Hadoop集群搭建
Hadoop集群搭建
Hadoop的集群搭建大致分为三部分:第一部分是Linux的环境配置,分为8个小节。第二部分是Hadoop的核心文件配置,分为8个小节。第三部分为Hadoop的启动与关闭以及web展示。
第一,准备Linux环境
1. 配置虚拟机的网络
在虚拟机中执行以下命令:vim /etc/sysconfig/network-scripts/ifcfg-eth0
在内容里配置网络IP:
IPADDR=192.168.102.130 (虚拟机网络IP)
NETMASK=255.255.255.0 (子网掩码)
GATEWAY=192.168.1.11 (本地IP)
DNS1=8.8.8.8
重启网卡服务
执行以下命令:service network restart
执行完命令以后需要重新与CRT连接192.168.102.130这个地址
注:如果无法连接网络,变更MAC地址:(虚拟机设置>网络适配器>高级>MAC地址:建议多刷新几下避免地址重复)
执行:vim /etc/sysconfig/network-scripts/ifcfg-eth0,找到HWADDR=00:0C:29:BD:22:E7,修改00:0C:29:BD:22:E7与MAC地址保持一致
2. 复制虚拟机
首先关闭虚拟机,找到虚拟机的文件所在位置
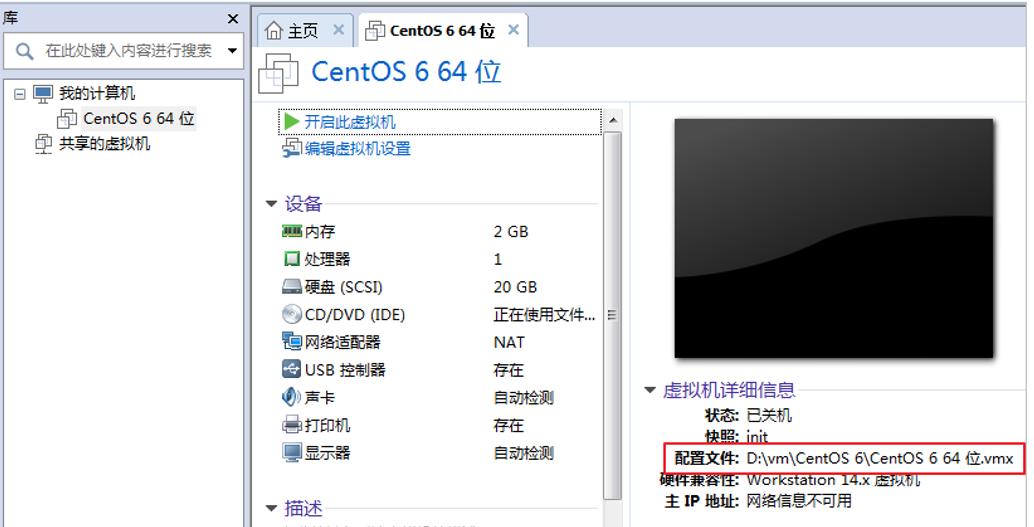
找到虚拟机文件复制更名两份
如图所示: (文件名为自定义)
(文件名为自定义)
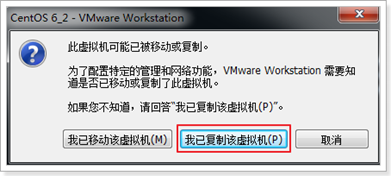
将复制的文件目录内带有LCK的文件删除,打开虚拟机主页,选择打开虚拟机,找到复制文件的位置,选择后缀为vmx的文件打开
对启用复制的虚拟机,选择复制该虚拟机
设置网卡
选择root用户登陆,更改Linux的网卡,执行以下命令:vim /etc/udev/rules.d/70-persistent-net.rules
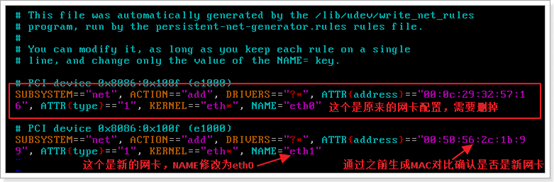
删除原来的网卡,修改如下:
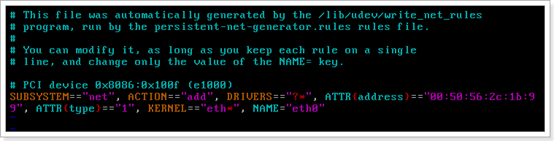
修改完成以后重启:reboot
使用root用户进入,执行以下命令:vim /etc/sysconfig/network-scripts/ifcfg-eth0
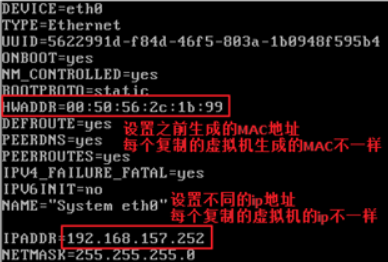
重启网卡,执行以下命令:service network restart
使用CRT创建新的连接
3. 关闭Linux防火墙
Linux默认是开启防火墙的,为了大数据课程的学习,我们需要关闭防火墙,给所有的Linux虚拟机都执行以下命令:
关闭防火墙
service iptables stop
关闭防火墙的自启动
chkconfig iptables off
查看防火墙的自启动状态
chkconfig iptables --list
4. 更改各个虚拟机名
执行以下命令:vi /etc/sysconfig/network
添加:
NETWORKING=yes
HOSTNAME=Master(Master为自定义的主机名)
5. 修改主机名称和IP的映射关系
在每个虚拟机中执行以下命令:vi/etc/hosts
添加刚修改的各个虚拟机的IP与主机名
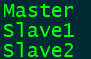
192.168.102.130 Master
192.168.102.131 Slave1
192.168.102.132 Slave2
6. 配置SSH免密登陆
ssh-keygen -t rsa (四个回车)每台虚拟机都要执行
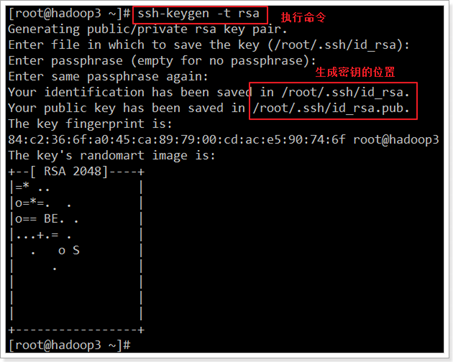
这样每台虚拟机都生成了一个公钥与私钥
收集所有的公钥:每台虚拟机执行以下命令:ssh-copy-id Master(Master为自定义的主机名)
在命令台输入cd .ssh找到文件所在位置 输入cat authorized_keys 查看收集的公钥
分发公钥
在Master中执行以下命令:
scp /root/.ssh/authorized_keys Slave1:/root/.ssh/ (复制root中的authorized_keys到Slave1root用户中的.ssh文件)
scp /root/.ssh/authorized_keys Slave2:/root/.ssh/ (复制root中的authorized_keys到Slave2root用户中的.ssh文件)
完成免密登陆
7. 安装JDK
规范两个目录:
mkdir -p /export/servers #存放我们所有安装的软件地址
mkdir -p /export/softwares #存放我们所有的安装包
查看释放自带JKD
执行以下命令:rpm -qa | grep jdk

