
Redis集群HA(上)
作为nosql领域最火之一的redis内存数据库,它的高可用集群一直是一个比较受关注的点,redis本身一直说的要支持集群功能直到3.0之后才正式推出。本次将分上下篇分析一下目前redis常见的一些集群方案。上篇会介绍一些基本方案的实现原理,下篇会主要介绍豌豆荚推出的codis。
redis目前主要有以下几种集群方案:
1、 通过客户端来实现一致性哈希;
2、 将一致性哈希策略实现放在中间的proxy层;
3、 Redis自带的集群功能;
背景
通常,我们在使用redis的时候,不会只部署单台服务器,而是部署多台redis服务器,从而将数据存储到不同的机器上面,减轻单台服务器的访问压力。一般而言,我们是通过以下策略进行哈希的。

其中,dest就是对这个key分配的redis服务器。N是集群的redis服务器数目。但是,上述的哈希策略,会导致以下两个问题:
1、业务量突然增加,现有服务器不够用。增加服务器节点后,依然通过上面的计算方式做数据分片和分发,但之前的 key 会被分发到与之前不同的服务器上,导致大量的数据失效,需要重新写入(set)Redis 服务器;
2、其中的一个服务器挂了。如果不做及时的修复,大量被分发到此服务器请求都会失效;
一致性哈希就是为了解决上述两个问题而提出的,大概思路是:
1、 首先假定一个节点的环,将集群的节点hash(一般是ip+端口号)到这个环上;
2、 每次访问的时候对key进行哈希,然后找顺时针最近的一台服务器用于提供访问;
从上面的过程可以看到,当增加服务器或者移除服务器只会导致部分数据的访问失效,可以减轻服务压力。但是也可能出现一个极端问题,就是如下情况:

C突然失效,导致A的压力倍增然后挂掉,B的压力也迅速增大导致整个服务停掉。所以,为了避免这种问题的出现,就出现了虚拟节点的概念。如下图所示:

增加了3个虚拟节点,这样C挂掉之后,不会全部的请求都指向了A。可以达到负载均衡的目的。
一致性哈希用来实现访问的负载均衡,考虑到集群中节点可能会出故障,redis提供哨兵机制,来检测redis服务器的状态。下面简单分析一下redis哨兵机制的实现原理。
Redis Sentinel
启动sentinel是通过redis-server –sentinel命令实现的。其实本质上就是传递这个参数到main函数,main函数根据参数来初始化sentinel服务器。首先看下redis server的数据结构:

再初始化的时候,会根据参数来判断是否是初始化一个sentinel redis服务器:

如果是的话,redisserver结构体里面的sentinel mode就是true了。然后是init sentinel函数,用于初始化sentinel服务器锁需要的配置。

可以看到,redis sentinel只会处理7中命令:

这就是redis sentinel的初始化过程。可以看到sentinel结构中维护了一个masters字段,这里每一个master一个sentinelRedisInstance实例,部分代码如下:

这个实例包含了这台sentinel服务器连接的redis服务器,slave服务器以及其他sentinel服务器的信息。具体这里就不做分析了。
下面简单分析下redis sentinel是怎么和masters建立连接的。

首先,在redis的aeEventLoop中,会处理一个serverCon定时事件,假如是redis sentinel,那么会定时处理上图的sentinelTimer事件,在这个事件当中,调用sentinelHandleDictOfRedis事件,接下来调用sentinelHandleRedisInstance事件,在这个事件中,会处理连接redis服务器,发心跳包,发现故障机器等事件。

通过上述大概过程,对redis sentinel哨兵机制有了初步了解,而这也是redis master-slave故障恢复的一个重要的机制。在redis 集群当中也有很广泛的应用。当然,更深入的细节,可以参考源码,show me the code嘛!
下面开始介绍redis集群的实现方案。
客户端实现
一般思路如下:(客户端实现一致性哈希+redis 监控)
1、 对集群的redis 物理节点进行hash,映射到固定数目的虚拟节点中
2、 将物理节点与虚拟节点关联起来
3、 通过redis sentinel来实现监控,降低单点故障的概率
下面以java客户端jedis的实现来做简单的介绍:

