pandas:数据迭代、函数应用
1、数据迭代
1.1 迭代行
(1)df.iterrows()
for index, row in df[0:5].iterrows(): #需要两个变量承接数据
print(row)
print("\n")
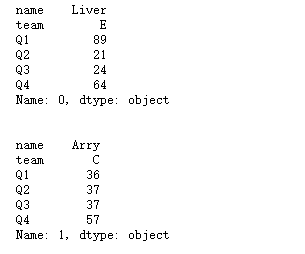
for index, row in df[0:5].iterrows():
print(row.team) #通过对象属性方式
print(row['name']) #通过字典方式读取具体列
print("\n")

(2)df.iertuples()
生成一个nametuples类型的数据,默认name为Pandas(可在参数中指定)
for row in df[0:5].itertuples():
print(row,"\n")

for row in df[0:5].itertuples():
print(row.name,"\n") #可以通过元素属性的方式取出具体值

1.2 迭代列
(1)df.iteritems()、df.items()
df.items(),df.iteritems() 迭代时返回(列名,本列的series结构数据)
for label, item in df[0:5].items(): #label是列名
print(label,item)
print("\n")

for label, item in df[0:5].items():
print(item) #item的数据结构是series(有行索引,和数据)
print("\n")

for label, colunm in df[0:5].items():
print(colunm.sort_values()) #数据结构是series(有行索引,和数据)因此可以使用series的方法
print("\n")

(2)对dataframe直接进行迭代
for item in df:
print(item) #item会得到df的列名
print("\n")

for item in df:
print(df[item]) #item会得到df的列名,通过df[item]又可以得到每个列的值
print("\n")

2、函数应用
2.1 pipe()
将复杂的调用简化,语法结构为df.pipe(<函数名>,<参数列表或字典>)
ta将dataframe或series作为函数的第一个参数
定义一个函数,给所有季度的成绩加n,然后增加一个平均数
def add_mean(df,n):
n_df = df.copy()
n_df = n_df.loc[:,'Q1':'Q4'] + n
n_df['avg'] = n_df.sum(1)
return n_df
add_mean(df,100) #此时原本的df没变
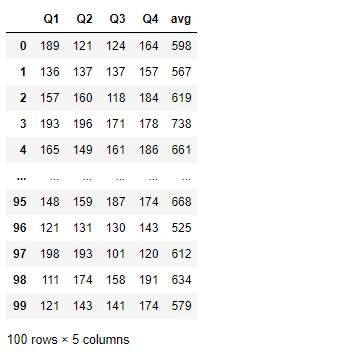
df.pipe(add_mean,100) #运行结果与上图一致
函数部分还可以使用lambda
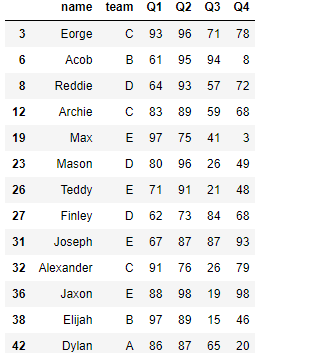
df.pipe(lambda df,x,y: df[(df.Q1>x) & (df.Q2 >y)],60,70) #选出df中同时满足Q1>60,Q2>70的数据
2.2 apply()
apply(),对df按行和列(默认逐列传入)进行函数处理,也支持series(传入具体值)
将name转换为全小写
df.name.apply(lambda x : x.lower())

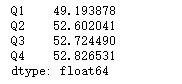
计算每个季度的平均成绩,计算方法为去掉一个最高分和去掉一个最低分
def avg(s ):
min = s.min()
max = s.max()
average = (s.sum()-min-max)/ (s.count()-2)
return average
df.select_dtypes(include='number').apply(avg)

计算每个学生的平均成绩
df1 = df.set_index('name')
df1.select_dtypes(include='number').apply(avg)
与np.where()配合使用 np.where(逻辑表达式,替换值1,替换值2)
df.apply(lambda x: (x.team=='A') & (x.Q1>90), axis=1).map({True:'GOOD',False:'Other'})
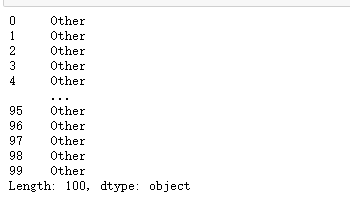
2.3 applymap()
applymap(),对dataframe或者series的所有元素(不包括索引)应用函数处理
使用lambda时,变量是指具体的值
例子:计算每个数据的长度
df.applymap(lambda x:len(str(x)))
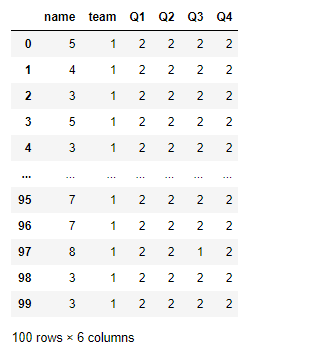
2.4 map()
map()根据输入对应关系映射值返回最终数据
可传入一个人字典(键为原值,值为新值)
可传入一个函数(参数为series的每个值)
df.team.map({'A':'一班','B':'二班','C':'三班','D':'四班'}) #没有映射值的会被填为NAN

df.team.map('I am a {}'.format) #传入格式化表达式来格式化数据内容

df.Q1.map('11{}'.format) #数字会被转为字符

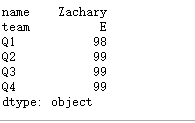
2.5 agg()
agg使用指定轴上的一项或多项操作进行汇总
可以传入一个函数挥着函数的字符
每列的最大值
df.agg('max')
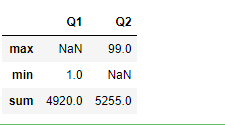
将所有列聚合产生sum和min两行
传入多个函数
df.agg(['sum','min'])

序列多个聚合
df.agg({'Q1':['sum','min'],'Q2':['sum','max']})
分组后聚合
df.groupby('team').agg('max')
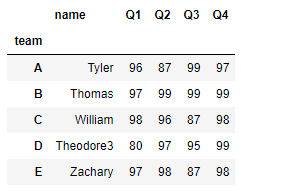
支持每个列分别用不同的方法聚合
支持指定轴的方向
1、不同列使用不同的方法进行聚合
df.agg(最大值=('Q1',max),
最小值=('Q2',min),
平均值=('Q3',np.mean),
求和=('Q4',lambda x :x.sum())
)
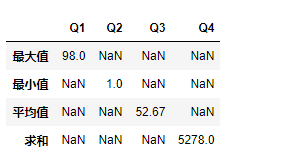
2、按行聚合
df.loc[:,'Q1':'Q4'].agg(np.mean,axis=1)
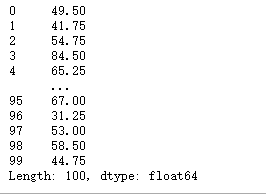
2.6 transform()
datafram或者series自身调用函数,并返回一个与自身长度相同的数据
1、应用匿名函数
df.transform(lambda x:x2) #字符串会变成重复两遍,数字会2
调用多个函数
df.transform([np.sqrt,np.exp]) #自动筛选数字列,并应用
3、参考文献
《深入浅出Pandas》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号