Pandas:数据合并与对比
1、数据追加df.append()
df.append(self, other, ignore_index=False,
verify_integrity=False, sort=False)
其中:
- other 是它要追加的其他 DataFrame 或者类似序列内容
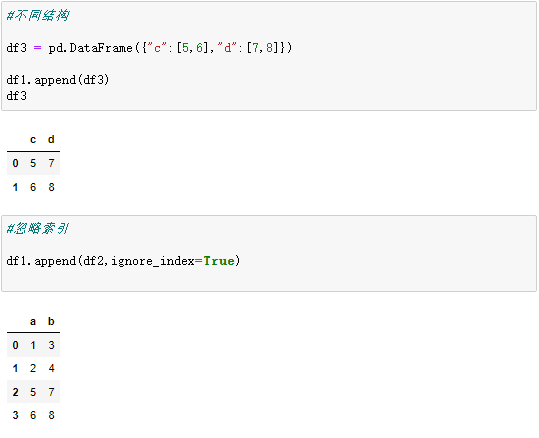
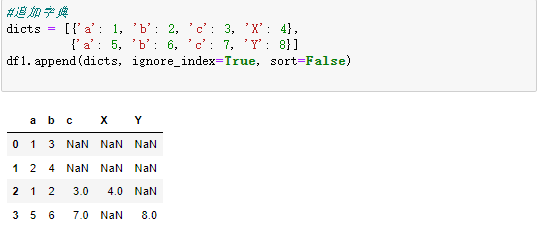
- ignore_index 如果为 True 则重新进行自然索引
- verify_integrity 如果为 True 则遇到重复索引内容时报错
- sort 进行排序
import pandas as pd
df1 = pd.DataFrame({'a':[1,2],'b':[3,4]})
df2 = pd.DataFrame({'a':[5,6],'b':[7,8]})
df1.append(df2)


2、数据连接pd.concat()
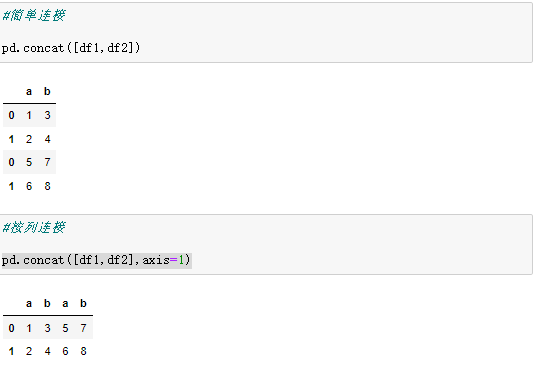
Pandas 数据的连接可以实现纵向和横向连接,将数据连接后会形成一个新的对象, Series 或 DataFrame。连接是最常用的多个数据合并操作。
pd.concat() 是专门用于数据连接合并的函数,它可以沿着行或者列进行操作,同时可以指定非合并轴的合并方式(合集、交集等)。
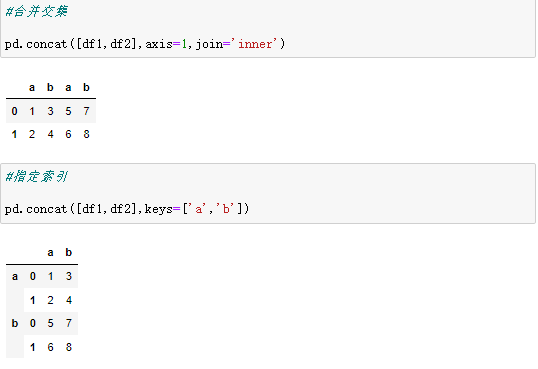
3、数据合并pd.merge()
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
- how:连接方式,默认为inner,可设为inner/outer/left/right
- on:根据某个字段进行连接,必须存在于两个DateFrame中(若未同时存在,则需要分别使用left_on 和 right_on 来设置)
- left_on:左连接,以DataFrame1中用作连接键的列
- right_on:右连接,以DataFrame2中用作连接键的列
- left_index:bool, default False,将DataFrame1行索引用作连接键
- right_index:bool, default False,将DataFrame2行索引用作连接键
- sort:根据连接键对合并后的数据进行排列,默认为True
- suffixes:对两个数据集中出现的重复列,新数据集中加上后缀 _x, _y 进行区别



4、按元素合并
在数据合并过程中需要对应位置的数值进行计算,比如相加、平均,对空值补齐等,Pandas 提供了 df.combine_first() 和 df. combine() 等方法进行这些操作。
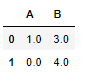
df1 = pd.DataFrame({'A': [None, 0], 'B': [None, 4]})
df2 = pd.DataFrame({'A': [1, 1], 'B': [3, 3]})
#使用相同位置的值更新空元素,它只能是 df1 有空元素时才能被替换,如果数据结构不一致,所得 DataFram e的行索引和列索引将是两者的并集。
df1.combine_first(df2)
df. combine()
可以与另一个 DataFrame 进行按列组合。使用函数将一个 DataFrame 与其他DataFrame合并,以逐元素合并列。 所得 DataFrame 的行索引和列索引将是两者的并集。
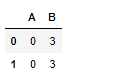
df1 = pd.DataFrame({'A': [0, 0], 'B': [4, 4]})
df2 = pd.DataFrame({'A': [1, 1], 'B': [3, 3]})
# s1 列总和如果小于 s2列总和取 s1, 否则取 s2
take_smaller = lambda s1, s2: s1 if s1.sum() < s2.sum() else s2
df1.combine(df2, take_smaller)
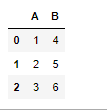
df.update()
使用来自另一个 DataFrame 的非NA值进行修改,原 df 为被更新。
df = pd.DataFrame({'A': [1, 2, 3],
'B': [400, 500, 600]})
new_df = pd.DataFrame({'B': [4, 5, 6],
'C': [7, 8, 9]})
df.update(new_df)
df
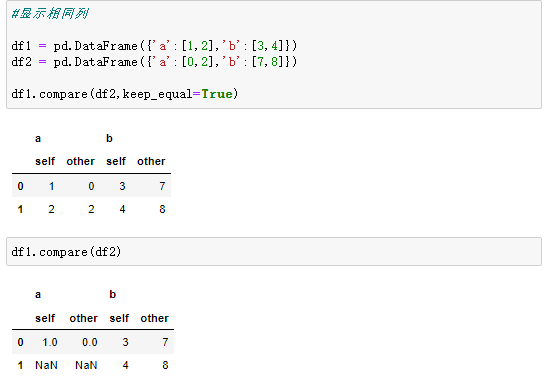
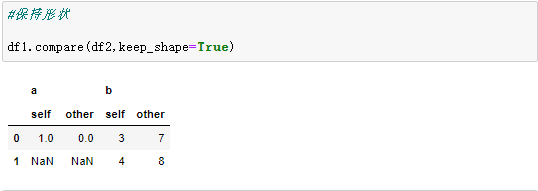
5、数据对比
pd.compare(other, align_axis=1, keep_shape=False, keep_equal=False)
- other:被对比的数据
- align_axis=1:差异堆叠在列/行上
- keep_shape=False:不保留相等的值
- keep_equal=False:不保留所有原始行和列


 浙公网安备 33010602011771号
浙公网安备 33010602011771号