Redis服务器节点划分:将每台服务器节点采用hash算法划分为160个虚拟节点(可以配置划分权重)
(1)将划分虚拟节点采用TreeMap存储
(2)对每个Redis服务器的物理连接采用LinkedHashMap存储
(3)对Key or KeyTag 采用同样的hash算法,然后从TreeMap获取大于等于键hash值得节点,取最邻近节点存储;当key的hash值大于虚拟节点hash值得最大值时,存入第一个虚拟节点
以上逻辑是在Sharded类中进行实现的,ShardedJedis类实现了jedisCommonds接口,我们一般使用ShrdedJedisPool来进行ShardedJedis的初始化。然后每次从pool中取一个客户端对象,就能分布式的访问不同的redis服务器。
代理实现
代理实现redis集群机制,就是通过在proxy层来实现一致性哈希,同时代理层去实现动态检测节点增加,节点退出。这样,就让能避免客户端实现中每次集群更新都得重新启动所有客户端的缺点。
通过代理来实现redis集群,目前比较著名的是twwiter的Twemproxy。也是类似于redis,采用事件驱动型,来处理高并发的请求。基本模型如下图:
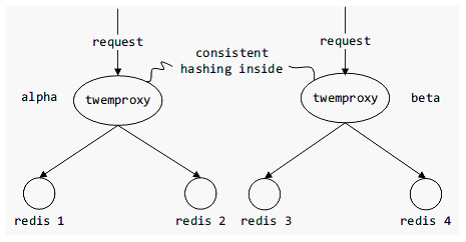
通过redis sentinel可以实现故障恢复

所以,现在通过代理来实现集群方案的话,可以选择proxy+sentinel的方案作为基本架构。当然,豌豆荚推出的codis也是基于代理的,但是它们的实现有些不一样,这个等到下篇再详细介绍。
Redis Cluster
Redis 集群采用的是无中心节点的架构,互联图如下所示:

Redis 集群涉及的数据结构主要是clusterNode和clusterState:


