
hadoop综合大作业
Hadoop综合大作业 要求:
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
词频统计的截图如下:
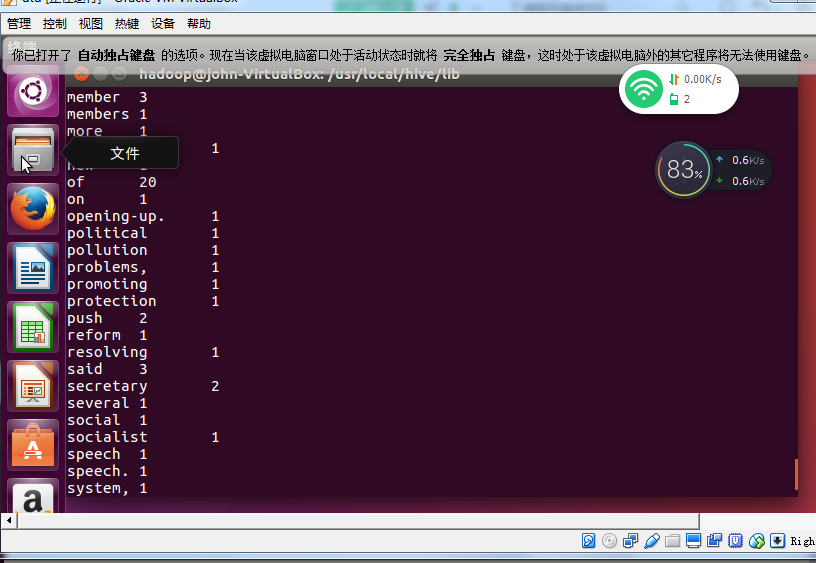
上次我所使用的文章是一篇中文文章,所以这次我用了一篇英文文档来进行分词,大致的流程与上次的操作差不多。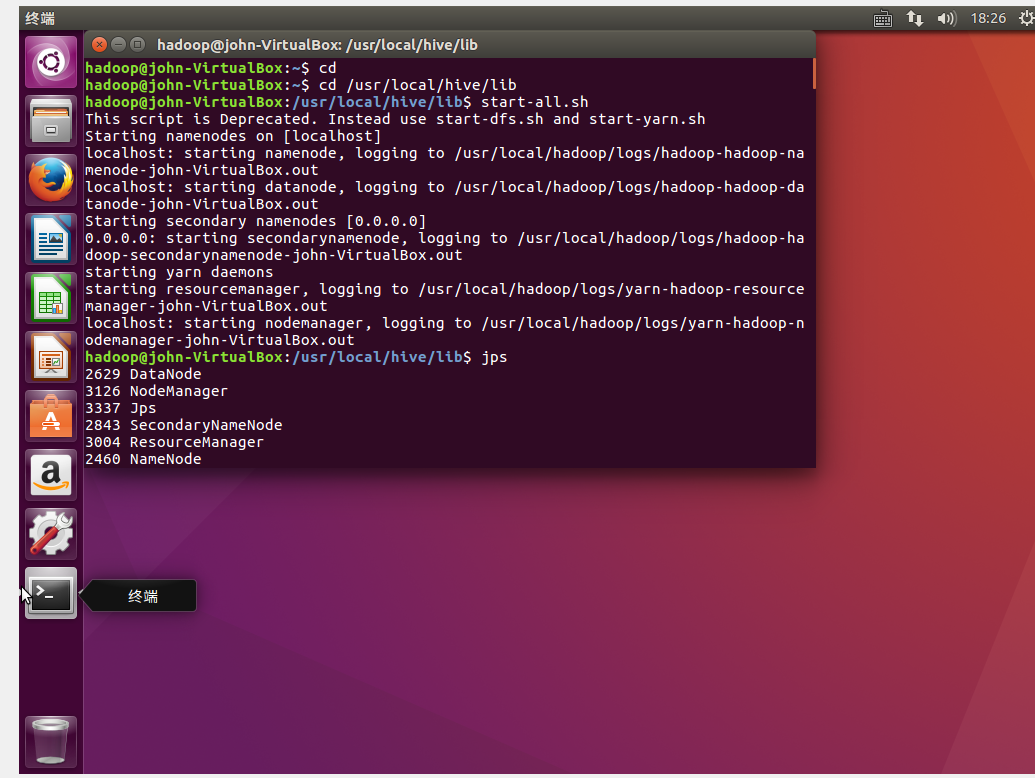
这是启动hadoop的画面。
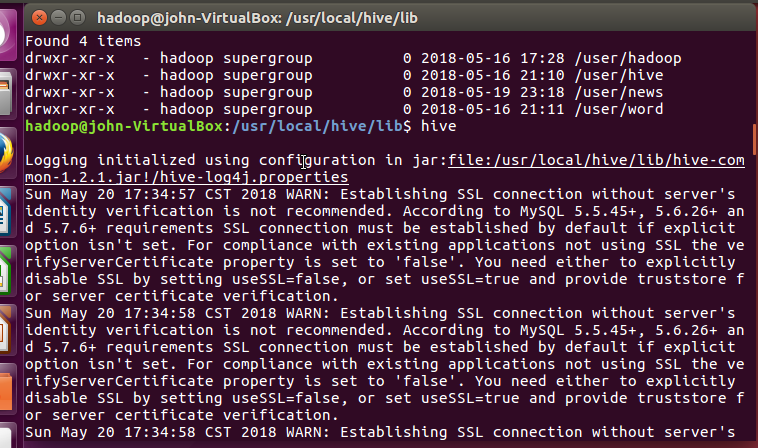
启动hive的画面
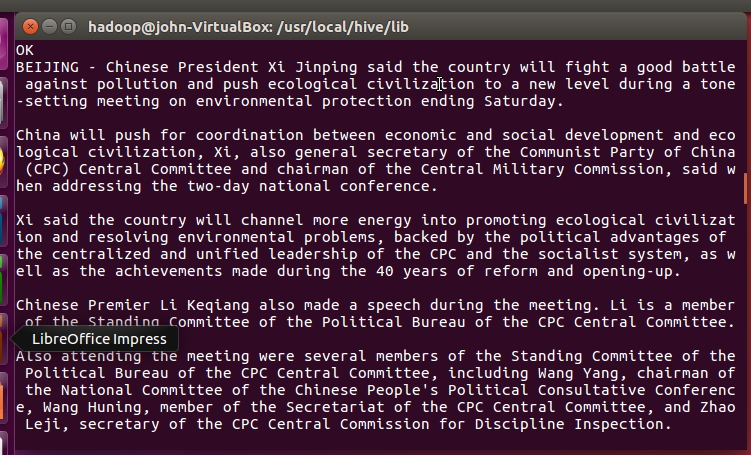
这是整篇英文文章读取出来后的结果。
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。

