
python基础(7)--深浅拷贝、函数
1.深浅拷贝
在Python中将一个变量的值传递给另外一个变量通常有三种:赋值、浅拷贝、深拷贝
Python数据类型可氛围基本数据类型包括整型、字符串、布尔及None等,还有一种由基本数据类型作为最基本的元素所组成的像列表、元组、字典等。
在Python中基本数据类型的赋值、深浅拷贝没有任何意义,都是指向同一块内存地址,也不存在层次问题。
下面看基本数据类型的深浅拷贝
import copy n1 = 'abc' n2 = n1 n3 = copy.copy(n1) n4 = copy.deepcopy(n1) print(id(n1)) #输出140350336680040 print(id(n2)) #输出140350336680040 print(id(n3)) #输出140350336680040 print(id(n4)) #输出140350336680040
以上代码说明Python的copy模块的copy和deepcopy函数实现了浅拷贝和深拷贝,可以看到,赋值、浅拷贝和深拷贝最后的id(Python内存地址的表达方式)都是一样的
接下来讨论其他的列表、元组、字典等非基本数据类型对象的赋值、深浅拷贝的区别
假设字典n1 = {"k1": "abc", "k2": 123, "k3": ["abc", 123]}
赋值是将变量的内存赋给另一个变量,让另一个变量指向那个内存地址
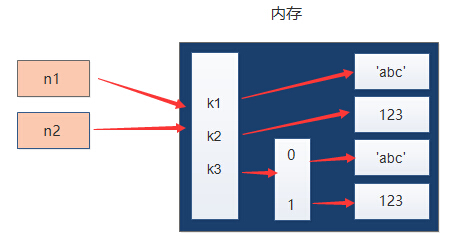
浅拷贝
浅拷贝就是在内存中将第一层额外开辟空间进行存放
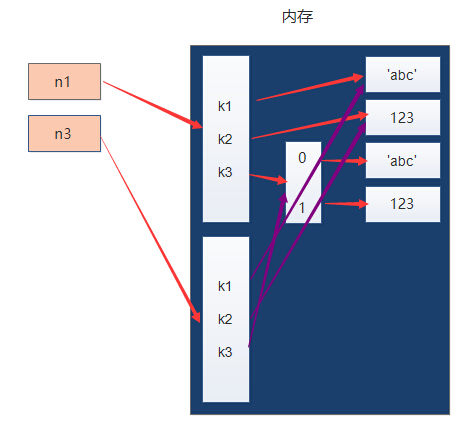
n1 = {"k1": "abc", "k2": 123, "k3": ["abc", 123]}
print(id(n1)) #140350328984328
n3 = copy.copy(n1)
print(id(n3)) #140350328986504可以看n3的内存地址已经和n1不同了
print(id(n1['k3'])) #140350328603976
print(id(n3['k3'])) #140350328603976 字典里的列表还是指向同一个列表
深拷贝
深拷贝就是在内存中将数据重新创建一份,不仅仅是第一层,第二层、第三层...都会重新创建
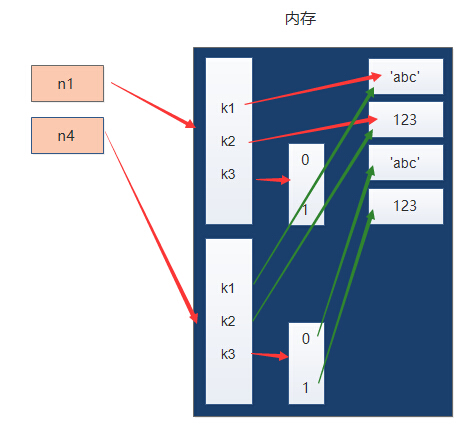
n1 = {"k1": "abc", "k2": 123, "k3": ["abc", 123]}
print(id(n1)) #140350328984328
n3 = copy.deepcopy(n1)
print(id(n1['k3'])) #140350328603976
print(id(n3['k3'])) #140350328604296 #可以看到第二层的列表也拷贝了一份,内存地址已经完全不一样
#注意,这仅局限于非基本数据类型,基本数据类型还是同一个内存地址
2.函数
函数的定义及调用
定义一个函数要使用def关键字,依次写出函数名、括号、括号中的参数和冒号:,然后用缩进的代码块写函数体,函数体内可以调用return语句返回结果。
函数名作为函数的名称,也可以像变量一样进行赋值操作、甚至作为参数进行传递。
函数的参数
1)位置参数
这是最常见的定义方式,一个函数可以定义任意个参数,每个参数用逗号分隔,例如:
def Foo1(arg1, arg2):
print(arg1, arg2)
用这种方式定义的函数在调用的的时候也必须在函数名后的小括号里提供个数相等的值(实际参数),而且顺序必须相同,也就是说在这种调用中,形参和实参的个数必须一致,而且必须一一对应,也就是说第一个形参对应这第一个实参。例如:
Foo1('abc', 123)
#输出结果 abc 123
也可以通过如下方式传递参数,而不必考虑顺序问题,但数量无论如何必须一致。
foo3(arg2 = 123, arg1 = 'abc')
2)默认参数
我们可以给某个参数指定一个默认值,当调用时,如果没有指定那个参数,那个参数就等于默认值
def Foo2(arg1, arg2 = 123): print(arg1, arg2)
调用
Foo2('abc') Foo2('abc', 345) ''' 执行结果 abc 123 abc 345 注意:定义的时候默认参数必须放到所有位置参数的后面进行定义,否则会报语法错误 '''
3)可变参数
可变参数就是传入的参数个数是可变的,也可以是0个,例如
def Foo3(*args):
print(args)
调用
Foo3(1, 2, 'abc') #执行结果 (1, 2, 'abc') 可以看到我们传递了三个参数都被Python转化为元祖,保存到args中了,这样我们就可以通过索引对参数记性调用,或者通过for in进行遍历
4)关键字参数
可变参数在调用过程中会组装成元组,元组只能通过索引进行调用,有时不是很方便,故Python可以通过关键字索引将传入的参数组装成字典
