
【python基础】第27回 周总结
- 周总结
- 1. 常见内置模块
- 1.1 什么是内置函数
- 1.2 abs() 求绝对值
- 1.3 all() 与 any() 判断容器类型中的所有数据值对应的布尔值是否为True
- 1.4 bin() oct() hex() 十进制转其他进制
- 1.5 int 类型转换 其他进制转十进制
- 1.6 bytes() 类型转换
- 1.7 callable() # call在IT专业名词中翻译成 调用,加括号执行
- 1.8 chr()与ord() 依据ASCII码表实现字符与数字的转换
- 1.9 dir() 获取对象内部可以通过句点符号获取的数据
- 1.10 divmod() 获取除法之外的整数和余数
- 1.11 enumerate() 枚举
- 1.12 eval()与exec() 能够识别字符串中python代码并执行
- 1.13 hash() 返回一串随机数字
- 1.14 help 查看帮助信息
- 1.15 pow() 幂指数
- 1.16 isinstance() 判断某个数据是否属于某个数据类型
- 1.17 round() 大致四舍五入 也有五舍六入
- 2. 迭代器
- 3. 异常捕获
- 4. 生成器
- 5. 模块
- 6. 包
- 7. 绝对导入与相对导入
- 8. 编程思想的转变
- 9. 软件开发目录规范
- 10. 内置模块
- 1. 常见内置模块
周总结
1. 常见内置模块
1.1 什么是内置函数
提前定义好的,直接使用即可,很多内置函数的功能都非常的好用
1.2 abs() 求绝对值
print(abs(-99)) # 99
1.3 all() 与 any() 判断容器类型中的所有数据值对应的布尔值是否为True
- all() 所有的数据值都为True 结果才True
print(all([1, 2, 3, 4, 5, 0])) # False
print(all([1, 2, 3, 4, 5])) # True
- any 所有的函数值只要有一个Ture 结果就是Ture
print(any([1, 2, 3, 4, 5, 0])) # True
print(any([1, 2, 3, 4, 5])) # True
1.4 bin() oct() hex() 十进制转其他进制
print(bin(10)) # 0b1010
print(oct(10)) # 0o12
print(hex(10)) # 0xa
1.5 int 类型转换 其他进制转十进制
res = '现在有多苦 将来就有多轻松'.encode('utf8')
print(res)
res1 = res.decode('utf8')
print(res1) # 现在有多苦 将来就有多轻松
1.6 bytes() 类型转换
res = '解码编码'.encode('utf8')
print(res) # b'\xe8\xa7\xa3\xe7\xa0\x81\xe7\xbc\x96\xe7\xa0\x81'
res1 = res.decode('utf8')
print(res1) # 解码编码
res = bytes('解码编码','utf8')
print(res) # b'\xe8\xa7\xa3\xe7\xa0\x81\xe7\xbc\x96\xe7\xa0\x81'
res1 = str(res,'utf8')
print(res1) # 解码编码
1.7 callable() # call在IT专业名词中翻译成 调用,加括号执行
name = 'jason'
def index():
print('from index')
print(callable(name)) # False
print(callable(index)) # True
1.8 chr()与ord() 依据ASCII码表实现字符与数字的转换
print(chr(65)) # A
print(chr(97)) # a
print(ord('A')) # 65
print(ord('a')) # 97
1.9 dir() 获取对象内部可以通过句点符号获取的数据
print(dir(str))