如何处理命令?
ClusterNode中维护了一个slots字段,是该节点能够处理的slot,类似于哈希中的bucket。
同时,每个节点能够掌握其他节点处理的slot,所以每次命令过来,如果当前server能够处理,就会直接处理掉,不能处理会类似于http请求的301状态码,发一个redirect ip给客户端,客户端再重新向这个ip发起数据访问请求。
当然,这里有个不好的地方就是会可能每个命令都要请求两次,时间上会比较慢。但是,客户端可以先获取到各个节点处理的slot再发送命令。为了避免,slot变更,可以客户端设置定时器来定时的刷新各个节点处理的slot信息。
如何加载节点并且感知其他节点?
clusterState结构当中,保存了所有节点的哈希表信息。集群启动的时候,通过clusterLoadConfig来实现从配置文件中加载集群节点信息的目的:
int clusterLoadConfig(char *filename) { FILE *fp = fopen(filename,"r"); struct stat sb; char *line; int maxline, j; if (fp == NULL) { if (errno == ENOENT) { return REDIS_ERR; } else { redisLog(REDIS_WARNING, "Loading the cluster node config from %s: %s", filename, strerror(errno)); exit(1); } } /* Check if the file is zero-length: if so return REDIS_ERR to signal * we have to write the config. */ if (fstat(fileno(fp),&sb) != -1 && sb.st_size == 0) { fclose(fp); return REDIS_ERR; } /* Parse the file. Note that single lines of the cluster config file can * be really long as they include all the hash slots of the node. * This means in the worst possible case, half of the Redis slots will be * present in a single line, possibly in importing or migrating state, so * together with the node ID of the sender/receiver. * * To simplify we allocate 1024+REDIS_CLUSTER_SLOTS*128 bytes per line. */ maxline = 1024+REDIS_CLUSTER_SLOTS*128; line = zmalloc(maxline); while(fgets(line,maxline,fp) != NULL) { int argc; sds *argv; clusterNode *n, *master; char *p, *s; /* Skip blank lines, they can be created either by users manually * editing nodes.conf or by the config writing process if stopped * before the truncate() call. */ if (line[0] == '\n') continue; /* Split the line into arguments for processing. */ argv = sdssplitargs(line,&argc); if (argv == NULL) goto fmterr; /* Handle the special "vars" line. Don't pretend it is the last * line even if it actually is when generated by Redis. */ if (strcasecmp(argv[0],"vars") == 0) { for (j = 1; j < argc; j += 2) { if (strcasecmp(argv[j],"currentEpoch") == 0) { server.cluster->currentEpoch = strtoull(argv[j+1],NULL,10); } else if (strcasecmp(argv[j],"lastVoteEpoch") == 0) { server.cluster->lastVoteEpoch = strtoull(argv[j+1],NULL,10); } else { redisLog(REDIS_WARNING, "Skipping unknown cluster config variable '%s'", argv[j]); } } sdsfreesplitres(argv,argc); continue; } /* Regular config lines have at least eight fields */ if (argc < 8) goto fmterr; /* Create this node if it does not exist */ n = clusterLookupNode(argv[0]); if (!n) { n = createClusterNode(argv[0],0); clusterAddNode(n); } /* Address and port */ if ((p = strrchr(argv[1],':')) == NULL) goto fmterr; *p = '\0'; memcpy(n->ip,argv[1],strlen(argv[1])+1); n->port = atoi(p+1); /* Parse flags */ p = s = argv[2]; while(p) { p = strchr(s,','); if (p) *p = '\0'; if (!strcasecmp(s,"myself")) { redisAssert(server.cluster->myself == NULL); myself = server.cluster->myself = n; n->flags |= REDIS_NODE_MYSELF; } else if (!strcasecmp(s,"master")) { n->flags |= REDIS_NODE_MASTER; } else if (!strcasecmp(s,"slave")) { n->flags |= REDIS_NODE_SLAVE; } else