这个文件是之前爬虫得到的csv文件,由于数据量比较大,我就只截取了所有数据的前100条,在之后我就将这个文件传到了hadoop上面去,在我打算将它用hive新生成的文件显示出来的时候,结果显示的是乱码,如下图所示:
我在网上查阅了很多资料,可能是编码的问题,但是参照网上的那些改变编码的语句,结果还是与原来一样,不知道是因为文件在传至hadoop的过程中编码的问题还是hive新建表出现错误。最后我还是采用了与之前一样的方法,新建一个txt文档,把数据放进里面,传到hadoop上面,然后把数据显示出来。
新建一个txt文档。
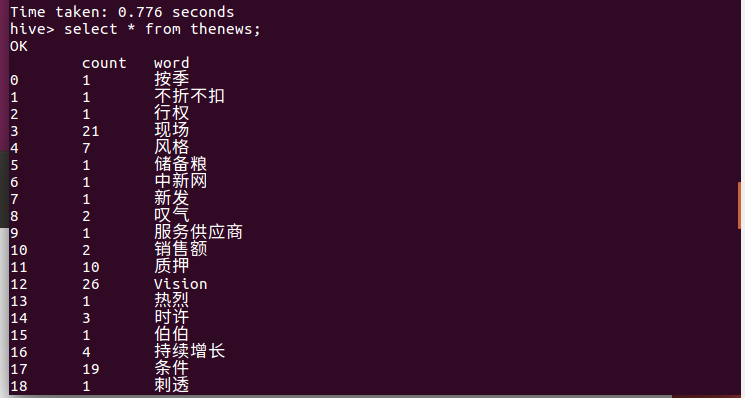
将文本中的内容显示出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号