如果有自带的jdk,就卸载,因为要使用自己的jdk。
删除命令:rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64 java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64

将准备好的jdk软件包添加到softwares 文件中

执行以下命令,进入到jdk所在位置
cd /export/softwares/01.jdk(0.1.jkd为软件包名称,可根据自己本机上的安装包名称修改)
将jdk解压到指定目录(-C /export/servers)命令:tar -zxvf jdk-8u141-linux-x64.tar.gz -C /export/servers/
8. 配置jdk的环境变量
执行以下命令:vim /etc/profile
在配置文件中添加以下配置:
export HADOOP_HOME=/export/servers/hadoop-2.7.4 (/export/servers/hadoop-2.7.4路径为自身安装的自定义的路径)
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin (/export/servers/hadoop-2.7.4为添加路径)

保存退出以后执行以下命令:source /etc/profile
验证jdk是否安装成功,执行命令:java -version, 显示版本信息即可

第二,配置Hadoop核心文件
1. 安装Hadoop
添加Hadoop安装包到softwares
将Hadoop解压到指定目录(-C /export/servers)命令:tar -zxvf hadoop-2.7.4-with-centos-6.7.tar.gz -C /export/servers/
2. hadoop-env.sh
执行以下命令,来到hadoop的安装目录:cd /export/servers/hadoop-2.7.4/etc/hadoop/
执行:vi hadoop-env.sh
在配置中修改以下配置:export JAVA_HOME=/export/servers/jdk1.8.0_141 (将上面的export注解掉或者在后面输入路径都可以)