if (!strcasecmp(s,"fail?")) { n->flags |= REDIS_NODE_PFAIL; } else if (!strcasecmp(s,"fail")) { n->flags |= REDIS_NODE_FAIL; n->fail_time = mstime(); } else if (!strcasecmp(s,"handshake")) { n->flags |= REDIS_NODE_HANDSHAKE; } else if (!strcasecmp(s,"noaddr")) { n->flags |= REDIS_NODE_NOADDR; } else if (!strcasecmp(s,"noflags")) { /* nothing to do */ } else { redisPanic("Unknown flag in redis cluster config file"); } if (p) s = p+1; } /* Get master if any. Set the master and populate master's * slave list. */ if (argv[3][0] != '-') { master = clusterLookupNode(argv[3]); if (!master) { master = createClusterNode(argv[3],0); clusterAddNode(master); } n->slaveof = master; clusterNodeAddSlave(master,n); } /* Set ping sent / pong received timestamps */ if (atoi(argv[4])) n->ping_sent = mstime(); if (atoi(argv[5])) n->pong_received = mstime(); /* Set configEpoch for this node. */ n->configEpoch = strtoull(argv[6],NULL,10); /* Populate hash slots served by this instance. */ for (j = 8; j < argc; j++) { int start, stop; if (argv[j][0] == '[') { /* Here we handle migrating / importing slots */ int slot; char direction; clusterNode *cn; p = strchr(argv[j],'-'); redisAssert(p != NULL); *p = '\0'; direction = p[1]; /* Either '>' or '<' */ slot = atoi(argv[j]+1); p += 3; cn = clusterLookupNode(p); if (!cn) { cn = createClusterNode(p,0); clusterAddNode(cn); } if (direction == '>') { server.cluster->migrating_slots_to[slot] = cn; } else { server.cluster->importing_slots_from[slot] = cn; } continue; } else if ((p = strchr(argv[j],'-')) != NULL) { *p = '\0'; start = atoi(argv[j]); stop = atoi(p+1); } else { start = stop = atoi(argv[j]); } while(start <= stop) clusterAddSlot(n, start++); } sdsfreesplitres(argv,argc); } /* Config sanity check */ if (server.cluster->myself == NULL) goto fmterr; zfree(line); fclose(fp); redisLog(REDIS_NOTICE,"Node configuration loaded, I'm %.40s", myself->name); /* Something that should never happen: currentEpoch smaller than * the max epoch found in the nodes configuration. However we handle this * as some form of protection against manual editing of critical files. */ if (clusterGetMaxEpoch() > server.cluster->currentEpoch) { server.cluster->currentEpoch = clusterGetMaxEpoch(); } return REDIS_OK; fmterr: redisLog(REDIS_WARNING, "Unrecoverable error: corrupted cluster config file."); zfree(line); if (fp) fclose(fp); exit(1); }
同时,redis管理员可以通过meet命令来手动的加入redis节点。
通过clusterStartHandshake函数来实现节点之间的握手,同时加入到自身的哈希表当中。这样节点就能知道集群中其他节点的信息
如何检测其他节点?
通过心跳机制来实现。众所周知,redis之所以并发高是采用了基于reactor模式的异步
IO机制。在事件循环中,处理定时事件和文件事件。在redis集群中,也有一个定时事件,ClusterCon,来处理节点之间的ping,信息交换等。
如何进行故障恢复?
ClusterCon 函数中,会定时的调用clusterHandleManualFailover命令来实现故障恢复。首先,判断一下三个条件是否满足,满足的话就进行故障恢复。
- 如果需要投票,索取投票的节点当前版本号必须比当前记录的版本一样,这样才有权索取投票;新的版本号必须是最新的。第二点,可能比较绕,譬如下面的场景,slave 是无法获得其他主机的投票的,other slave 才可以。这里的意思是,如果一个从机想要升级为主机,它与它的主机必须保持状态一致。
- 索取投票的节点必须是从机节点。这是当然,因为故障修复是由从机发起的
- 最后一个是投票的时间,因为当一个主机有多个从机的时候,多个从机都会发起故障修复,一段时间内只有一个从机会进行故障修复,其他的会被推迟。
故障恢复主要是投票+从机替代主机的机制。
如何进行数据转移?
clusterState结构当中,维护了mig相关的两个信息。

