

使用pandas处理数据和matplotlib生成可视化图表
一、缘由
上一篇输入关键词“口红”,将淘宝中的的相关商品信息全部爬取了下拉,并且以CSV的文件格式储存。我们拿到数据之后,那么就需要对数据进行处理。只是将爬取到的数据以更直观的方式——图表呈现出来。并且最后使用jieba、wordcloud来对商品名称进行词云的分析。
二、代码实现
话不多说,直接上代码:
#数据分析 import numpy as np import pandas as pd import matplotlib.pyplot as plt from matplotlib.ticker import FuncFormatter import re import jieba from wordcloud import WordCloud,STOPWORDS from PIL import Image import datetime def data_analysis(goods): ###数据处理 #读取数据 df=pd.read_csv(r'C:/Users/sunshine/Desktop/课件/图片/爬取的数据/' + '淘宝' + goods+'.csv') #降序排列 df1=df.sort_values('sum_body',ignore_index=True) #删除重复值 df2=df1.drop_duplicates() #重置索引 df2.index = range(len(df2)) #用平均值替换缺失值 df3=df2.fillna(df2.mean()) #用上下四分位数处理异常数据 #确定正常数据的范围 上四分位数加上1.5倍分位差 下四分位数减1.5倍分位差 分位差是上四分位数减下四分位数 mean1=df3['sum_body'].quantile(q=0.25) mean2=df3['sum_body'].quantile(q=0.75) mean3=mean2-mean1 topnum=mean2+1.5*mean3 lownum=mean1-1.5*mean3 #判断是否需要处理异常值 #范围 #print((lownum['prices'],topnum['prices'])) # print((lownum,topnum)) #判断价格是否在范围之内 结果为存在超出正常范围的价格 # print('判断是否存在超出正常范围的价格:',any(df3['prices']>topnum['prices'])) # print('判断是否存在低于正常范围的价格:',any(df3['prices']<lownum['prices'])) #判断购买人数是否在正常范围 结果为存在超出正常范围的价格 # print('判断是否存在超出正常范围的购买人数:',any(df3['sum_body']>topnum)) # print('判断是否存在超出正常范围的购买人数:',any(df3['sum_body']<lownum)) # plt.boxplot(x=df3['sum_body']) # plt.show() # df3['prices'][df3['prices']<topnum] #价格替换 replace_value_prices=df3['prices'][df3['prices']<topnum].max() df3.loc[df3['prices']>topnum,'prices']=replace_value_prices #购买人数替换 