Ceph-部署
Ceph规划
| 主机名 | IP地址 | 角色 | 配置 |
|---|---|---|---|
| ceph_controler | 192.168.87.202 | 控制节点、MGR | Centos7系统500G硬盘 |
| ceph_node1 | 192.168.87.203 | mon,osd | Centos7系统500G硬盘、3块1T硬盘 |
| ceph_node2 | 192.168.87.204 | mon,osd | Centos7系统500G硬盘、3块1T硬盘 |
| ceph_node3 | 192.168.87.205 | mon,osd | Centos7系统500G硬盘、2块1T硬盘 |
系统环境配置
关闭Selinux和防火墙
需要在每台节点上操作
关闭Selinux
sed -i 's/SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
配置主机名
hostnamectl set-hostname ceph_controler
hostnamectl set-hostname ceph_node1
hostnamectl set-hostname ceph_node2
hostnamectl set-hostname ceph_node3
配置hosts解析
配置 hosts,并复制到其他两台主机
[root@ceph_controler ~]# vim /etc/hosts
192.168.87.203 ceph_controler
192.168.87.203 ceph_node1
192.168.87.204 ceph_node2
192.168.87.205 ceph_node3
[root@ceph_controler ~]# scp /etc/hosts ceph_node1:/etc/hosts
[root@ceph_controler ~]# scp /etc/hosts ceph_node2:/etc/hosts
[root@ceph_controler ~]# scp /etc/hosts ceph_node3:/etc/hosts
配置SSH免密
在控制节点上生成密钥,不设置密码
[root@ceph_controler ~]# ssh-keygen
将秘钥分别复制到ceph_controler, ceph_node1, ceph_node2, ceph_node3节点上
ssh-copy-id -i /root/.ssh/id_rsa.pub ceph_controler
ssh-copy-id -i /root/.ssh/id_rsa.pub ceph_node1
ssh-copy-id -i /root/.ssh/id_rsa.pub ceph_node2
ssh-copy-id -i /root/.ssh/id_rsa.pub ceph_node3
测试一下免密效果
ssh ceph_node1
ssh ceph_node2
ssh ceph_node3
配置时间同步服务器
在控制节点上搭建时间同步服务器
yum install chrony ntpdate -y ##每台节点都要安装
[root@ceph_controler ~]# vim /etc/chrony.conf
修改如下配置:
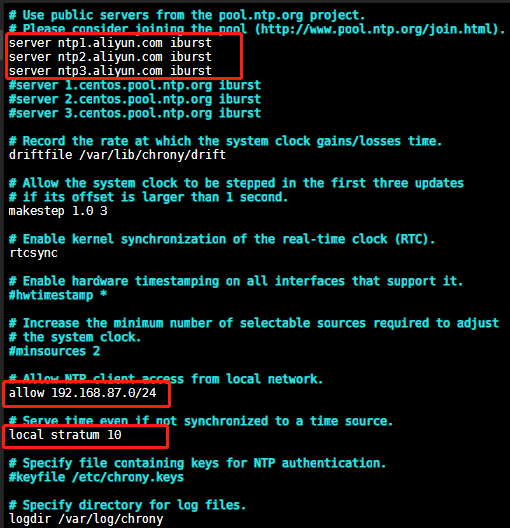
重启服务并设置开机自启
systemctl start chronyd && systemctl enable chronyd
在ceph_node1, ceph_node2, ceph_node3节点上安装chrony和ntpdate,并修改配置文件
[root@ceph_node1 ~]# yum install chrony ntpdate -y
[root@ceph_node1 ~]# vim /etc/chrony.conf ##修改时间服务器
server ceph_controler iburst
重启服务并设置开机自启:systemctl start chronyd && systemctl enable chronyd
同步时间:ntpdate 192.168.87.202
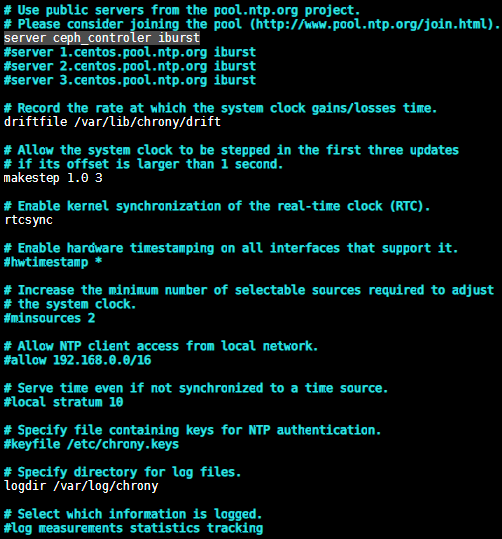
配置源
yum源
每台节点都要配置
cd /etc/yum.repos.d/
mkdir backup && mv C* backup
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
配置epel源
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
配置Ceph源
cat << EOF |tee /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/\$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[Ceph-source]
name=Ceph source packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
EOF
生成 yum 源缓存
yum clean all
