日爬百万数据的域名限制、url的清洗和管理
一、域名去重
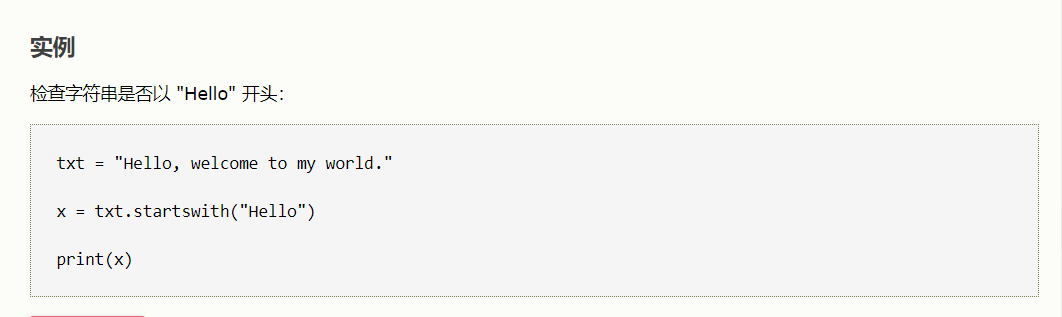
1、检测开头:link.startswith('http')
txt = "Hello, welcome to my world." x = txt.startswith("Hello") print(x)
#如果字符串以指定的值开头,则 startswith() 方法返回 True,否则返回 False。
string.startswith(value, start, end)
![]()
tldextract是一个第三方模块,意思就是Top Level Domain extract,即顶级域名提取
使用时 需要安装,命令如下
pip install tldextract
URL的结构,news.baidu.com 里面的news.baidu.com叫做host,它是注册域名baidu.com的子域名,而com就是顶级域名TLD。

tld = tldextract.extract(link) if tld.domain == 'baidu': continue news_links.append(link)
参考链接:https://www.yuanrenxue.com/crawler/news-crawler.html
二、url的清洗
1、判断网页种类(静态网页?图片?等等的内容)
2、去除外部的链接(广告)
#Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
g_bin_postfix = set([ 'exe', 'doc', 'docx', 'xls', 'xlsx', 'ppt', 'pptx', 'pdf', 'jpg', 'png', 'bmp', 'jpeg', 'gif', 'zip', 'rar', 'tar', 'bz2', '7z', 'gz', 'flv', 'mp4', 'avi', 'wmv', 'mkv', 'apk', ]) g_news_postfix = [ '.html?', '.htm?', '.shtml?', '.shtm?', ] def clean_url(url): # 1. 是否为合法的http url if not url.startswith('http'): return '' # 2. 去掉静态化url后面的参数 for np in g_news_postfix: p = url.find(np) if p > -1: p = url.find('?') url = url[:p] return url # 3. 不下载二进制类内容的链接 up = urlparse.urlparse(url) path = up.path if not path: path = '/' postfix = path.split('.')[-1].lower() if postfix in g_bin_postfix: return '' # 4. 去掉标识流量来源的参数 # badquery = ['spm', 'utm_source', 'utm_source', 'utm_medium', 'utm_campaign'] good_queries = [] for query in up.query.split('&'): qv = query.split('=') if qv[0].startswith('spm') or qv[0].startswith('utm_'): continue if len(qv) == 1: continue good_queries.append(query) query = '&'.join(good_queries) url = urlparse.urlunparse(( up.scheme, up.netloc, path, up.params, query, '' # crawler do not care fragment )) return url
3、url的管理(urlpool)
mport pickle import leveldb import time import urllib.parse as urlparse class UrlPool: '''URL Pool for crawler to manage URLs ''' def __init__(self, pool_name): self.name = pool_name self.db = UrlDB(pool_name) self.waiting = {} # {host: set([urls]), } 按host分组,记录等待下载的URL self.pending = {} # {url: pended_time, } 记录已被取出(self.pop())但还未被更新状态(正在下载)的URL self.failure = {} # {url: times,} 记录失败的URL的次数 self.failure_threshold = 3 self.pending_threshold = 10 # pending的最大时间,过期要重新下载 self.waiting_count = 0 # self.waiting 字典里面的url的个数 self.max_hosts = ['', 0] # [host: url_count] 目前pool中url最多的host及其url数量 self.hub_pool = {} # {url: last_query_time, } 存放hub url self.hub_refresh_span = 0 self.load_cache() def __del__(self): self.dump_cache() def load_cache(self,): path = self.name + '.pkl' try: with open(path, 'rb') as f: self.waiting = pickle.load(f) cc = [len(v) for k, v in self.waiting.items()] print('saved pool loaded! urls:', sum(cc)) except: pass def dump_cache(self): path = self.name + '.pkl' try: with open(path, 'wb') as f: pickle.dump(self.waiting, f) print('self.waiting saved!') except: pass def set_hubs(self, urls, hub_refresh_span): self.hub_refresh_span = hub_refresh_span self.hub_pool = {} for url in urls: self.hub_pool[url] = 0 def set_status(self, url, status_code): if url in self.pending: self.pending.pop(url) if status_code == 200: self.db.set_success(url) return if status_code == 404: self.db.set_failure(url) return if url in self.failure: self.failure[url] += 1 if self.failure[url] > self.failure_threshold: self.db.set_failure(url) self.failure.pop(url) else: self.add(url) else: self.failure[url] = 1 self.add(url) def push_to_pool(self, url): host = urlparse.urlparse(url).netloc if not host or '.' not in host: print('try to push_to_pool with bad url:', url, ', len of ur:', len(url)) return False if host in self.waiting: if url in self.waiting[host]: return True self.waiting[host].add(url) if len(self.waiting[host]) > self.max_hosts[1]: self.max_hosts[1] = len(self.waiting[host]) self.max_hosts[0] = host else: self.waiting[host] = set([url]) self.waiting_count += 1 return True def add(self, url, always=False): if always: return self.push_to_pool(url) pended_time = self.pending.get(url, 0) if time.time() - pended_time < self.pending_threshold: print('being downloading:', url) return if self.db.has(url): return if pended_time: self.pending.pop(url) return self.push_to_pool(url) def addmany(self, urls, always=False): if isinstance(urls, str): print('urls is a str !!!!', urls) self.add(urls, always) else: for url in urls: self.add(url, always) def pop(self, count, hub_percent=50): print('\n\tmax of host:', self.max_hosts) # 取出的url有两种类型:hub=1, 普通=0 url_attr_url = 0 url_attr_hub = 1 # 1. 首先取出hub,保证获取hub里面的最新url. hubs = {} hub_count = count * hub_percent // 100 for hub in self.hub_pool: span = time.time() - self.hub_pool[hub] if span < self.hub_refresh_span: continue hubs[hub] = url_attr_hub # 1 means hub-url self.hub_pool[hub] = time.time() if len(hubs) >= hub_count: break # 2. 再取出普通url left_count = count - len(hubs) urls = {} for host in self.waiting: if not self.waiting[host]: continue url = self.waiting[host].pop() urls[url] = url_attr_url self.pending[url] = time.time() if self.max_hosts[0] == host: self.max_hosts[1] -= 1 if len(urls) >= left_count: break self.waiting_count -= len(urls) print('To pop:%s, hubs: %s, urls: %s, hosts:%s' % (count, len(hubs), len(urls), len(self.waiting))) urls.update(hubs) return urls def size(self,): return self.waiting_count def empty(self,): return self.waiting_count == 0
来自猿人学官网

 浙公网安备 33010602011771号
浙公网安备 33010602011771号