
程序员必知的“大数据”基础知识!
当今这个时代,我相信大部分人对“大数据”这三个字肯定都不陌生,或多或少都有接触过,例如大数据杀熟。
对我们程序员来说,仅仅知道或听过一些名词是不够的,至少需要知晓其中大概的原理,并且对常见的大数据组件有一定的认识,不说拿出去吹牛,至少也要听得懂别人吹牛。
今天这篇文章就简单介绍下大数据的用途,大数据的核心处理过程,以及常见组件的用处。
简单了解下大数据能做什么
大数据能做的东西有很多,涉及的领域也很多:
- 汽车领域的自动驾驶等;
- 医疗领域的病情识别等;
- 金融领域的风控、量化交易等;
- 教育领域的 AI 教育,智能识题等;
- 推荐系统;
- 疫情筛查;
- 等等……
可以说,数据就是宝藏。
以前由于软硬件的约束,大量的数据放在那里,没法发光发热。现在随着科技不断地发展,可以看到大数据已经深入到我们生活当中。
大数据计算原理
其实大数据的核心思想其实就是分而治之。
说白了,如果是小数据量的计算,我们直接写个代码在单机上跑跑就搞定了,但是涉及到大量的数据,例如 PB 级别及以上这类,一台机器完全 hold 不过来,第一问题是存储,第二问题是计算时长。
而我们所说的大数据,其实就是利用技术组合起很多便宜的服务器来并行处理大量的数据,实现大数据的分析和计算,这就是大数据计算的核心。
利用这种分而治之的思想,提升了计算和存储的能力,再结合深度学习等技术,大数据就迎来了爆发式的增长。
一般我们谈到大数据,关于技术向的都离不开 Hadoop 体系及其衍生的工具,Hadoop 体系其核心就是 HDFS 和 MapReduce。
HDFS
前面提到,计算可能需要涉及大量的数据,可能都是 PB 级别的,普通单机的磁盘无法存储那么多数据,因此就需要分布式文件存储,组合起众多廉价的服务器,让每个服务器存储部分数据,对外展示却看起来是一个文件,这就是分布式文件存储。
对 Hadoop 家族来说,就是 HDFS:Hadoop Distributed File System,这是存储的基石。
MapReduce
存储的问题解决了,紧接着就是计算了,这就是大数据计算框架 MapReduce 的工作。
MapReduce 的原理其实非常简单,它包含两个过程:map 和 reduce。
比如现在我要统计关注公众号的每个地域读者人数。
那么 map 的过程就先根据地域进行计算,根据每个读者的属性得到一个 <key,value>,比如 <杭州,1>、<上海,1>、<杭州,1>、<北京,1>。
然后再把这些 <key,value> 发给 reduce 程序,reduce 的逻辑是根据 key 进行累加统计,得到结果 <杭州,2>、<上海,1>、<北京,1>。
看到这个可能有人会有疑惑,这跟大数据有什么关系?
其实,这些计算程序会分发到多台服务器上并行执行。
也就是说我们只需定义 map 和 reduce 的处理逻辑,然后提交给 hadoop 系统,然后 map 和 reduce 的计算逻辑就会分发到我们部署的各个计算节点(机器)上(机器会下载代码,通过反射执行)。
每个被分配到的计算节点上就会运行 map 和 reduce 的代码逻辑来处理数据,并且每个机器处理的也只是部分数据。
比如这个 map 程序分配了 5 台机器,一同要处理 1 亿条数据,很可能机器 A 就处理前 2 千万条数据,机器 B 处理 2 千万到 4 千万的数据,依次类推。
然后 reduce 也有 5 台,分别统计不同 map 机器的输入,如下图所示(抽象画了 HDFS,实际可能就在本地机器):
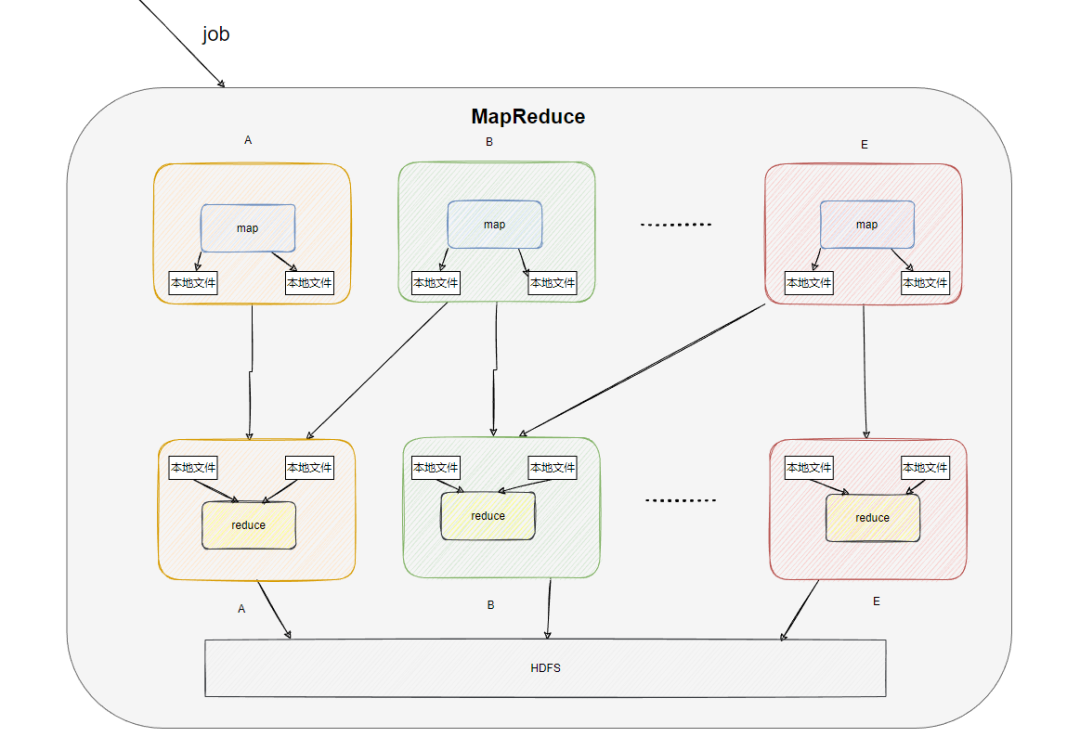