# ['__add__', '__class__',....]
1.10 divmod() 获取除法之外的整数和余数
real_num, more = divmod(898, 10)
if more:
real_num += 1
print('总页数:%s' % real_num) # 90
1.11 enumerate() 枚举
name_list = ['jason', 'kevin', 'oscar', 'jerry']
# 需求:循环打印出数据值并且对应的索引值
for i, j in enumerate(name_list): # 默认是从0开始 可以自定义
print(i, j)
for i, j in enumerate(name_list, 10): # 自定义从10开始
print(i, j)
1.12 eval()与exec() 能够识别字符串中python代码并执行
# eval 不识别复杂结构的代码 只能识别最简单的 exec 能够识别复杂结构的代码
res = 'print(123)'
eval(res) # 123
exec(res) # 123
res1 = "for i in range(2):print(i)"
eval(res1) # 报错
exec(res1) # 0 1
1.13 hash() 返回一串随机数字
print(hash('jason')) # -6166847871802287264
print(hash('123')) # -9110945152760350255
1.14 help 查看帮助信息
help(len)
1.15 pow() 幂指数
print(pow(2, 3)) # 8
1.16 isinstance() 判断某个数据是否属于某个数据类型
print(isinstance(123,int)) # True
print(isinstance(123,str)) # False
1.17 round() 大致四舍五入 也有五舍六入
print(round(10.4)) # 10
print(round(10.5)) # 10
print(round(10.6)) # 11
2. 迭代器
2.1 可迭代对象
2.1.1 迭代如何理解
迭代就是更新换代 每次迭代都需要基于上一次的成果 。 eg:手机上面的软件更新其实专业名字就是软件版本迭代
2.1.2 迭代器简介
迭代器即用来迭代取值的工具,而迭代是重复反馈过程的活动,其目的通常是为了逼近所需的目标或结果,每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值,单纯的重复并不是迭代。
2.1.3 如何判断可迭代对象
- 内置函数__iter__方法的都叫做可迭代对象
- 内置是什么意思 通过句号符直接能够点出东西的都叫内置
- xxx 针对双下划线开头双下划线结尾的方法 统一读作 双下xxx
2.1.4 可迭代对象与不可迭代对象
- 可迭代对象(能够支持for循环取值)
字符串,列表,字典,元组,集合,文件对象(本身就是迭代器对象) - 不可迭代对象
整形,浮点型,布尔值,函数名
2.2 迭代器对象
2.2.1 迭代器对象作用
- 迭代器对象给我们提供了一种不依赖于索引取值的方式
- 正是因为有迭代器对象的存在 我们才能对字典,集合这些无序类型循环取值
2.2.2 如何判断迭代器对象
内置有__iter__和__next__的对象都称为迭代器对象
2.2.3 可迭代对象与迭代器对象的关系
- 可迭代对象的调用__iter__方法之后就会变成迭代器对象
- 迭代器对象调用__iter__方法无论多少次还是迭代器对象本身
2.2.4 迭代器对象迭代取值
res = 'jason'.__iter__() # res已经是迭代器对象
print(res.__next__()) # j
print(res.__next__()) # a
print(res.__next__()) # s
print(res.__next__()) # o
print(res.__next__()) # n
print(res.__next__()) # 没有了直接报错
2.2.5 迭代器反复使用
# 每次都是产生了一个新的迭代器对象
l = [11, 22, 33, 44]
print(l.__iter__().__next__()) # 11
print(l.__iter__().__next__()) # 11
print(l.__iter__().__next__()) # 11
print(l.__iter__().__next__()) # 11
# 每次使用的都是一个迭代器对象
res = l.__iter__()
print(res.__iter__().__next__()) # 11
print(res.__iter__().__next__()) # 22
