoragePolicy -path /hbase/data/default -policy Hot
# 取消策略
hdfs storagepolicies -unsetStoragePolicy -path
# 获取对应路径的策略
hdfs storagepolicies -getStoragePolicy -path
五、HDFS异构存储的管理
对于HDFS异构存储的管理,主要包含如下两个方面:
1、统计线上数据的访问频率,确认冷热数据所在目录,灰度进行调整
2、使用hdfs storagepolicies相关命令进行策略的调整
3、修改存储策略以后,使用mover工具进行数据的迁移,mover的使用方法如下:
hdfs mover [-p files/dirs | -f localfile ]
可以使用-p指定要迁移的目录,也可以将要迁移的文件列表写入文件中,用-f参数指定对应的文件或者目录进行迁移。
六、Move迁移数据
Mover 是 HDFS 的一个数据迁移工具,类似 Balancer. 区别在于,Mover 的目的是把数据块按照存储策略迁移,Balancer 是在不同 DataNode 直接进行平衡。
如果 DataNode 挂载了多种存储类型,Mover 优先尝试在本地迁移,避免网络 IO.
使用方式: hdfs mover -p <path>,如果想一次性迁移所有数据,可把 path 指定为根路径,不过需要的时间也更长。
七、HDFS 社区版存在问题:
- 对存量数据处理的支持不好。设置数据的 Storage Policies 属性后,只对新写入的数据有效。对于存量数据,系统并不能将其自动移动到对应的存储介质上。
-
没有提供冷数据分析方案。
-
没有提供把远程存储设备(譬如 S3)mount 到 DataNode 上作为存储类型的方案。
八、HBase利用HDFS异构存储特性
HBase 资源隔离 + 异构存储。SATA 磁盘的随机 iops 能力,单次访问的 RT,读写吞吐上都远远不如 SSD,那么对 RT 极其敏感业务来说,SATA 盘并不能胜任,所以我们需要 HBase 有支持 SSD 存储介质的能力。
为了 HBase 可以支持异构存储,首先在 HDFS 层面就需要做响应的支持,在 HDFS 2.6.x 以及之后的版本,提供了对 SSD 上存储文件的能力,
换句话说在一个 HDFS 集群上可以有 SSD 和 SATA 磁盘并存,对应到 HDFS 存储格式为 [ssd] 与 [disk]。
存储架构
添加 SSD 磁盘之后,HDFS 集群存储架构示意图:

使用场景
- 将WAL日志保存到SSD中,其他的数据则存储在普通的SATA盘中
HBase实现异构wal存储很简单,底层依赖的就是hdfs的异构storage策略,不过是将wal文件所在的目录经反射调用dfs client的setStoragePolicy方法设置为用户指定的policy。
具体的配置策略如下:在 hdfs-site.xml 中修改:
<property>
<name>hbase.wal.storage.policy</name>
<value>ONE_SSD</value>
</property>
该配置的默认值是NONE,也就是wal文件和数据都存储在DISK上,不做区分。
可以修改为ONE_SSD或者ALL_SDD,不同在于:
- ONE_SSD:wal的一个副本置于SSD上,而其他副本仍然在默认存储;
- ALL_SSD:wal文件的所有副本都存储于SSD盘上;
- 将表的指定列族数据存储在SSD盘中
在HBASE-14061之后,我们支持通过 hbase.hstore.block.storage.policy 配置,我们支持CF级别设置来覆盖配置文件中的设置。
例如,要创建具有两个系列的表:具有“ ALL_SSD”存储策略的“ cf1”和具有“ ONE_SSD”的“ cf2”,我们可以在hbase shell中使用以下命令:
create 'table',{NAME=>'f1',STORAGE_POLICY=>'ALL_SSD'},{NAME=>'f2',STORAGE_POLICY=>'ONE_SSD'}
我们还可以像其他所有配置一样在table属性中设置配置:
create 'table',{NAME=>'f1',CONFIGURATION=>{'hbase.hstore.block.storage.policy'=>'ONE_SSD'}}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号