保存退出
3. core-site.xml
执行以下命令,来到hadoop的安装目录:cd /export/servers/hadoop-2.7.4/etc/hadoop/
执行:vi core-site.xml
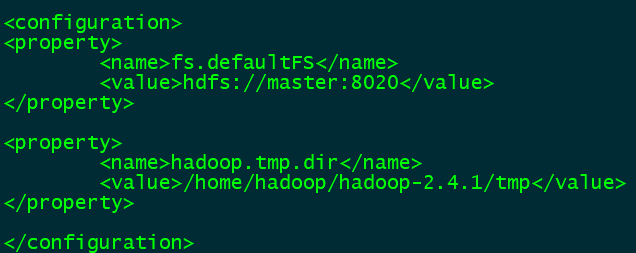
在配置文件中添加以下配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value> (master:8020为自己自定义的主机名与端口号)
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.4.1/tmp</value> (运行时产生文件的存储目录)
</property>
指定Hadoop所使用的文件系统schema(URI),Hdfs的老大(NameNode)的地址
4. hdfs-site.xml
执行以下命令,来到hadoop的安装目录:cd /export/servers/hadoop-2.7.4/etc/hadoop/
执行:vi hdfs-site.xml
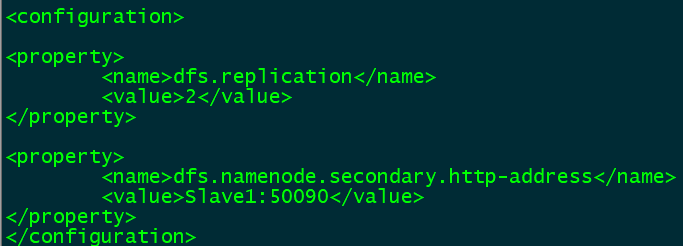
在配置文件中添加以下配置:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Slave1:50090</value>
</property>
指定Hdfs副本的数量
5. mapred-site.xml
执行以下命令,来到hadoop的安装目录:cd /export/servers/hadoop-2.7.4/etc/hadoop/
执行:vi mapred-site.xml
在配置文件中添加以下配置:
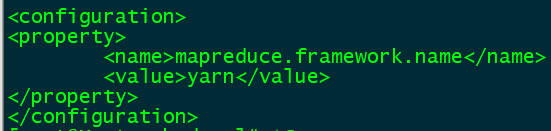
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
指定mr运行时框架,这里指定在yarn上,默认是local
6. yarn-site.xml
执行以下命令,来到hadoop的安装目录:cd /export/servers/hadoop-2.7.4/etc/hadoop/
执行:vi yarn-site.xml
在配置文件中添加以下配置:
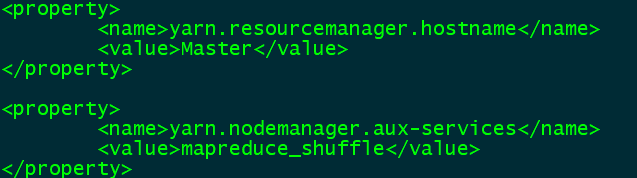
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
指定YARN的老大(ResourceManager)的地址
7. slaves
执行以下命令,来到hadoop的安装目录:cd /export/servers/hadoop-2.7.4/etc/hadoop/
执行:vi slaves
在slaves文件,里面添加主机名字
8. 将Hadoop添加到环境变量
执行以下命令:vim /etc/profile
在配置文件中添加以下配置:
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

可放置任意位置,保存即可
第三,启动与关闭
启动Hadoop集群需要启动hdfs和yarn两个集群
(注:首次启动hdfs时,必须要进行格式化操作!本质上是一些清理或准备工作,因为此时hdfs在系统中还不存在)
如果初始化了多次会怎样?
会导致主从直接的集群表示clusterID不一致,造成互不认识,数据丢失,因此在企业在不允许出现此状况。
如果真是初始化了多次,删除每台设备上的Hadoop.tmp.dir的指定文件夹,重新格式化一次,这样相当于搭建了一个新的集群
命令:hadoop na'meno'de -forma't
hdfs脚本一键启动:start-dfs.sh 停止:stop-dfs.sh
yarn脚本一键启动:start-yarn.sh 停止:stop-yarn.sh
或
一键启动:start-all.sh
一键关闭:stop-all.sh
注:想要使用脚本命令,需要提前配置好免密登陆以及slaves文件
web查看
一旦Hadoop启动以后,可登陆web查看
在本机配置映射文件:C:\Windows\System32\drivers\etc,将虚拟机登陆的IP地址添加到hosts文件中并指定访问名

namenode(名称节点)简称:nn
datanode (数据节点)简称:dn
resourcemanger(资源管理)简称:rm
secondarynamenode(辅助名称节点)简称:snn
nodemanager(节点管理器)简称:nm
http://nn_host:port 默认50070
http://rm_host:port 默认8088
hdfs的集群web地址: http://master:50070(默认端口号50070)