yum makecache fast
部署Ceph
部署控制节点
集群部署
在ceph_controler节点上安装ceph-deploy和ceph包
[root@ceph_controler ~]# yum install ceph-deploy ceph -y
在ceph_node1,ceph_node2,ceph_node3节点上安装ceph包
[root@ceph_node1 ~]# yum install ceph -y
在 ceph_controler节点上创建一个cluster 目录,所有命令再此目录下进行操作
[root@ceph_controler ~]# mkdir /cluster ##此目录自定义
[root@ceph_controler ~]# cd /cluster
将 ceph_node1,ceph_node2,ceph_node3 加入集群
[root@ceph_controler cluster]# ceph-deploy new ceph_node1 ceph_node2 ceph_node3
[ceph_deploy.new][DEBUG ] Creating a random mon key...
[ceph_deploy.new][DEBUG ] Writing monitor keyring to ceph.mon.keyring...
[ceph_deploy.new][DEBUG ] Writing initial config to ceph.conf...
出现如上信息表示输出没有报错,部署成功
查看 ceph 版本
[root@ceph_controler cluster]# ceph -v
ceph version 14.2.22 (ca74598065096e6fcbd8433c8779a2be0c889351) nautilus (stable)
生成 mon 角色
[root@ceph_controler cluster]# ceph-deploy mon create-initial ###将所有节点作
为 mon 角色,可以指定那些节点为 mon 角色
生成ceph admin秘钥
[root@ceph_controler cluster]# ceph-deploy admin ceph_controler ceph_node1 ceph_node2 ceph_node3
部署 MGR,提供 web 界面管理 ceph(可选安装)
[root@ceph_controler cluster]# ceph-deploy mgr create ceph_controler ###将ceph_controler节点作为web界面管理,也可以将其他节点作为web界面管理
初始化OSD
ceph-deploy osd create --data /dev/sdb ceph_node1
ceph-deploy osd create --data /dev/sdc ceph_node1
ceph-deploy osd create --data /dev/sdd ceph_node1
ceph-deploy osd create --data /dev/sdb ceph_node2
ceph-deploy osd create --data /dev/sdc ceph_node2
ceph-deploy osd create --data /dev/sdd ceph_node2
ceph-deploy osd create --data /dev/sdb ceph_node3
ceph-deploy osd create --data /dev/sdc ceph_node3
查看OSD状态
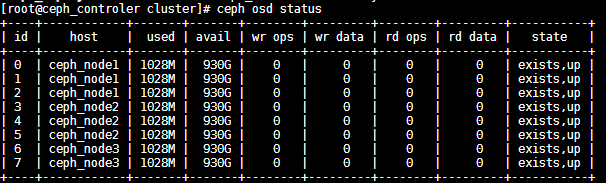
查看ceph状态
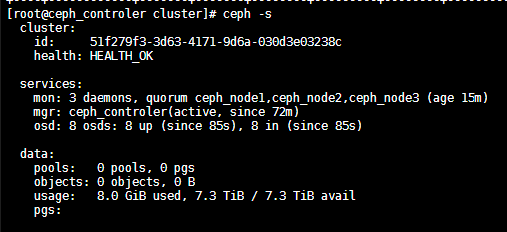
到此,整个 ceph 的部署就完成了,健康状态也是 ok 的。
Ceph 操作使用
创建存储池
ceph osd pool create it_pool 128 ###创建一个名为it_pool的池,PG大小为128
查看池的副本数
ceph osd pool get it_pool size
查看池的PG大小
ceph osd pool get it_pool pg_num
RBD使用
设置 it_pool 为 rbd,并创建卷,客户端进行挂载, 映射给业务服务器使用。
[root@ceph_controler ceph]# ceph osd pool application enable it_pool rbd ###设置存储池类型为 rbd
[root@ceph_controler ceph]# rbd create it_pool/disk1 --size 1T --image-feature layering ###在存储池里划分一块名为 disk1 的磁盘,大小为 1T的镜像
列出rbd设备镜像(可在任意一台节点上列出)
[root@ceph_controler ceph]# rbd ls
ceph-client1-rbd1
查看创建后的块设备的信息(可以在任意一台ceph节点上查看)
[root@ceph-node1 ~]# rbd --image ceph-client1-rbd1 info
rbd image 'ceph-client1-rbd1':