print(res.__iter__().__next__()) # 33
print(res.__iter__().__next__()) # 44
2.2.6 针对双下的方法
res = l.__iter__() # 可以简写iter(l)
res.__next__() # 可以简写next(res1)
2.2.7 迭代器对象特殊的地方 节省内存空间
可迭代对象 迭代器对象 通过打印操作无法直接看出内部数据的情况,这个时候他们都能够帮你节省内存,相当于是一个工厂 你要一个数据就临时给你造一个
2.2.8 for循环的本质
语法结构:
for 变量名 in 可迭代对象:
for循环体代码
- for 会自动将in后面的数据调用__iter__()变成迭代器对象
- 之后每次循环调用__next__()取值
- 最后没有值__next__()会报错 for能够自动处理该错误,让循环正常结束
2.3 迭代取值与索引取值的差异
2.3.1 索引取值
print(l1[0]) # 11
print(l1[1]) # 22
print(l1[0]) # 11
2.3.2 迭代取值
res = l1.__iter__()
print(res.__next__()) # 11
print(res.__next__()) # 22
print(res.__next__()) # 33
2.3.3 对比优劣势
- 索引取值
优势:可以随意反复的获取任意数据值
劣势:针对无序的容器类型无法取值 - 迭代取值
优势:提供了一种通用的取值方式
劣势:取值一旦开始只能往前不能后退 ps:具体使用那个需要结合实际情况
3. 异常捕获
3.1 异常捕获
3.1.1 如何理解异常
程序再运行的过程中如果出现了异常会导致整个程序的结束,异常就是程序员口中的bug
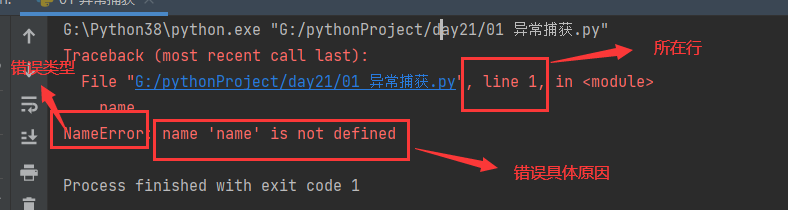
3.1.2 异常结构
- 关键字line所在行,精准提示你哪一行代码出错
- 最后一行冒号左侧,是错误类型
- 最后一行冒号右侧,错误的具体原因(也是改bug的关键)
3.1.3 异常的分类
- 语法错误
不允许出现的,一旦出现请立刻修改 - 逻辑错误
允许出现的,允许出错之后修改即可
3.1.4 异常的类型
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| IndexError | 索引错误 |
| keyError | 键错误 |
| SyntaxError | 语法错误 |
| TypeError | 类型错误 |
| IndentationError | 缩进错误 |
| NameError | 名称错误 |
| ImportError | 导入模块/对象错误 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
3.2 异常捕获实参练习
3.2.1 什么时候才可能需要自己写代码处理异常
当代码不确定什么时候会报错的情况下
eg:编写网络爬虫访问网址数据并处理 有可能会出现断网,数据没有处理不了
3.2.2 异常捕获的使用相当于是提前预测可能出现的问题并提前给出处理的措施
3.2.3 语法结构
try:
可能会出现错的代码(被try监控)
except 错误类型1 as e: # e就是具体错误的原因
对应错误类型1的解决措施
可能会出现错的代码(被try监控)
except 错误类型2 as e: # e就是具体错误的原因
对应错误类型1的解决措施
可能会出现错的代码(被try监控)
except 错误类型4 as e: # e就是具体错误的原因
对应错误类型1的解决措施
3.2.4 万能异常(笼统的处理方式)
try:
name
# d = {'name':'jason'}
# d['pwd']
# 123 + 'hello'
except Exception as e: # 万能异常方式1
print(e)
except BaseException as e: # 万能异常方式2
print(e)
3.2.5 else 与 finally
try:
name
except Exception as e:
print('出错')
else:
print('try监测的代码没有出错的情况下正常运行结束,则会执行子代码')
finally:
print('try监测的代码无论有没有出错 最后都会执行finally子代码')
3.2.6 断言
name = 'jason' # 通过一系列的手段获取来的数据
assert isinstance(name, list) # 断言数据属于什么类型 如果不对则直接报错 对则正常执行下面的代码
print('针对name数据使用列表相关的操作')
3.2.7 主动抛异常
name = input('username>>>:').strip()
if name == 'jason':