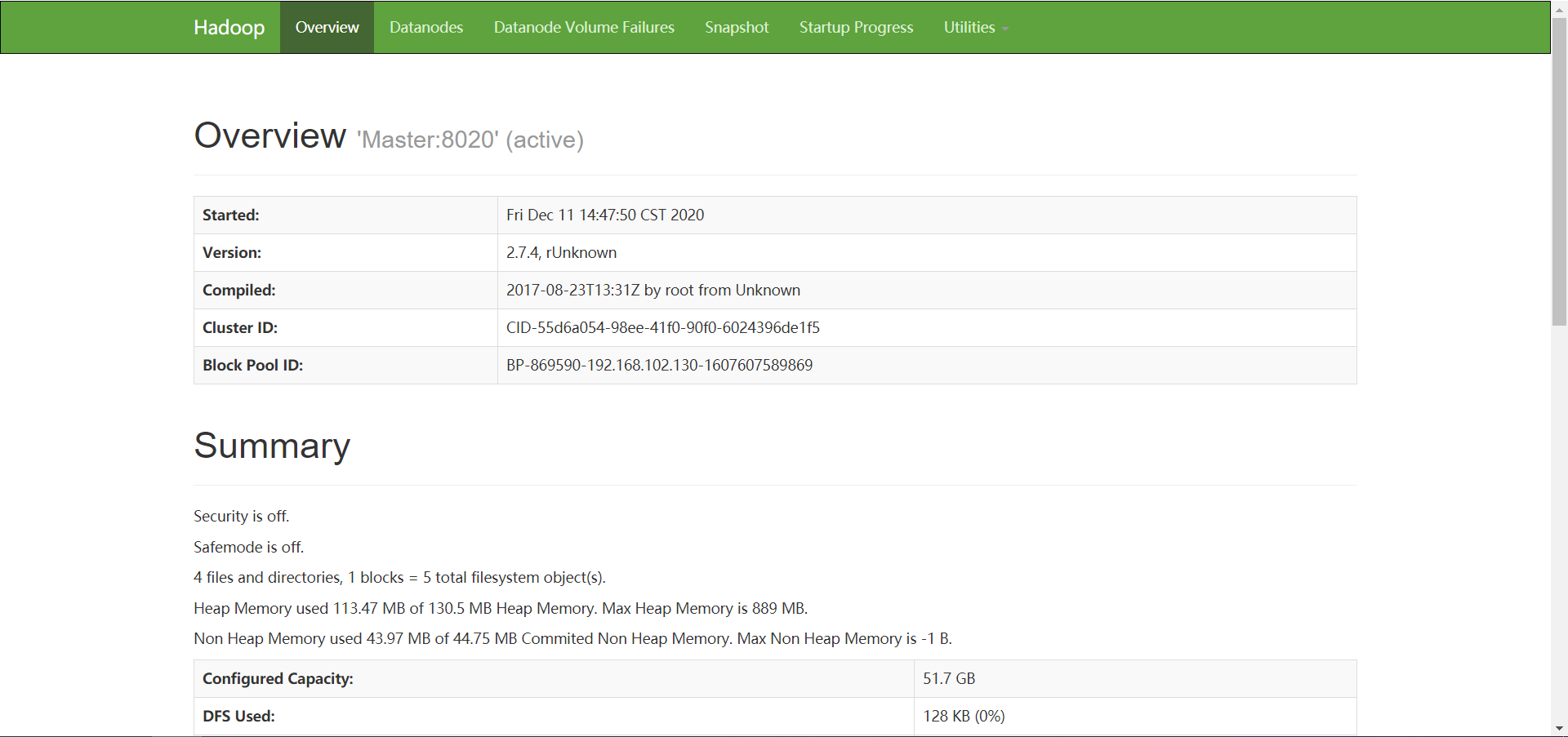
yarn的集群web地址:http://master:8088(默认端口号8088)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号