def Foo4(**kwargs): print(kwargs, type(kwargs)) Foo4(k1 = 'abc', k2 = 123) #执行结果 {'k2': 123, 'k1': 'abc'} <class 'dict'> #关键字参数允许传入0个或任意个参数名的参数,0个的话就是一个空字典
参数组合
在Python中定义函数,可以用必选参数(位置参数)、默认参数、可变参数、关键字参数这几种参数进行组合使用,但是顺序必须是,必选参数、默认参数、可变参数、关键字参数。
def Foo5(arg1, arg2='abc', *args, **kwargs): print('arg1:', arg1) print('arg2:', arg2) print('args', args) print('kwargs', kwargs) Foo5(123, 'abc', 456, 'def', k1=123, k2='abc') ''' 执行结果 arg1: 123 arg2: abc args (456, 'def') kwargs {'k1': 123, 'k2': 'abc'} '''
lambda匿名函数
匿名函数就是功能非常简单只需要一行代码就可以实现的,例如,求圆形面积
f = lambda r: 3.14 * r * r print(f(4)) # 输出 50.24 #r相当于匿名函数的参数,当然也可以有多个参数,不用在写return,表达式就是返回的结果。
使用匿名函数有个好处,因为函数没有名字,不用担心函数名冲突,此外匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量调用该函数。
关于函数的return语句
1)函数可以没有return语句,没有就默认返回None
2)return语句有点类似循环的break,当函数执行到return语句时候,直接跳出函数的执行
3)return可以返回多个值,多个值可以用两个变量接收,也可以额一个变量接收
def Foo6(): return 123, 'abc' res1, res2 =Foo6() print('res1:', res1) #res1: 123 print('res2:', res2) #res2: abc res = Foo6() print('res:', res) #res: (123, 'abc') #返回多个值就是返回一个元组,使用两个变量接收的时候回将元组的元素与变量一一对应赋给多个变量
关于可变参数和关键字参数的传递小技巧
我们已经知道可变参数和关键字参数分别将传递的参数组装成元组和字典,那么我们同样可以直接将元组、列表和字典直接传递给函数作为参数,传递的时候列表和元组要在变量前面加一个*,字典要在前面加两个*,否则函数还是会把它们当成一个普通的参数传递进行处理
def Foo7(*args, **kwargs): print(args) print(kwargs) li = [1, 2, 3] dic = {'k':1, 'k2':2} Foo7(li, dic) Foo7(*li, **dic) ''' 执行结果 ([1, 2, 3], {'k': 1, 'k2': 2}) {} #可以看到两个参数都被可变参数接收了,关键字参数啥也没有 (1, 2, 3) {'k': 1, 'k2': 2} '''
Python常用的内置函数

只重点关注标记的内置函数


print(abs(-10)) #输出10
print(all([1, True, 1 == 1])) #True
print(any([None, "", [], (), {}, 0, False])) #False print(any([None, "", [], (), {}, 0, True]) )#True #通常情况下“空”(None,空字符串、空列表,0等等)都是表示False
print(bin(10)) #'0b1010'
print(bool()) #False print(bool(10)) #True
print(chr(89999)) #'\U00015f8f' print(chr(97)) #'a'
print(dict()) #{} print(dict(k1 = 'v1', k2 = 'v2')) #{'k1': 'v1', 'k2': 'v2'} print(dict((['k1', 'v1'], ['k2', 'v2']))) #{'k1': 'v1', 'k2': 'v2'} print(dict({'k1':'v1', 'k2':'v2'})) #{'k1': 'v1', 'k2': 'v2'}
print(dir("")) #['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
print(divmod(10, 3)) #(3, 1) 返回两个数的得商和余数组成的元组,相当于(a // b, a % b)