size 10240 MB in 2560 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.857a238e1f29
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
#### 配置web界面管理
yum install ceph-mgr-dashboard -y
ceph mgr module enable dashboard
ceph dashboard create-self-signed-cert
touch /etc/ceph/dashboard_passwd.txt
echo "xxxx" > /etc/ceph/dashboard_passwd.txt
ceph dashboard set-login-credentials admin -i /etc/ceph/dashboard_passwd.txt ###把密码写入到 /etc/ceph/dashboard_passwd.txt,名字随便写
ceph mgr services
ceph mgr module enable dashboard
客户端挂载:
安装 ceph 客户端:
Centos系统:yum install ceph -y
ubuntu系统:sudo apt install ceph -y
将服务端的 ceph.conf 和密钥文件拷贝到 ceph 客户端:
scp /etc/ceph/ceph.conf it@192.168.87.176:/etc/ceph/
scp /etc/ceph/ceph.client.admin.keyring it@192.168.87.176:/etc/ceph/
映射 rbd 块设备:
查看下该镜像支持了哪些特性
[root@ceph-client1 ~]# rbd info ceph-client1-rbd1
rbd image 'ceph-client1-rbd1':
size 10240 MB in 2560 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.857a238e1f29
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
可以看到特性feature一栏,由于我OS的kernel只支持layering,其他都不支持,所以需要把部分不支持的特性disable掉。
以下方法根据实际情况选其一即可!(我这里使用的是方式二)
【方法一:】直接diable这个rbd镜像的不支持的特性:
[root@ceph-client1 ~]# rbd feature disable ceph-client1-rbd1 exclusive-lock object-map fast-diff deep-flatten
[root@ceph-client1 ~]# rbd info ceph-client1-rbd1 #关闭后查看
rbd image 'ceph-client1-rbd1':
size 10240 MB in 2560 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.857a238e1f29
format: 2
features: layering #仅剩一个特性
flags:
【方法二:】在ceph集群中任意节点上创建rbd镜像时就指明需要的特性,如:
$ rbd create --size 10240 ceph-client1-rbd1 --image-feature layering
rbd create --size 10240 ceph-client1-rbd1 --image-feature layering exclusive-lock object-map fast-diff deep-flatten
【方法三:】修改Ceph配置文件/etc/ceph/ceph.conf,在global section下,增加
rbd_default_features = 1
再创建rdb镜像。
rbd create ceph-client1-rbd1 --size 10240
it@it:~$ sudo rbd map it_pool/disk1
查看映射信息
[root@ceph-client1 ~]# rbd showmapped
[root@ceph-client1 ~]# sudo fdisk -l 查看映射盘


磁盘分区挂载:
fdisk /dev/rbd0
mkfs.ext4 /dev/rbd0
mount /dev/rbd0 /mnt/
取消映射块设备:
[root@ceph-client1 ~]# umount /mnt/ceph-vol1/ #取消挂载
[root@ceph-client1 ~]# rbd unmap /dev/rbd/rbd/ceph-client1-rbd1 #取消映射
[root@ceph-client1 ~]# rbd showmapped #查看是否取消成功,如没有任何输出则表示取消映射成功
如下删除块设备,执行以下命令
[root@ceph-node1 ~]# rbd rm ceph-client1-rbd1
Removing image: 100% complete...done.