# raise NameError('jason来了 快跑!!!')
raise Exception('抛出异常')
else:
print('正常')
3.2.8 强调
- 异常捕获能尽量少用就经量少用
- 被try监测的代码能尽量少就尽量少
3.2.9 for循环内部的本质
# 使用while+异常捕获实现for循环的功能
l1 = [11, 22, 33, 44, 55, 66]
res = l1.__iter__()
while True:
try:
print(res.__next__())
except Exception as e:
break
4. 生成器
4.1 自定义迭代器对象(生成器)
4.1.1 本质其实就是迭代器对象
只不过迭代器是解释器提供给我们的(先成的) 生成器是我们自己定义出来的(自己动手)
4.1.2 学习生成器对象的目的是为优化代码
2种功能,一种不依赖于索引取值的通用方式,可以节省数据类型的内存占用空间(主要)
4.1.3 生成器表达式
# 列表
l1 = [i**2 for i in range(10) if i > 3]
print(l1) # [16, 25, 36, 49, 64, 81]
# 生成器
l1 = (i**2 for i in range(10) if i > 3)
print(l1) # <generator object <genexpr> at 0x000001A793439C10>
4.1.4 生成器对象代码实现
- 但函数体代码中有yield关键字,那么函数名第一次加括号调用不会执行函数体代码,而是由普通的函数变成了迭代器对象(生成器) 返回值
- yield可以在函数体代码中出现多次,每次调用__next__方法都会从上往下执行直到遇到yield代码停留在此处
- yield后面如果有数据值 则会像return一样返回出去,如果有多个数据值逗号隔开 那么也会自动组织成元组返回
4.1.5 yield其他用法
def index(name,food=None):
print(f'{name}准备吃饭')
while True:
food = yield
print(f'{name}正在吃{food}')
res = index('jason')
res.__next__()
res.send('饭') # 传值并自动调用__next__方法
res.send('菜') # 传值并自动调用__next__方法
res.send('肉') # 传值并自动调用__next__方法
4.2 编写生成器 实现range方法的功能
4.2.1 先实现两个参数的功能编写
# 1.先实现两个参数的功能编写 range(1,10)
def my_range(start,end):
while start < end:
yield start
start += 1
for i in my_range(1, 10):
print(i)
4.2.2 再考虑一个参数
# 2.再考虑一个参数的情况 range(10) range(0,10)
def my_range(start, end=None):
if not end:
end = start
start = 0
while start < end:
yield start
start += 1
for i in my_range(5):
print(i)
4.2.3 最后考虑三个参数的情况
# 3.最后考虑三个参数的情况 range(1, 10, 2)
def my_range(start, end=None, step=1):
if step < 1:
step = 1
if not end:
end = start
start = 0
while start < end:
yield start
start += step
for i in my_range(1, 10, 2):
print(i)
5. 模块
5.1 模块简介
5.1.1 如何理解模块
模块可以看成是一系列功能的结合体,使用模块就相当于拥有了这结合体内的所有功能。
5.1.2 模块的分类
- 内置模块
解释器自带的,直接就可以使用的模块 eg: import time - 自定义模块
自己写的模块 eg: 注册功能,登录功能 - 第三方模块
别人写的模块,存在于网络上,使用之前需要下载 eg: 图形识别,图形可视化,语言识别
5.1.3 模块的表现形式
- py文件(py文件也可以称之为是模块文件)