ClusterCron原貌?
void clusterCron(void) { dictIterator *di; dictEntry *de; int update_state = 0; int orphaned_masters; /* How many masters there are without ok slaves. */ int max_slaves; /* Max number of ok slaves for a single master. */ int this_slaves; /* Number of ok slaves for our master (if we are slave). */ mstime_t min_pong = 0, now = mstime(); clusterNode *min_pong_node = NULL; static unsigned long long iteration = 0; mstime_t handshake_timeout; iteration++; /* Number of times this function was called so far. */ /* The handshake timeout is the time after which a handshake node that was * not turned into a normal node is removed from the nodes. Usually it is * just the NODE_TIMEOUT value, but when NODE_TIMEOUT is too small we use * the value of 1 second. */ handshake_timeout = server.cluster_node_timeout; if (handshake_timeout < 1000) handshake_timeout = 1000; /* Check if we have disconnected nodes and re-establish the connection. */ di = dictGetSafeIterator(server.cluster->nodes); while((de = dictNext(di)) != NULL) { clusterNode *node = dictGetVal(de); if (node->flags & (REDIS_NODE_MYSELF|REDIS_NODE_NOADDR)) continue; /* A Node in HANDSHAKE state has a limited lifespan equal to the * configured node timeout. */ if (nodeInHandshake(node) && now - node->ctime > handshake_timeout) { clusterDelNode(node); continue; } if (node->link == NULL) { int fd; mstime_t old_ping_sent; clusterLink *link; fd = anetTcpNonBlockBindConnect(server.neterr, node->ip, node->port+REDIS_CLUSTER_PORT_INCR, REDIS_BIND_ADDR); if (fd == -1) { /* We got a synchronous error from connect before * clusterSendPing() had a chance to be called. * If node->ping_sent is zero, failure detection can't work, * so we claim we actually sent a ping now (that will * be really sent as soon as the link is obtained). */ if (node->ping_sent == 0) node->ping_sent = mstime(); redisLog(REDIS_DEBUG, "Unable to connect to " "Cluster Node [%s]:%d -> %s", node->ip, node->port+REDIS_CLUSTER_PORT_INCR, server.neterr); continue; } link = createClusterLink(node); link->fd = fd; node->link = link; aeCreateFileEvent(server.el,link->fd,AE_READABLE, clusterReadHandler,link); /* Queue a PING in the new connection ASAP: this is crucial * to avoid false positives in failure detection. * * If the node is flagged as MEET, we send a MEET message instead * of a PING one, to force the receiver to add us in its node * table. */ old_ping_sent = node->ping_sent; clusterSendPing(link, node->flags & REDIS_NODE_MEET ? CLUSTERMSG_TYPE_MEET : CLUSTERMSG_TYPE_PING); if (old_ping_sent) { /* If there was an active ping before the link was * disconnected, we want to restore the ping time, otherwise * replaced by the clusterSendPing() call. */ node->ping_sent = old_ping_sent; } /* We can clear the flag after the first packet is sent. * If we'll never receive a PONG, we'll never send new packets * to this node. Instead after the PONG is received and we * are no longer in meet/handshake status, we want to send * normal PING packets. */ node->flags &= ~REDIS_NODE_MEET; redisLog(REDIS_DEBUG,"Connecting with Node %.40s at %s:%d", node->name, node->ip, node->port+REDIS_CLUSTER_PORT_INCR); } } dictReleaseIterator(di); /* Ping some random node 1 time every 10 iterations, so that we usually ping * one random node every second. */ if (!(iteration % 10)) { int j; /* Check a few random nodes and ping the one with the oldest * pong_received time. */ for (j = 0; j < 5; j++) { de = dictGetRandomKey(server.cluster->nodes); clusterNode *this = dictGetVal(de); /* Don't ping nodes disconnected or with a ping currently active. */ if (this->link == NULL || this->ping_sent != 0) continue; if (this->flags & (REDIS_NODE_MYSELF|REDIS_NODE_HANDSHAKE)) continue; if (min_pong_node == NULL || min_pong > this->pong_received) { min_pong_node = this; min_pong = this->pong_received; } } if (min_pong_node) { redisLog(REDIS_DEBUG,"Pinging node %.40s", min_pong_node->name); clusterSendPing(min_pong_node->link, CLUSTERMSG_TYPE_PING); } } /* Iterate nodes to check if we need to flag something as failing. * This loop is also responsible to: * 1) Check if there are orphaned masters (masters