[root@ceph-node1 ~]# rbd ls
cephfs
部署cephfs
[root@ceph_node1 cluster]# ceph-deploy mds create ceph_node1 ceph_node2 ceph_node3
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy mds create ceph_node1 ceph_node2 ceph_node3
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fb889afe2d8>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func : <function mds at 0x7fb889b3ced8>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] mds : [('ceph_node1', 'ceph_node1'), ('ceph_node2', 'ceph_node2'), ('ceph_node3', 'ceph_node3')]
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.mds][DEBUG ] Deploying mds, cluster ceph hosts ceph_node1:ceph_node1 ceph_node2:ceph_node2 ceph_node3:ceph_node3
[ceph_node1][DEBUG ] connected to host: ceph_node1
[ceph_node1][DEBUG ] detect platform information from remote host
[ceph_node1][DEBUG ] detect machine type
[ceph_deploy.mds][INFO ] Distro info: CentOS Linux 7.9.2009 Core
[ceph_deploy.mds][DEBUG ] remote host will use systemd
[ceph_deploy.mds][DEBUG ] deploying mds bootstrap to ceph_node1
[ceph_node1][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_node1][WARNIN] mds keyring does not exist yet, creating one
[ceph_node1][DEBUG ] create a keyring file
[ceph_node1][DEBUG ] create path if it doesn't exist
[ceph_node1][INFO ] Running command: ceph --cluster ceph --name client.bootstrap-mds --keyring /var/lib/ceph/bootstrap-mds/ceph.keyring auth get-or-create mds.ceph_node1 osd allow rwx mds allow mon allow profile mds -o /var/lib/ceph/mds/ceph-ceph_node1/keyring
[ceph_node1][INFO ] Running command: systemctl enable ceph-mds@ceph_node1
创建cephfs pool池
CephFS相关命令 需要创建2个pool池
1.创建MDS Daemon
ceph-deploy mds create <…>
2.创建CephFS Data Pool
ceph osd pool create <…>
3.CephFS Metadata Pool
ceph osd pool create <…>
4.创建CephFS
ceph fs new <…>
5.查看CephFS
ceph fs ls
name: tstfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
6.删除CephFS
ceph fs rm <fs-name> --yes-i-really-mean-it
7.查看MDS状态
ceph mds stat
e8: tstfs-1/1/1 up tstfs2-0/0/1 up {[tstfs:0]=mds-daemon-1=up:active}
• e8
o e表示epoch
o 8是epoch号
• tstfs-1/1/1 up
o tstfs是cephfs名字
o 三个1分别是 mds_map.in/mds_map.up/mds_map.max_mds
o up是cephfs状态
• {[tstfs:0]=mds-daemon-1=up:active}
o [tstfs:0]指tstfs的rank 0
o mds-daemon-1是服务tstfs的mds daemon name
o up:active是cephfs的状态为 up & active
客户端挂载
安装ceph-fuse
下载ceph epel源包
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
安装ceph
yum install ceph ceph-fuse -y
