

Spark学习笔记6:Spark调优与调试
1、使用Sparkconf配置Spark
对Spark进行性能调优,通常就是修改Spark应用的运行时配置选项。
Spark中最主要的配置机制通过SparkConf类对Spark进行配置,当创建出一个SparkContext时,就需要创建出一个SparkConf实例。
Sparkconf实例包含用户要重载的配置选项的键值对。调用set()方法来添加配置项的设置,然后把这个对象传给SparkContext的构造方法。
调用setAppName()和setMaster()来分别设置spark.app.name和spark.master的值。
例如:
//创建一个conf对象
val conf = new SparkConf()
conf.set("spark.app.name","My Spark App")
conf.set("spark.master","local[4]")
conf.set("spark.ui.port","36000")
//使用这个配置对象创建一个SparkContext
val sc = new SparkContext(conf)
Spark运行通过spark-submit工具动态设置配置项。当应用被spark-submit脚本启动时,脚本会把这些配置项设置到运行环境中。
例如:
$ bin/spark-submit \ --class com.example.MyAPP \ --master local[4] \ --name "My Spark App" --conf spark.ui.port=36000 \ myApp.jar
Spark有特定的优先级顺序来选择实际配置,优先级最高的是在用户代码中显示调用set()方法设置的选项,其次是通过spark-submit传递的参数,再次是写在配置文件中的值,最后是系统的默认值。
2、Spark执行的组成部分:作业、任务和步骤
通过Spark示例展示Spark执行的各个阶段,以了解用户代码如何被编译为下层的执行计划。
val input = sc.textFile("input.txt")
val tokenized = input.map(line => line.split(" ")).filter(words => words.size > 0)
val counts = tokenized.map(words => (words(0),1)).reduceByKey{(a,b) => a+b}
以上示例执行了三次转化操作,最终生成一个叫做counts的RDD。程序定义了一个RDD对象的有向无环图,每个RDD维护了其指向一个或多个父节点的引用,以及表示其与父节点之间关系的信息。
这里counts的谱系图如下:
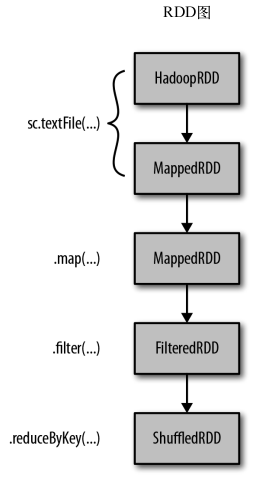
在调用行动操作之前,RDD都只是存储着可以让我们计算出具体数据的描述信息。要触发实际计算,需要对counts调用一个行动操作,比如使用collect()将数据收集到驱动器程序。
counts.collect()
Spark调度器会创建出用于计算行动操作的RDD物理执行计划。Spark调度器从最终需要被调用行动操作的RDD出发,向上回溯所有必须计算的RDD。调度器会访问RDD的父节点,父节点的父节点,以此类推,递归向上生成计算所有必要的祖先RDD的物理计划。如下:
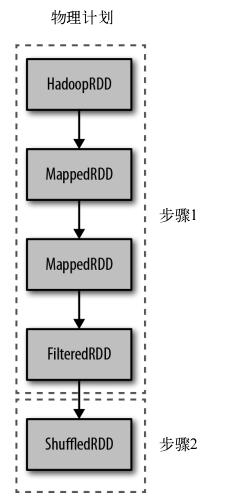
流水线执行:当RDD不需要混洗数据就可以从父节点计算出来时,调度器就会自动进行流水线执行。在物理执行时,执行计划输出的缩进等级与父节点相同的RDD会与父节点在同一个步骤中进行流水线执行。
除了流水线执行的优化,当一个RDD已经缓存在集群内存或磁盘上时,Spark的内部调度器也会自动截短RDD谱系图。这种情况下,Spark会短路求值,直接基于缓存下来的RDD进行计算。
特定的行动操作所生成的步骤的集合被称为一个作业。
一个物理步骤会启动很多任务,每个任务都是在不同的数据分区上做同样的事情。任务内部的流程是一样的,包括:(1)从数据存储或已有RDD或数据混洗的输出中获取输入数据。(2)执行必要的操作来计算出这些操作所代表的RDD。(3)把输出写到一个数据混洗文件中,写入外部存储或者是发回驱动器程序。
3、Spark优化的关键性能
- 并行度
RDD的逻辑表示其实是一个对象集合。在物理执行期间,RDD会被分为一系列的分区,每个分区都是整个数据的子集。当Spark调度并运行任务时,Spark会为每个分区中的数据创建出一个任务。输入RDD一般会根据其底层的存储系统选择并行度。
并行度会从两方面影响程序的性能:当并行度过低时,Spark集群会出现资源闲置的情况,而当并行度过高时,每个分区产生的间接开销累计起来就会更大。
Spark有两种方法来对操作的并行度进行调优:一种是在数据混洗操作时,使用参数的方式为混洗后的RDD指定并行度。第二种方法是对于任何已有的RDD,可以进行重新分区来获取更多或者更少的分区数。可以使用repartition()实现重新分区操作,该操作会把RDD随机打乱并分成设定的分区数目。使用coalesce()操作没有打乱数据,比repartition()更为高效。
- 序列化格式
当Spark需要通过网络传输数据,或者将数据溢写到磁盘上时,Spark需要把数据序列化为二进制格式。序列化会在数据进行混洗操作时发生,此时有可能需要通过网络传输大量数据。
Spark默认会使用Java内建的序列化库。Spark也支持第三方序列化库Kryo,可以提供比Java的序列化工具更短的序列化时间和更高压缩比的二进制表示。
使用Kryo序列化工具示例如下:
val conf = new SparkConf().setMaster("local").setAppName("partitions")
conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
//严格要求注册类 获得最佳性能
conf.set("spark.kryo.registrationRequired","true")
conf.registerKryoClasses(Array(classOf[MyClass],classOf[MyotherClass]))
- 内存管理
Spark内存有以下用途:
- RDD存储,默认占60% 当调用RDD的persist()或cache()方法时,这个RDD的分区会被存储到缓存区中。
- 数据混洗与聚合的缓存区,默认占20% 当进行数据混洗操作时,Spark会创建出一些中间缓存区来存储数据混洗的输出数据。这些缓存区用来存储聚合操作的中间结果以及数据混洗操作中直接输出的部分缓存数据。
- 用户代码,默认占20% Spark可以执行任意的用户代码,用户自行申请大量的内存。
可以通过调整调整内存各区域比例得到更好的性能表现。
其它优化:
Spark默认的cache()操作会以MEMORY_ONLY的存储等级持久化数据,当缓存新的RDD时分区空间不够,旧的分区会被删除。当用到这些分取数据时,在进行重算。使用persist()方法以MEMORY_AND_DISK存储等级存储,内存中放不下的分区会被写入磁盘,需要时再从磁盘读取回来。这种方式会有更好的性能。
还有一种是缓存序列化后的对象而非直接缓存。通过MEMORY_ONLY_SER 或者 MEMORY_AND_DISK_SER的存储等级实现。
- 硬件供给
提供给Spark的硬件资源会显著影响应用的完成时间,影响集群规模的主要参数包括:分配给没各执行器节点的内存大小,每个执行器节点占用的核心数,执行器节点总数,以及用来存储临时数据的本地磁盘数量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号