
R语言与概率统计(四) 判别分析(分类)



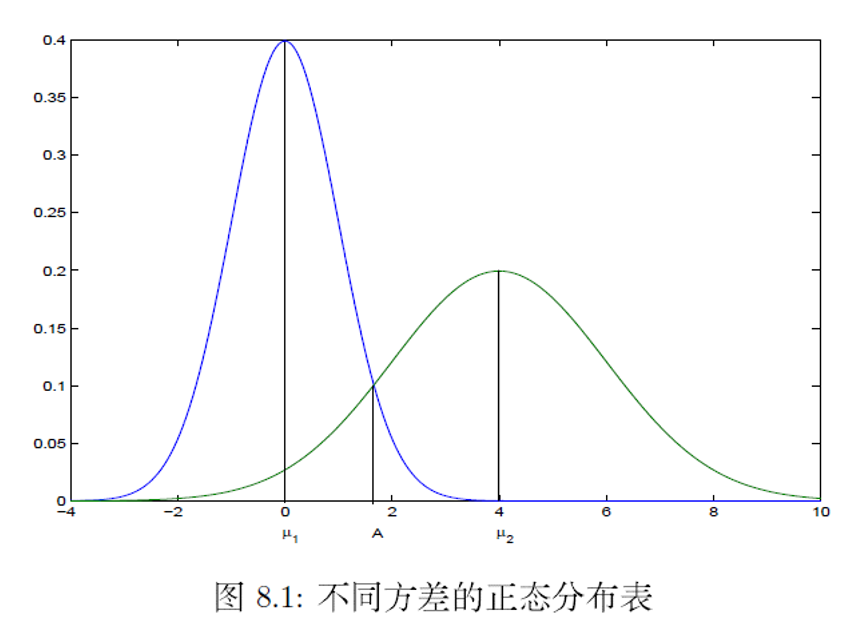


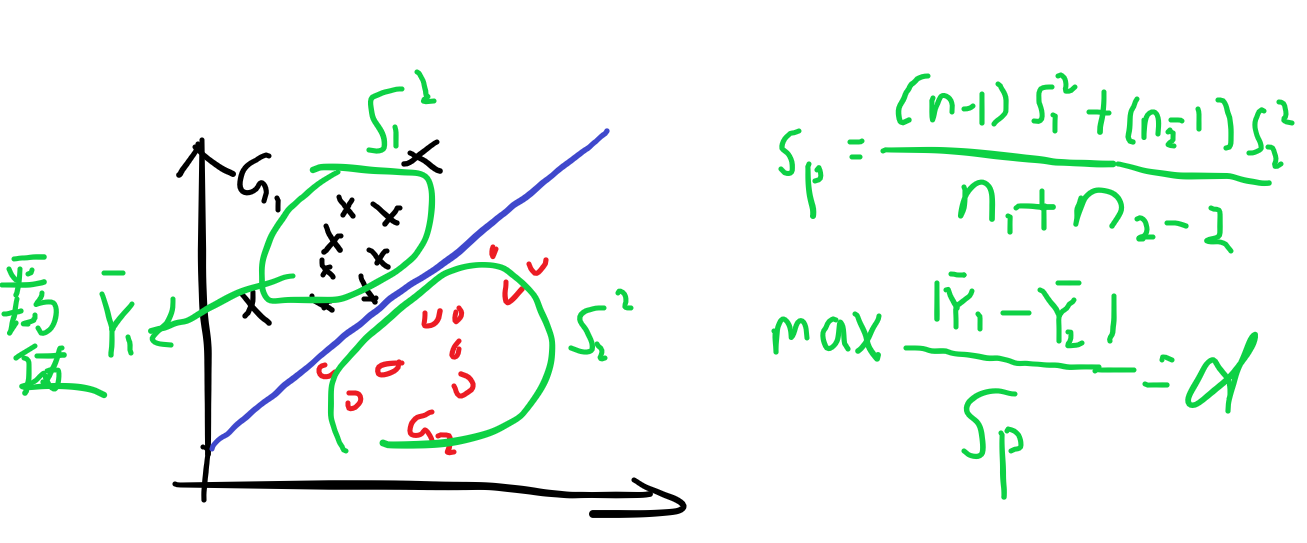
Fisher就是找一个线L使得组内方差小,组间距离大。即找一个直线使得d最大。
####################################1、判别分析,线性判别:2、分层抽样 #install.packages('MASS') library(MASS) #install.packages('sampling') library(sampling)#抽样时使用 ?iris#了解该数据集 #把iris重新赋值,并加入分类标记和行号标记 i<-iris#为了书写方便 i$lv<-as.numeric(i$Species)#把最后一列变成数值型变量 i$lv<-as.factor(i$lv) #转成因子 i$id<-c(1:150)#添加变量id #进行分层抽样,每个类别随机抽出10个作为预测集,剩下的作为训练集 i.s<-strata(data=i,stratanames="lv",size=c(10,10,10),method="srswor",description=F) i.train<-i[!(i$id %in% i.s$ID_unit),]#%in%在此处表示i与i.s中标号相同的点。1 %in% 1 i.predict<-i[(i$id %in% i.s$ID_unit),] #拟合线性判别lda fit<-lda(lv~.-id-Species,data=i.train) #预测训练集和预测集 Y<-predict(fit,i.train) YN<-predict(fit,i.predict) #查看拟合情况 table(Y$class,i.train$lv) table(YN$class,i.predict$lv) #非线性规划 fit2<-qda(lv~.-id-Species,data=i.train)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号