挂载CeophFS
# scp /etc/ceph/ceph.client.admin.keyring 10.65.3.83:/etc/ceph
mkdir /data/cephfs
ceph-fuse -m 10.65.3.76:6789 /data/cephfs
卸载挂载
fusermount -u /mntdir
centos7里没有fusermount命令,可以用umount替代
扩容OSD
在控制节点操作
1.初始化硬盘
ceph-deploy disk zap ceph-node-11 /dev/sdc
2.加入新的osd
ceph-deploy osd create ceph-node-11 --data /dev/sdc
3.查看扩容后的信息
ceph osd status
扩容rbd
在控制节点操作
1.查看当前rbd大小
rbd info mypool1/disk10
2. 扩容rbd
rbd resize --size 10240 mypool1/disk10
3.查看扩容后的rbd大小
rbd info mypool1/disk10
扩容OSD节点
在node节点操作
1、系统初始化
同”四.初始化”一样
2、安装cepe
yum -y install ceph-deploy ceph
3、在控制节点操作
ceph-deploy install --no-adjust-repos ceph_node4 ##添加新node节点
ceph-deploy admin ceph_node4 ##授权
ceph-deploy --overwrite-conf config push ceph_node1 ceph_node2 ceph_node3 ceph_node4 ceph_node5 ceph_controler
ceph status
##初始化硬盘
ceph-deploy osd create --data /dev/sdb ceph_node4
ceph-deploy osd create --data /dev/sdb ceph_node4
ceph-deploy osd create --data /dev/sdc ceph_node4
ceph-deploy osd create --data /dev/sdd ceph_node4
##查看硬盘状态
创建osd
# ceph-deploy osd create --data /dev/sdb $HOSTNAME
(报错“error: GPT headers found, they must be removed on: /dev/sdb”,使用“# sgdisk --zap-all /dev/sdb”解决)
删除osd(0为osd的号码)
# systemctl stop ceph-osd@0
# ceph osd purge osd.0 --yes-i-really-mean-it
删除lvm
# lvdisplay 查看
# lvremove /dev/ceph-265dddd7-ef18-42f7-869e-58e669638032/osd-data-3fa4b9df-6a59-476a-8aaa-4138b29acce9 删除
# ceph-deploy disk zap $HOSTNAME /dev/sdb 格式化磁盘
ceph osd status
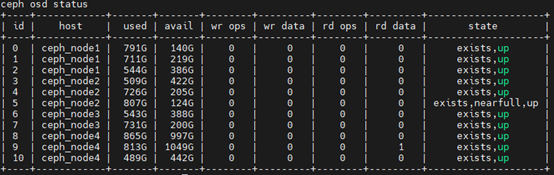
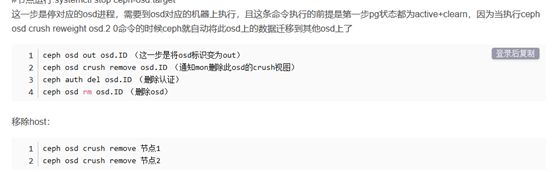
删除节点
避坑指南
Q1:
root@ceph_node1 cluster]# ceph-deploy new ceph_node1 ceph_node2 ceph_node3
Traceback (most recent call last):
File "/usr/bin/ceph-deploy", line 18, in <module>
from ceph_deploy.cli import main
File "/usr/lib/python2.7/site-packages/ceph_deploy/cli.py", line 1, in <module>
import pkg_resources
ImportError: No module named pkg_resources
解决方法:yum install python2-pip
Q2:
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
解决方法:ceph config set mon auth_allow_insecure_global_id_reclaim false
Q3:

解决方法:
可以看到, 新增的硬盘中发现了 GPT 分区表, 所以添加失败了, 我们要手动清理掉硬盘的分区表 (当然如果硬盘是全新的, 这里应该就成功了).
这里我们直接暴力干掉分区表, 不用费事的操作 PV 和 VG 了.
注意, 一定要再三检查目标硬盘是否是期望的硬盘, 如果操作错了硬盘, 分区表直接就没了.
[root@storage03-ib ceph-9]# dd if=/dev/zero of=/dev/sde bs=512K count=1
1+0 records in
1+0 records out
524288 bytes (524 kB) copied, 0.00109677 s, 478 MB/s
利用 dd 命令把硬盘的前 512K 填充为 0, 直接干掉分区信息.
注意如果这块盘之前已经挂载了, 那需要重启才能生效.