- 含有多个py文件的文件夹(按照模块功能的不同划分不同的文件夹存储)
- 已被编译为共享或DLL的C或C++扩展
- 使用C编写并链接到python解释器的内置模块
5.1.4 python屈辱史
- python刚开始出来的时候被其他编程程序员瞧不起,太简单 写代码都是调用模块(调包侠 贬义词)随着业务的扩展其他程序员也需要使用python写代码,写完之后发现python真香 贼好用(调包侠 褒义词)
- 为什么python很牛逼 :python之所以牛逼就是因为支持python的模块非常的多 非常的全 非常的猛
- 作为一名python程序员:将来接收到某个业务需求的时候 不要上来就想着自己写 先看看有没有相应的模块已经实现
5.2 导入模块的两种语法句式
5.2.1 import句式 和 from...import..句式
5.2.2 py文件命名格式
真正的项目中,所有的py文件名称都是英文,没有所谓的编号和中文,学习模块的时候模块文件的名称就得用英文,py文件被当做模块导入的时候不需要考虑后缀
5.3 import句式
5.3.1 句式
import md
# 执行文件是 当前文件
# 被执行文件是 md.py
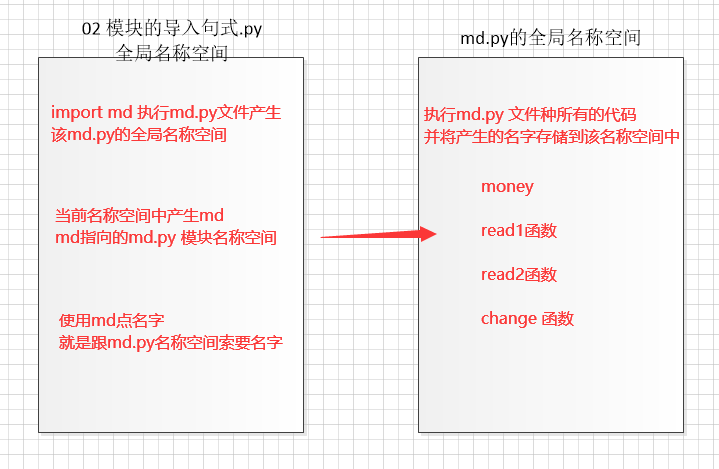
5.3.2 过程
- 会产生执行文件的名称空间
- 产生被导入文件的名称空间并运行该文件内所有的代码, 储存名字
- 在执行文件中会获取一个模块的名字 通过该名字点的方式就可以使用到被导入文件 名称空间的名字
- 同一个程序反复导入实践的模块,导导入语句只会执行一次
- 被导入文件的名称空间什么时候结束,当执行文件不结束,被导入文件名称空间不关闭
5.3.3 讲解
# 02 模块的导入句式 代码
import md
# 执行文件是 02 模块的导入句式.py
# 被执行文件是 md.py
print(md.money)
print(md.read1)
# md 代码
print('我是模块文件md.py')
money = 99
def read1():
print('from md.py read1 function')
print(money)
def read2():
print('from md.py read2 function')
read1()
def change():
global money
money = 66
# 同一个程序反复导入相同的模块 导入语句只会执行一次
import md 有效
import md 无效
import md 无效
# 带前缀 md才可以
money = 1000
md.change()
print(money) # 1000
print(md.money) # 66
5.4 from...import句式
5.4.1 句式
from...import...句式
5.4.2 过程
- 创建执行文件的名称空间
- 创建被导入文件的名称空间
- 执行被导入文件中的代码 将产生的名字存储到被导入文件的名称空间中
- 在执行文件中获取到指定的名字 指向被导入文件的命名称空间
5.4.3 讲解
from md import money # 指名道姓的导入
print(money) # 99
money = '嘿嘿'
print(money) # 嘿嘿
# 多个
from md import money, read1
print(money) # 99
read1() # from md.py read1 function
5.5 导入模块句式的其他用法
5.5.1 两种导入句式的优缺点
- import md
优点:通过md点的方式可以使用到模块内所有的名字并且不会冲突
缺点:md什么都可以点 有时候并不想让所有的名字都能被使用 - from md import money, read1
优点:指名道姓的使用指定的名字 并且不需要加模块名前缀
缺点:名字及其容易产生冲突(绑定关系2被修改)
5.5.2 起别名
- 情况1:多个模块文件名相同(多人写相同的文件命名一样)
from md import money as md_my
from md1 import money as md1_my
print(md_my)
print(md1_my)
- 情况2;原有的模块文件名复杂
import asdfjkasfhiouahsf as md
5.5.3 导入多个名字
# 建议多个模块功能相似才能适应,不想似尽量分开导入
import time, aya , os