enu = enumerate(['abc', 'def', 'ghi']) print(enu) for i in enu print(i) ''' 返回一个迭代器,每次迭代返回一个元组包括一个计数器,和对iterable迭代取得的值,iterable可迭代对象,包括列表、元祖等。start表示计数器的开始值,默认是0 执行结果 <enumerate object at 0x0000000BE2D53510> # 可以看到返回的是一个enumerate对象 (0, 'abc') (1, 'def') (2, 'ghi') ''' #注意:返回的是是一个迭代器,迭代完了空了,如果需要重复使用,最好转化为一个列表对象保存到变量中,并且计数器是从0开始计数的 li = list(enumerate(['abc', 'def', 'ghi'])) print(li) #[(0, 'abc'), (1, 'def'), (2, 'ghi')] #还可以指定start的开始值 li = list(enumerate(['abc', 'def', 'ghi'], 2)) print(li) #[(2, 'abc'), (3, 'def'), (4, 'ghi')]
print(eval('3 + 4 * (1 - 3)')) #-5 #将的字符串形式的算数表达式进行计算,并返回结果
def func(num): if num % 2 ==0: return True else: return False nums = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19] print(list(filter(func, nums))) ''' 接收一个函数和一个可迭代对象,将可迭代对象的每一个元素都作为参数执行函数,函数返回为真的放到一个新的可迭代对象中,并将新的可迭代对象返回 执行结果 [2, 4, 6, 8, 10, 12, 14, 16, 18] '''
print('0.5') #0.5 print(0.5) #0.5 #创建一个浮点类型的对象
#返回某个对象的帮助信息
print(hex(23)) #'0x17' #返回一个整数的16进制表达式
print(id(1)) #10455040 #返回对象的id(可以理解为Python为每个对象的编号,或者理解为是Python对象内存地址的表达形式)
s = input('python>>') print(s) ''' 输入123 输出'123' 接受用户从控制台的输入,并将用户输入的信息,以字符串的返回,prompt表示输入时前显示的字符串 '''
print(int()) #0 print(int('1010', base=2)) #10 #创建一个整数类型的对象,默认如果创建的0,如果传递的是字符串类型的,可以把字符串表达式所表示的整数转化为整数类型,base表示的传递的字符串进制,默认是十进制
print(len('abc')) #3 #返回一个对象的长度(或者元素的个数) #所谓的长度一般只字符串,像整数、浮点数等数据类型没有len方法
print(list([1, 2, 3])) #[1, 2, 3] prnt(list({'k1':'v1', 'k2':'v2'})) #['k2', 'k1'] #将一个可迭代对象转化为列表 #可以看到字典只是把key组成了列表,因为字典真正迭代的是key,value只是与key对应而已
s = map(lambda x: x**2, [1, 2, 3]) print(s) #<map object at 0x0000000002D14CF8> l = list(map(lambda x: x**2, [1, 2, 3])) print(l) #[1, 4, 9] #接收一个函数和一个可迭代对象,将可迭代对象里的每一个元素都做作为参数传递到函数中,并把函数的返回结果保存到一个map对象中 #函数可以是匿名函数,另外函数必须有返回值,如果没有返回值,虽然不会报错,但没有任何意义,例如
print(max(1, 2, 3)) #3 ''' max(iterable, *[, key, default]) max(arg1, arg2, *args[, key]) 返回可迭代对象中(或者2个以上参数中)最大的值 '''
print(min(1, 2, 3)) #1 ''' min(iterable, *[, key, default]) min(arg1, arg2, *args[, key]) 返回可迭代对象中(或者2个以上参数中)最大的值 '''
print(oct(9)) #'0o11' #将一个数转化为8进制的表达形式 Python中0o表示8进制
''' open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None) 打开文件并返回文件文件对象,file表示文件名(可以是绝对路径,也可以是相对路径),mode表示打开方式,默认的是rt模式,表示只读的文本格式 '''
print(ord('a')) #97 #返回一个字符的Unicode编码