然后重新添加 OSD:
ceph-deploy osd create --data /dev/sdb ceph_node2
Q4:
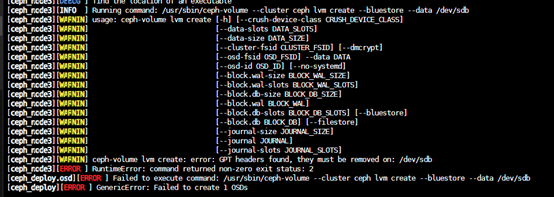
解决方案
1:parted -s /dev/sdb mklabel gpt mkpart primary xfs 0% 100%
2:reboot
3:mkfs.xfs /dev/sdb -f
Q5:
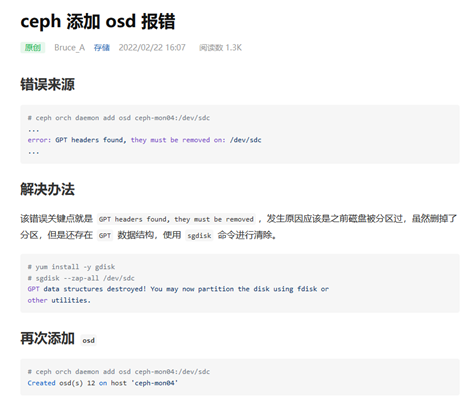
Q6:PG报错修复
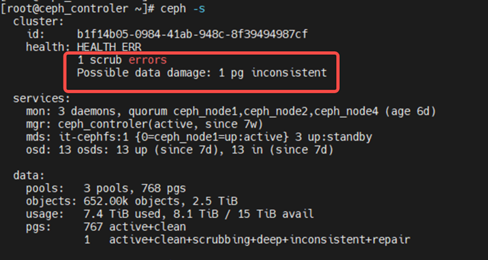
(1)、查看ceph详细信息
[root@ceph_controler ~]# ceph health detail
(2)、修复PG
[root@ceph_controler ~]# ceph pg repair 3.52
instructing pg 3.52 on osd.5 to repair
(3)、修复PG中的3块OSD
[root@ceph_controler ~]# ceph osd repair 5
instructed osd(s) 5 to repair
[root@ceph_controler ~]# ceph osd repair 10
instructed osd(s) 10 to repair
[root@ceph_controler ~]# ceph osd repair 6
instructed osd(s) 6 to repair

控制节点关机重启后需要重新将ceph.conf,想推送到所有其他节点
ceph-deploy --overwrite-conf config push ceph_node1 ceph_node2
Q7:PG故障修复
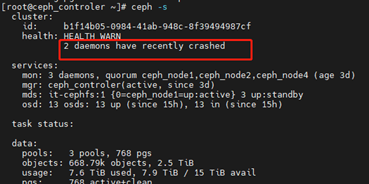
1、产生该问题的原因是数据在均衡或者回滚等操作的时候,导致其某个守护进程崩溃了,且没有及时归档,所以集群产生告警
2、解决方法:
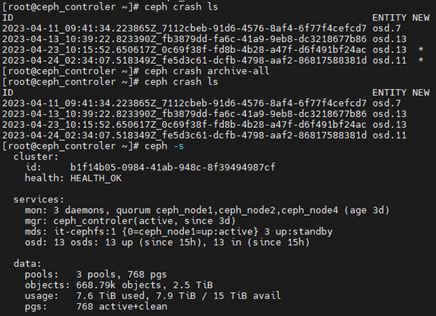
[root@ceph_controler ~]# ceph crash ls
ID ENTITY NEW
2023-04-11_09:41:34.223865Z_7112cbeb-91d6-4576-8af4-6f77f4cefcd7 osd.7
2023-04-13_10:39:22.823390Z_fb3879dd-fa6c-41a9-9eb8-dc3218677b86 osd.13
2023-04-23_10:15:52.650617Z_0c69f38f-fd8b-4b28-a47f-d6f491bf24ac osd.13 *
2023-04-24_02:34:07.518349Z_fe5d3c61-dcfb-4798-aaf2-86817588381d osd.11 *
[root@ceph_controler ~]# ceph crash archive <id>
或者
[root@ceph_controler ~]# ceph crash archive-all
3、查看集群状态

 浙公网安备 33010602011771号
浙公网安备 33010602011771号