without non failing * slaves). * 2) Count the max number of non failing slaves for a single master. * 3) Count the number of slaves for our master, if we are a slave. */ orphaned_masters = 0; max_slaves = 0; this_slaves = 0; di = dictGetSafeIterator(server.cluster->nodes); while((de = dictNext(di)) != NULL) { clusterNode *node = dictGetVal(de); now = mstime(); /* Use an updated time at every iteration. */ mstime_t delay; if (node->flags & (REDIS_NODE_MYSELF|REDIS_NODE_NOADDR|REDIS_NODE_HANDSHAKE)) continue; /* Orphaned master check, useful only if the current instance * is a slave that may migrate to another master. */ if (nodeIsSlave(myself) && nodeIsMaster(node) && !nodeFailed(node)) { int okslaves = clusterCountNonFailingSlaves(node); /* A master is orphaned if it is serving a non-zero number of * slots, have no working slaves, but used to have at least one * slave. */ if (okslaves == 0 && node->numslots > 0 && node->numslaves) orphaned_masters++; if (okslaves > max_slaves) max_slaves = okslaves; if (nodeIsSlave(myself) && myself->slaveof == node) this_slaves = okslaves; } /* If we are waiting for the PONG more than half the cluster * timeout, reconnect the link: maybe there is a connection * issue even if the node is alive. */ if (node->link && /* is connected */ now - node->link->ctime > server.cluster_node_timeout && /* was not already reconnected */ node->ping_sent && /* we already sent a ping */ node->pong_received < node->ping_sent && /* still waiting pong */ /* and we are waiting for the pong more than timeout/2 */ now - node->ping_sent > server.cluster_node_timeout/2) { /* Disconnect the link, it will be reconnected automatically. */ freeClusterLink(node->link); } /* If we have currently no active ping in this instance, and the * received PONG is older than half the cluster timeout, send * a new ping now, to ensure all the nodes are pinged without * a too big delay. */ if (node->link && node->ping_sent == 0 && (now - node->pong_received) > server.cluster_node_timeout/2) { clusterSendPing(node->link, CLUSTERMSG_TYPE_PING); continue; } /* If we are a master and one of the slaves requested a manual * failover, ping it continuously. */ if (server.cluster->mf_end && nodeIsMaster(myself) && server.cluster->mf_slave == node && node->link) { clusterSendPing(node->link, CLUSTERMSG_TYPE_PING); continue; } /* Check only if we have an active ping for this instance. */ if (node->ping_sent == 0) continue; /* Compute the delay of the PONG. Note that if we already received * the PONG, then node->ping_sent is zero, so can't reach this * code at all. */ delay = now - node->ping_sent; if (delay > server.cluster_node_timeout) { /* Timeout reached. Set the node as possibly failing if it is * not already in this state. */ if (!(node->flags & (REDIS_NODE_PFAIL|REDIS_NODE_FAIL))) { redisLog(REDIS_DEBUG,"*** NODE %.40s possibly failing", node->name); node->flags |= REDIS_NODE_PFAIL; update_state = 1; } } } dictReleaseIterator(di); /* If we are a slave node but the replication is still turned off, * enable it if we know the address of our master and it appears to * be up. */ if (nodeIsSlave(myself) && server.masterhost == NULL && myself->slaveof && nodeHasAddr(myself->slaveof)) { replicationSetMaster(myself->slaveof->ip, myself->slaveof->port); } /* Abourt a manual failover if the timeout is reached. */ manualFailoverCheckTimeout(); if (nodeIsSlave(myself)) { clusterHandleManualFailover(); clusterHandleSlaveFailover(); /* If there are orphaned slaves, and we are a slave among the masters * with the max number of non-failing slaves, consider migrating to * the orphaned masters. Note that it does not make sense to try * a migration if there is no master with at least *two* working * slaves. */ if (orphaned_masters && max_slaves >= 2 && this_slaves == max_slaves) clusterHandleSlaveMigration(max_slaves); } if (update_state || server.cluster->state == REDIS_CLUSTER_FAIL) clusterUpdateState(); }
总结:
上篇简单介绍了几种常用的redis集群方案,其实本质上就是处理好负载均衡和故障恢复,redis sentinel已经能够很好地处理故障恢复了。负载均衡通过一致性哈希来是想,具体放到哪个层就是设计的时候需要考虑的了。
目前,生成环境用的比较多的有豌豆荚的codis集群方案,听说是zookeeper+proxy实现,不知道最新有什么更新。准备研究研究争取引入到项目当中。Codis的介绍将会在下篇进行。
