
【并发编程】第1回 操作系统的发展史和进程
目录
1. 编写一个cs架构的软件
1.1 实现上传或者下载的思路
客户端上传电影
客户端
1.获取一个存有很多视频文件的路径 r'D:\J老师视频合集'
2.列举该路径下所有的视频文件名称供用户选择
3.拼接出该视频文件的完整路径
4.制作字典数据
5.制作字典报头
6.发送报头
7.发送字典
8.发送视频文件
服务端
1.接收固定长度的报头
2.解析数据字典的长度并接收
3.解析字典获取真实数据长度
4.接收真实数据
1.2 代码编写
- 服务端
import os
import struct
import socket
import json
print(os.path.getsize(r'D:\视频\a.mp4')) # 729983
# 创建服务端对象
server = socket.socket()
# 获得对方ip地址及端口
server.bind(('127.0.0.1', 8090))
server.listen(8)
sock, addr = server.accept()
# 视频信息字典
info_dict = {
'video_name': 'a',
'video_content': 'b',
'video_size': 729983
}
# 字典序列化为字符串
json_dict = json.dumps(info_dict)
# 查看长度
json_dict_len = len(json_dict.encode('utf8'))
# 对信息字典进行打包
dict_len = struct.pack('i', json_dict_len)
# 发送打包的字典数据
sock.send(dict_len)
# 发送真实的字典数据
sock.send(json_dict.encode('utf8'))
# 发送视频数据
with open(r'D:\视频\a.mp4', 'rb') as f:
for line in f:
sock.send(line)
- 客户端
import socket
import json
import struct
# 从客户端下载视频# 获得客户端对象
client = socket.socket()
# 获得读取的ip地址与端口
client.connect(('127.0.0.1', 8090))
# 接收固定的长度的信息字典
dict_len = client.recv(4)
# 解包固定的长度的信息字典
json_dict_len = struct.unpack('i', dict_len)[0]
# 获得真实的字典长度
json_dict = client.recv(json_dict_len)
# 反序列化字典
info_dict = json.loads(json_dict)
print(info_dict)
total_size = info_dict.get('video_size')
video_size = 0
with open(r'%s' % r'D:\视频\a.mp4', 'wb') as f:
while video_size < total_size:
data = client.recv(1024)
f.write(data)
video_size += len(data)
print('文件下载完毕')
2. UPD协议
2.1 UDP简介
- 用户数据报协议,是一个简单的面向数据报的运输层协议。UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。由于UDP在传输数据报前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快
2.2 代码编写
- 服务端
import socket
server = socket.socket(type=socket.SOCK_DGRAM)
server.bind(('127.0.0.1', 8080))
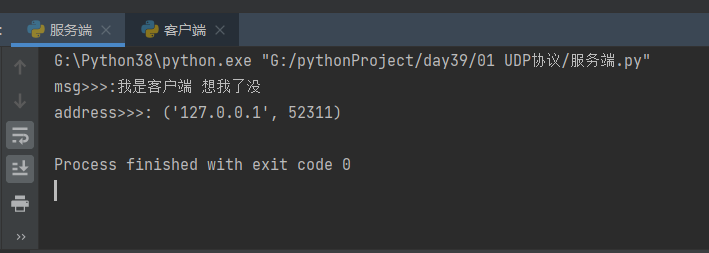
msg, address = server.recvfrom(1024)
print('msg>>>:%s' % msg.decode('utf8'))
print('address>>>:', address)
server.sendto('我是服务器 您好啊'.encode('utf8'), address)
- 客户端
import socket
client = socket.socket(type=socket.SOCK_DGRAM)
server_address = ('127.0.0.1', 8080)
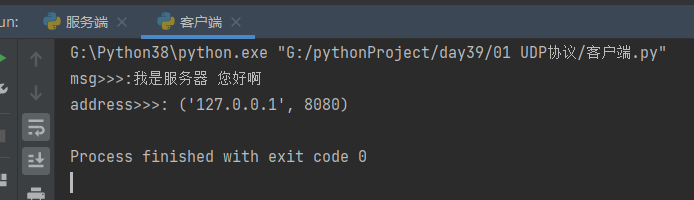
client.sendto('我是客户端 想我了没'.encode('utf8'), server_address)
msg, address = client.recvfrom(1024)
print('msg>>>:%s' % msg.decode('utf8'))
print('address>>>:', address)
2.3 总结
- 服务端不需要考虑客户端是否异常退出
- UDP不存在黏包问题(UDP多与短信息的交互)
3. 操作系统的发展史
3.1 五大组成
- 控制器
- 运算器
- 存储器
- 输入设备
- 输出设备
3.2 三大核心硬件
- CPU:是计算机中真正干活的人
- 内存:给CPU准备需要运行的代码
- 硬盘:永存存储将来可能要被运行的代码
- 强调:CPU是整个计算机执行效率的核心
3.3 穿孔卡片
- CPU利用率非常的低
- 好处是程序员可以一个人独占计算机,想干嘛就干嘛
3.4 联机批处理系统
- 缩短录入数据的时候,让CPU连续工作的时间变长>:提升CPU利用率
3.5 脱节批处理系统
- 是现代计算机的雏形>:提升CPU利用率
3.6 总结
- 操作系统的发展史也可以看成史CPU利用率提升的发展史
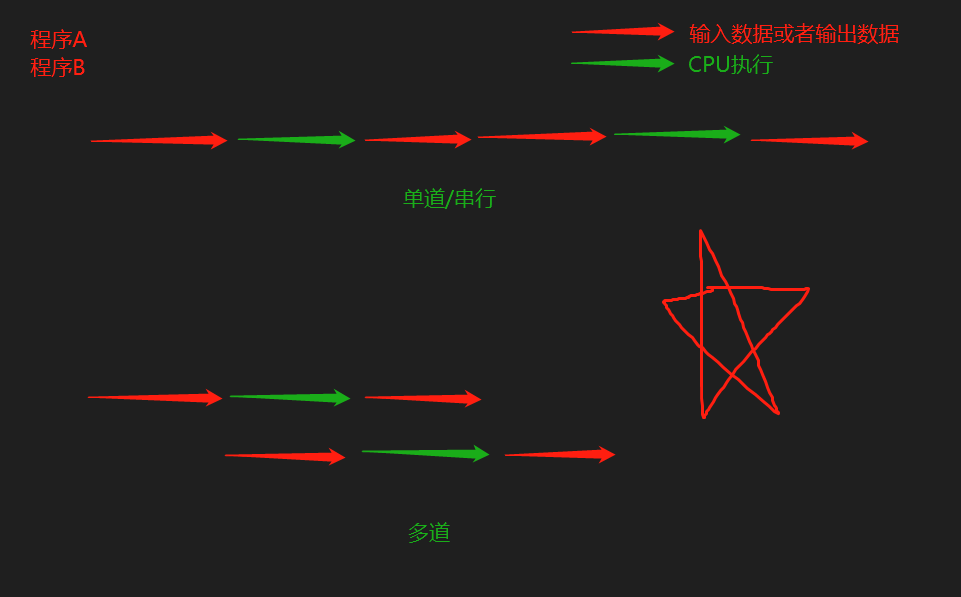
4. 多道技术