replace_value_sum_body=df3['sum_body'][df3['sum_body']<topnum].max() df3.loc[df3['sum_body']>topnum,'sum_body']=replace_value_sum_body # plt.boxplot(x=df3['sum_body']) # plt.show() # 进行聚合分析 # 生成数据透视表 # 1、地域和价格 df3.groupby('loc')['prices'].mean() # 2、地区和店铺数量 df3['loc'].value_counts() # 3、价格和销售额 # 4、店铺和销售额 # 5、价格和购买人数 df4=df3.groupby('shop_name').agg({'prices':np.mean,'sum_body':np.mean}) df4['sum_sales']=df4['prices']*df4['sum_body'] df5=pd.merge(df3,df4,how='left').fillna(method='ffill') # print(df5) # 6、地区和销量 df6=df5.groupby(['shop_name', 'loc']).agg({'prices': np.mean, 'sum_body': np.mean}) df7=df6.reset_index() df8=df7.groupby('loc').sum().reset_index() ''' 使用matplotlib画出饼状图、直方图频率分布图、散点图、柱状图、 ''' time=str(datetime.datetime.now().date()) #1、地区和销量的柱状图 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False plt.figure(figsize=(20,9)) x_data=df8['loc'] y_data=df8['sum_body'] plt.bar(x_data,y_data,color='b',width=1) plt.xlabel('地区',fontsize=15) plt.ylabel('销量',fontsize=15) plt.title('不同地区的销量',fontdict={'fontsize':20}) plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'地区和销量柱状图.png') plt.show() plt.close() #2、地区和店铺数量的直方图 plt.figure(figsize=(20,9)) df9=df3['loc'].value_counts().reset_index() x_data=df9['index'] y_data=df9['loc'] plt.bar(range(0,len(x_data)),y_data,tick_label=x_data) plt.xlabel('地区',fontsize=15) plt.ylabel('店铺数量',fontsize=15) plt.title('地区和店铺数量的关系',fontdict={'fontsize':20}) plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'地区和店铺数量直方图.png') plt.show() plt.close() #3、价格和销售量的散点图 