这样算力就平摊到多台机器上并行执行,效率就快了,时间就缩短了。
如果计算的数据量大,也可以通过更多的机器来减少计算时间,这就是分而治之的思想。
看到这里肯定有同学有点小疑惑,有多台服务在 reduce 那如何保证统计的正确?比如 key 是杭州的数据部分发给了 A,部分发给了 B,难道后面还有个统计阶段吗?
不是的,其实还有个 shuffle 过程,就是 MapReduce 框架会把相同的 key 发给同一台机器进行 reduce,从而避免上面说的这个情况。
大数据相关组件
了解了大体的核心技术后,我们再来看看相关的组件。
Hbase
一个列式存储的 NoSQL 数据库,底层利用 HDFS 存储。
在存储数据量大的情况下也不会影响读取写入的效率,由于列式存储,没有固定的表结构,可以动态增加列,非常灵活。
当然还有其他列式存储,这里就不介绍了。
Hive
前面我们提到 MapReduce,要用上这个计算框架是要写代码的,这对于一些运营或产品来说成本就有点高。
于是就出了个 Hive,支持类 SQL 语句,不需要显示编写 map 和 reduce 的代码,仅仅写个 SQL, Hive 就可以把这个 SQL 转成对应的 MapReduce 代码,然后执行返回结果,降低了使用成本,是个好东西。
Spark
MapReduce 虽然好用,但是因为它使用磁盘作为存储介质保存中间结果,且阶段性的计算每执行一次 Map 和 Reduce 计算都需要重新启动一次作业,在很多需要迭代计算的作业中,就有点拉胯了。
因此搞了个叫 Spark 的并行计算框架来替换之,它的目标就是低延迟,它使用内存来保存中间结果。
Flink
我们前面提到的 MapReduce 其实是批处理计算,也就是离线计算,比如统计最近一年的 xxx 数据。
而当前有很多需求要的是实时计算,比如数据大屏的实时展示等,这就需要大数据的流式计算,在这个领域比较出名的就是 Flink。
Flink 是面向流式计算设计的(也支持批处理),虽说 Spark 也支持流式计算(Spark Streaming),不过它的流其实是把批处理分割得很小来看作流,不是那么“正统”,而 Flink 就是面向流设计的。
关于离线和实时计算两个显著区别是:离线计算的数据是有界的,而实时计算的数据是无界的,且离线的数据是静态的,而实时的数据是动态的。
关于流式计算还有 Storm,这里不多介绍了。
Kafka
大数据的计算和存储我们都提了,那么数据怎么传到大数据计算引擎中来呢?
Kafka 登场了,我们都知道它是消息队列,它主要用于数据的传输,还有削峰填谷,平衡数据的发送和接收速率,在大数据场景下有很多应用。
Flume
还有一个数据来源就是日志,我们有很多数据都会通过日志保存在服务器的磁盘上,而 Flume 就是一个日志采集工具,负责日志的采集,然后输入到不同的数据源中。
最后
好了,关于大数据体系的一些基础知识,简单了解到这个地步就差不多了。
其实还有很多组件没提,比如分布式集群资源调度框架 Yarn,主要进行集群资源分配,还有数据库的 ETL 工具 sqoop,分布式协调组件 zookeeper 等等。
总结的图我直接从网上找了个比较全的,大家可以结合上面的介绍理解一下。

这些东西包括里面的一些细节还是需要大家后面自行去查阅资料了解的,本文仅仅只是科普大数据主要的核心体系,让大家看到 hive 之类的单词,至少明白它是干嘛的,仅此而已。
转自https://mp.weixin.qq.com/s/NizhyyM18-qGr55BSFLXqw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号