4.1 前提
- 一个核心/一个CPU/一个真正干活的
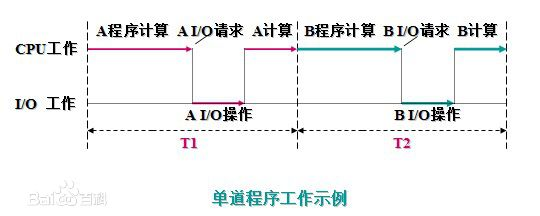
4.2 单道技术
- 所有的程序排队执行,总耗时是所有程序耗时之和
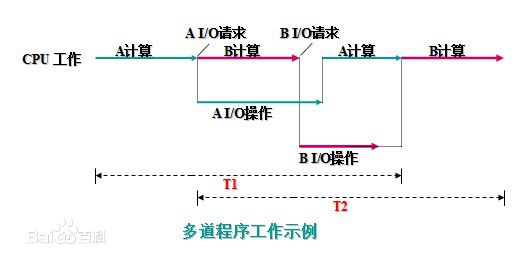
4.3 多道技术
- 计算机利用空闲时间提前准备好一些数据,提高效率,总耗时短
- 切换+保存状态
1. CPU在两种下会切换(去执行其他程序)
1.程序自身进入IO操作
IO操作:输入输出操作
获取用户输入
time.sleep()
读取文件
保存文件
2.程序长时间占用CPU
2. 保存状态
每次切换之前要记录下当前执行的状态,之后切回来基于当前状态继续执行
4.4 例子
- 做饭耗时50min,洗衣耗时30min,烧水耗时10min
- 单道技术:50+30+10
- 多道技术:50
5. 进程理论
5.1 如何理解进程
- 程序:一堆躺在文件上的死代码
- 进程:正在被运行的程序(活的)
5.2 进程的调度算法
5.2.1 先来先服务算法
- 针对耗时比较短的程序不太友好
5.2.2 短作业优先调度
- 针对耗时比较长的程度不友好
5.2.3 时间片轮转法+多级反馈队列
- 将固定的时间均分成很多分,所有的程序来了都公平的分一份
- 分配多次之后如果还有程序需要运行,则将其分到下一层
- 越往下表示程序总耗时越长,每次分的时间片越多,但是优先级越低
6. 进程的并行与并发
6.1 并行
- 多个进程同时执行,单个CPU肯定无法实现并行,必须要有多个CPU
6.2 并发
- 多个进程看上去像同时执行就可以称之为并发
- 单个CPU完成可以实现并发的效果,如果是并行那么肯定也是属于并发
6.3 描述一个网址非常牛逼能够同时服务很多人的话术
- 我这个网站很牛逼,能够支持14亿并行量(高并行)>>不合理,哪有那么多CPU(集群也不现实)
- 我这个网站很牛逼,能够支持14亿并发量(高并发)>> 非常合理,国内最牛逼的网站>>: 12306
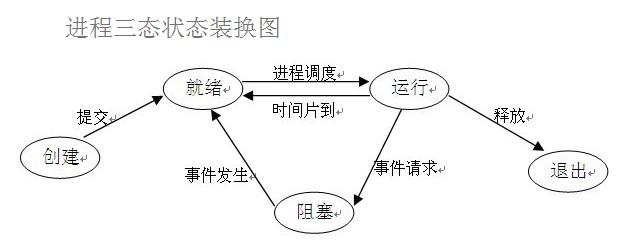
7. 进程的三状态
- 所有的进程要想被运行,必须先经过就绪态
- 运行过程中如果出现了IO操作,则进入阻塞态
- 运行过程中如果时间片用完,则继续进入就绪态
- 阻塞态相要进入运行态必须先经过就绪态
8. 同步和异步
- 用于描述任务的提交状态
- 同步:提交完任务之后原地等待任务的结果,期间不做任何事
- 异步:提交完任务之后不原地等待直接去做其他事,结果自动提醒
9. 阻塞与非阻塞
- 用于描述进程的执行状态
- 阻塞:阻塞态
- 非阻塞:就绪态,运行态
10. 同步异步与阻塞非阻塞
- 同步阻塞:在银行排队,并且在队伍中什么事情都不做
- 同步非阻塞:在银行排队,并且在队伍中做点其他事
- 异步阻塞:取号,在旁边座位上等着叫号,期间不做事
- 异步非阻塞:取号,在旁边座位上等着叫号,期间为所欲为

 浙公网安备 33010602011771号
浙公网安备 33010602011771号