print(pow(2, 3) ) #8 print(pow(2, 3, 3)) #2 #如果只传递两个参数x和y,就计算x的y次方,相当于x ** y #参数z表示将x ** y的结果对z取模,相当于x ** y % z
''' print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False) 打印函数,object表示要输出的对象,sep表示多个对象之间的分隔符,默认是空格,end表示末尾的字符,默认是回车符,file表示输出的文件,默认为sys.stdout也就是终端(标准输出) '''
print(list(range(1, 10))) #[1, 2, 3, 4, 5, 6, 7, 8, 9] print(list(range(1, 10, 2))) #[1, 3, 5, 7, 9] print(list(range(5)) #[0, 1, 2, 3, 4] ''' range(stop) range(start, stop[, step]) 生成大于等于start,小于stop步长为step的数字序列,start默认是0 '''
print(reversed([0, 1, 2, 3, 4])) #<list_reverseiterator object at 0x7fcc954acd68> print(list(reversed([0, 1, 2, 3, 4]))) #[4, 3, 2, 1, 0] #翻转一个序列,序列对象必须是有序的,也就是对象必须包含__reversed__()方法
print(round(1.236, 2)) #1.24 print(round(1.2, 2)) #1.2 #返回一个浮点数的后面保留ndigits位小数的结果,四舍五入,小数点位数不足,不补0
print(set(1, 2, 4, 2)) #{1, 2, 4} #根据序列对象创建集合对象
print(sorted(['A', 'b', 'c'])) #['A', 'b', 'c'] print(sorted(['A', 'b', 'C'])) #['A', 'C', 'b'] print(sorted(['A', 'b', 'C'], key = lambda x: x.lower()))#['A', 'b', 'C'] print(sorted(['A', 'b', 'C'], key = lambda x: x.lower(), reverse = True)) #['C', 'b', 'A'] #对一个序列对象进行排序,key接收一个函数,将序列的每一个函数处理返回的结果作为排序的依据,比如字符串都转换成小写排序或字典按照key或value排序等,reverse表示对排序的结果是否排序,默认字符串是先大写后小写的顺序排序的
print(str('abc')) #'abc' print(str(1234)) #'1234' #创建一个字符串对象,或者将一个对象转化为字符串对象
print(sum([1, 2, 4])) #7 print(sum([1, 2, 4], 1)) #8 #返回一个序列对象的相加的总和在加上start,start默认是0,序列对象要么全是数字要么都是字符串,字符串就相当于把它们都拼接在一起
print(tuple()) #() print(tuple([1, 2, 4])) #(1, 2, 4) #创建一个元组对象,或将一个对象转化为元组
print(type(1)) #<class 'int'> ''' class type(object) class type(name, bases, dict) 返回一个对象的类型 '''
import sys vars(sys) #{'version_info': sys.version_info(major=3, minor=4, micro=0, releaselevel='final', serial=0), 'getswitchinterval': <built-in function getswitchinterval>, '__name__': 'sys', 'path_hooks': [<class 'zipimport.zipimporter'>, <function FileFinder.path_hook.<locals>.path_hook_for_FileFinder at 0x7fcc97b51ae8>],后面省略n多行 #返回模块,类,实例或者任何其他有__dict__属性的对象的__dict__属性,默认是显示当前环境的
x = [1, 2, 3, 4] y = ['a', 'b', 'c'] print(zip(x, y)) #<zip object at 0x7fcc954aea08> print(list(zip(x, y))) #[(1, 'a'), (2, 'b'), (3, 'c')] #将多个元素组成一个新的zip对象,zip对象的元素个数取决于元素最少的参数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号