plt.figure() x_data=df4['prices'] y_data=df4['sum_body'] plt.scatter(x_data,y_data,color='pink') plt.xlabel('价格') plt.ylabel('销量') plt.title('价格和销量之间的关系') plt.grid() plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'价格和销量散点图.png') plt.show() plt.close() #4、价格和销售额的散点图 #价格和销售额之间的散点图 plt.figure() np.set_printoptions(suppress=True, precision=10, threshold=2000, linewidth=150) pd.set_option('display.float_format',lambda x : '%.2f' % x) x_data=df4['prices'] y_data=df4['sum_sales'] plt.scatter(x_data,y_data,color='purple') def formatnum(x,pos): return float(x) formatter = FuncFormatter(formatnum) # 设置坐标轴格式 plt.gca().yaxis.set_major_formatter(formatter) plt.yticks() plt.xlabel('价格') plt.ylabel('销量') plt.title('价格和销量额之间的关系') plt.grid() plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'价格和销量额散点图.png') plt.show() plt.close() #5、地区和店铺数量分布的饼状图 plt.figure(figsize=(10,8),dpi=150) x_data=df9['index'] y_data=df9['loc'] plt.pie(y_data,labels=x_data,radius=1.2,autopct='%1.1f%%',pctdistance=0.6,textprops={'fontsize':10}) plt.title('店铺地区分布',fontdict={'fontsize':10},y=1.0) plt.legend(loc=(1.1,0.1),fontsize=10) plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'地区和店铺数量分布饼状图.png') plt.show() plt.close() #6、价格的频数分布直方图 plt.figure() data=df3['prices'] plt.hist(data,bins=50,color='g') plt.xlabel('价格') plt.ylabel('频数') plt.title('价格的频数分布直方图') plt.grid() plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'价格的频数分布直方图.png') plt.show() plt.close() #7、关于店铺名称的词云 plt.figure(figsize=(8,8),dpi=100) jieba.setLogLevel(jieba.logging.INFO) #建立停用词 stop_words=set(STOPWORDS) with open(r"C:\Users\sunshine\Desktop\课件\图片\爬取的数据\stop_words.txt",'r',encoding='utf-8') as f: stop_words.add(f.read()) #统计文件的读取成为字符串 data=df3['shop_name'].values data="".join(data) #对统计文本进行分词处理 cut_list=jieba.lcut(data) #对每一个分词进行处理 def fiter_word(words,stop_words): num=re.search('\d+',words) if num==None: if words not in stop_words: if len(words)>1: return words else: pass else: pass #对文本进行次数的统计 word_freq=dict() for one in cut_list: # print(list(one)) row=fiter_word(one,STOPWORDS) if row: word_freq[row]=word_freq.get(row,0)+1 # print(word_freq) #使用图片背景 mask=np.array(Image.open(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\背景.png')) wc=WordCloud(font_path=r'C:\Windows\Fonts\simkai.ttf',background_color='white', mask=mask,max_font_size=100,max_words=500,random_state=1, scale=3,stopwords=stop_words) wc.generate_from_frequencies(word_freq) plt.imshow(wc,interpolation='bilinear') plt.axis('off') plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'店铺名称词云.png') plt.show() plt.close()
if __name__ == '__main__':
data_analysis(goods)
三、运行结果
1、地区和销量的柱状图
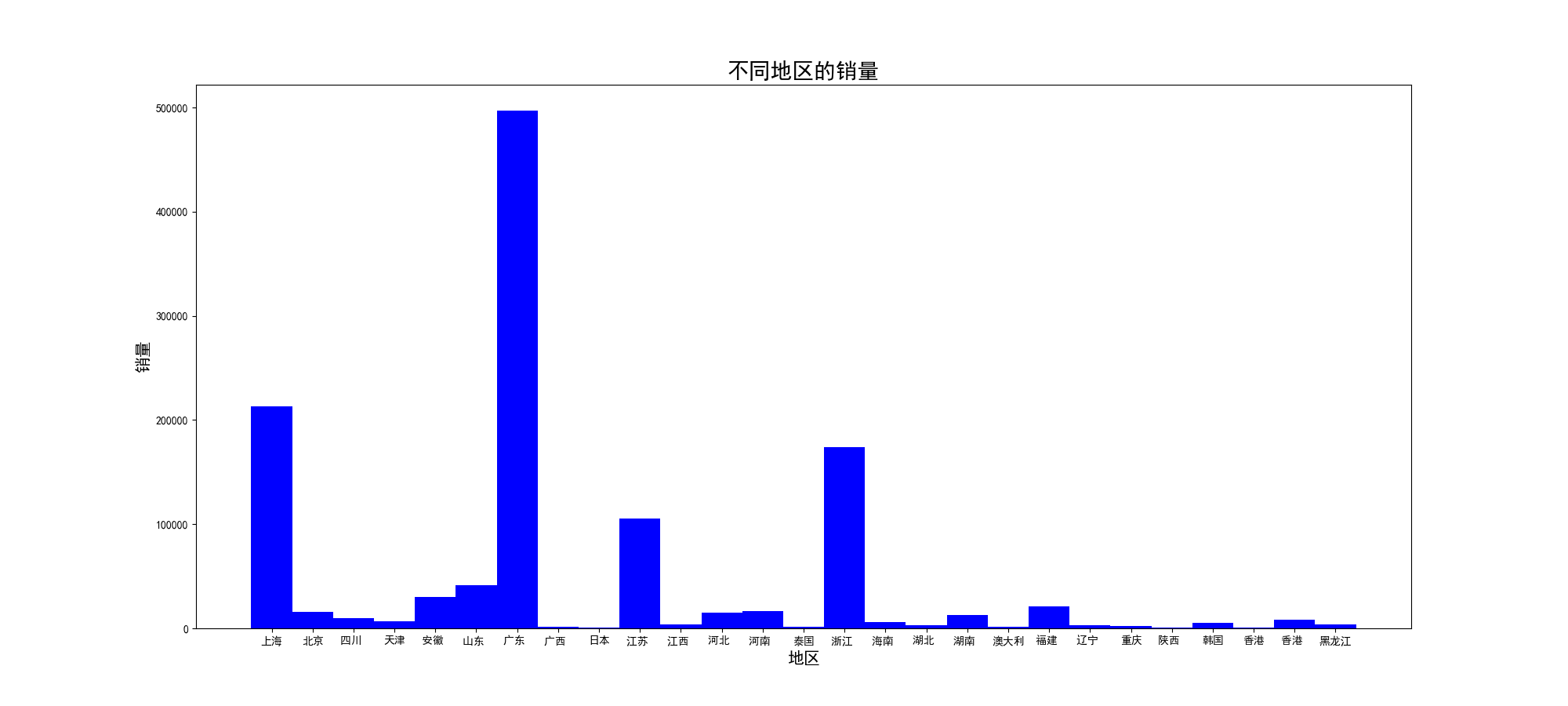
2、地区和店铺数量的直方图
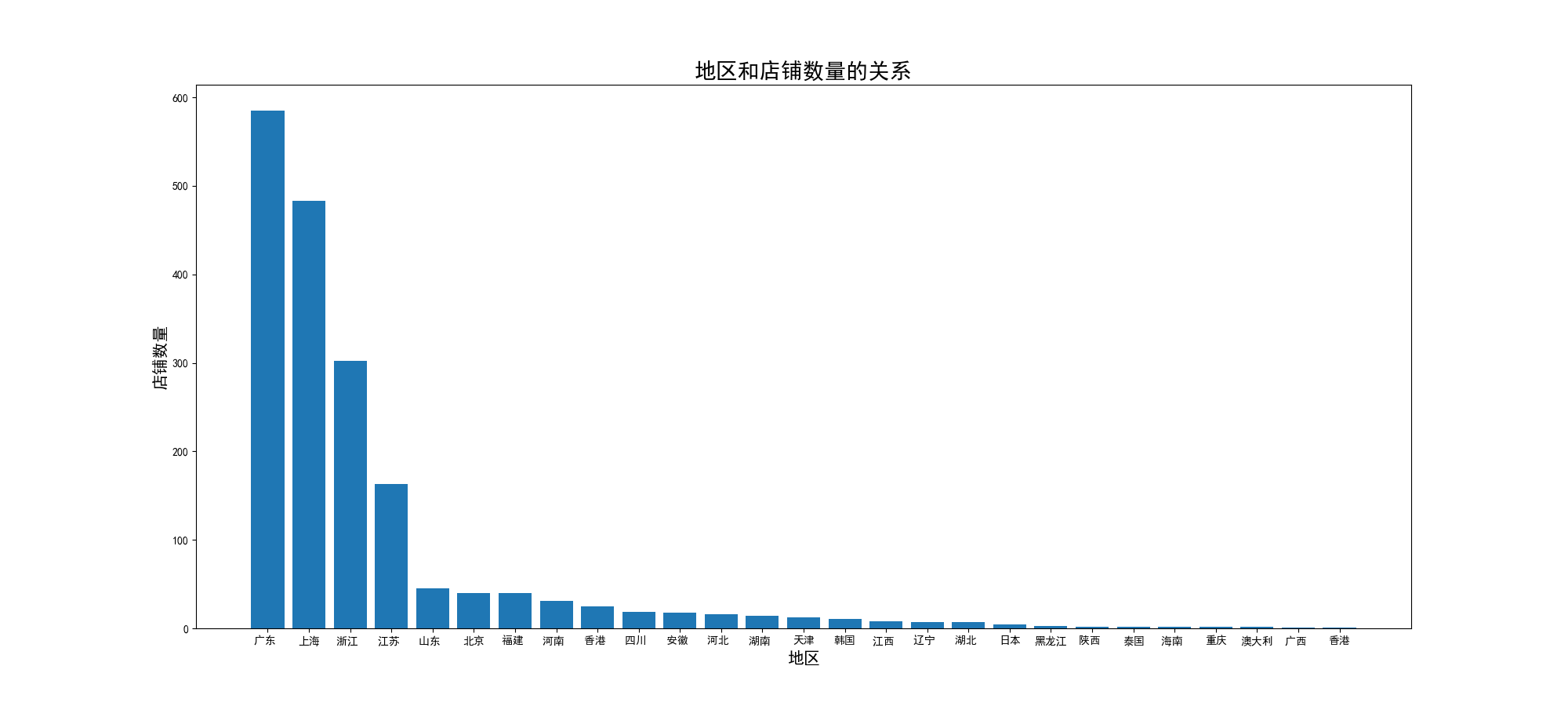
3、价格和销售量的散点图
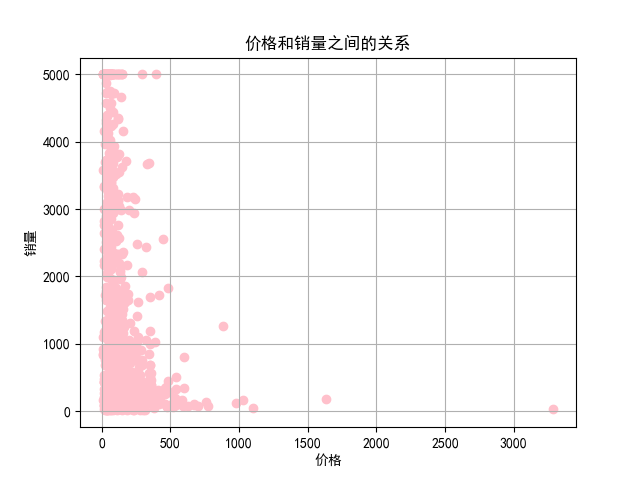
4、价格和销售额的散点图
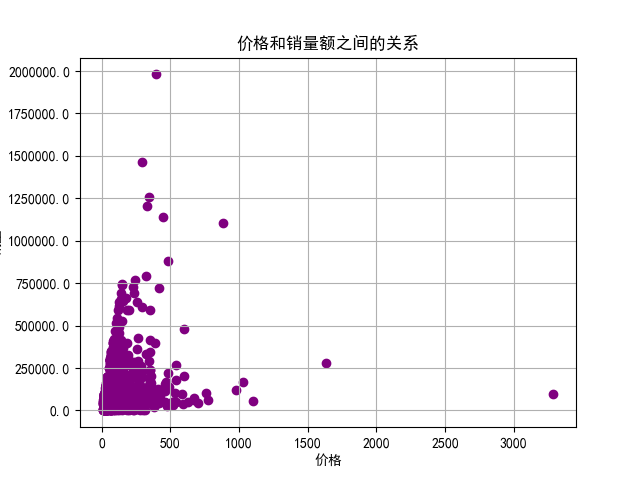
5、地区和店铺数量分布的饼状图

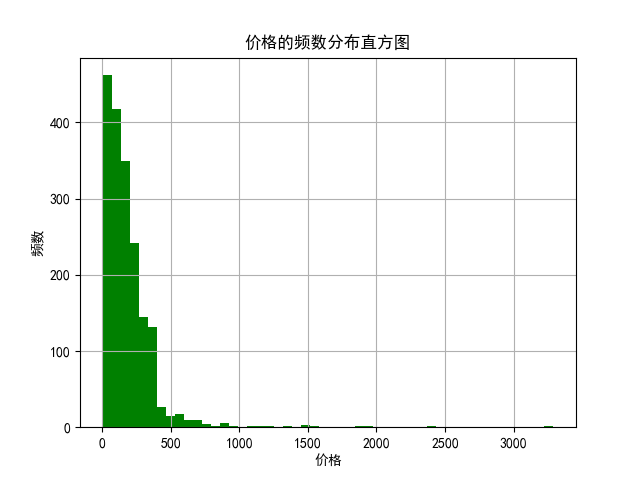
6、价格的频数分布直方图
7、关于店铺名称的词云

四、小结
当然这次是基于matplotlib实现的制作图表。但是却没有交互的功能。如果可以使用pygal库来进行的话,可以实现交互的功能,会更方便前端的展示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号