import time
import os
import sys
# 推荐使用的 因为多个名字出自于一个模块文件
from md import money, read1, read2
5.5.4 全导入
# 需求:需要使用模块名称空间中很多名字 并且只能使用from...import句式
from md import * # *表示所有
# ps:针对*号的导入还可以控制名字的数量
# 在模块文件中可以使用__all__ = [字符串的名字]控制*能够获取的名字
5.6 循环导入问题
5.6.1 如何理解循环导入
循环导入就是两个文件彼此导彼此
5.6.2 循环导入容易出现报错现象
使用彼此的名字可能是在没有准备好的情况下就使用了
5.6.3 如何解决循环导入保存现象
彼此在使用彼此名字之前 先准备好
5.6.4 总结
循环导入将来尽量避免出现!!! 如果真的避免不了 就想办法让所有的名字在使用之前提前准备好
5.7 判断文件类型
- 学习完模块之后 以后我们的程序运行起来可能涉及到的文件就不止一个
- 所有的py文件中都自带一个__name__内置名
- 当py文件是执行文件的时候__name__的结果是__main__
- 当py文件是被导入文件的时候 __name__的结果是模块名(文件名)
- 在pycharm中可以直接编写main按tab键自动补全
__name__主要用于开发模块的作者测试自己的代码使用
if __name__ == '__main__':
当文件是执行文件的时候才会执行if的子代码
5.8 模块查找顺序
5.8.1 查找顺序
- 先去内存中查找
- 再去内置中查找
- 再去sys.path中查找(程序系统环境变量)
5.8.2 内存查找
- 导入一个文件 然后在导入过程中删除该文件 发现还可以使用,再次运行会报错执行文件时相当于把文件放在内存上,删除的相当于硬盘上
5.8.3 内置查找
创建一个跟内置模块名相同的文件名,注意创建模块文件的时候尽量不要与内置模块名冲突
5.8.4 sys.path 查找 导入模块 的时候一定要知道谁是执行文件 所有的路径都是参照执行文件来的
import sys
print(sys.path)
'''
['G:\\pythonProject\\day22',
'G:\\pythonProject\\day22',
'G:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_display',
'G:\\Python38\\python38.zip',
'G:\\Python38\\DLLs',
'G:\\Python38\\lib',
'G:\\Python38',
'G:\\Python38\\lib\\site-packages',
'G:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
'''
# 添加路径
sys.path.append(r'D:\pythonProject\day22\xxx')
5.9 添加路径
5.9.1 通用的方式
py文件名.path.append(目标文件所在的路径)
5.9.2 利用from...import句式
起始位置一定是执行文件所在的路径
from xxx(文件名) import mdd(py文件名)
6. 包
6.1 如何理解包
- 专业的角度:内部含有__init__.py的文件夹
- 直观的角度:就是一个文件夹
6.2 包的作用
内部存放多个py文件(模块文件) 仅仅是为了更加方便的管理模块
6.3 具体使用
- import 包名
- 导入包名其实导入的是里面的__init__.py文件(该文件里面有什么你才能用什么)
- 也可以跨过__init__.py直接导入包里面的模块文件
- 针对python3解释器,其实文件夹里面有没有__init__.py已经无所谓了,都是包
- 针对python2解释器,文件夹下面必须有__init__.py才能被当做包
7. 绝对导入与相对导入
7.1 导入
只要涉及到模块的导入,那么sys.path 永远以执行文件为准
7.2 绝对导入
- 以执行文件所在的sys.path为起始路劲 往下一层层查找
- 由于phcharm会自动将项目根目录添加到sys.path中所以查找模块肯定不报错的方法就是永远从根路劲往下一层层找
- 如果不是用pycharm运行,则需要将项目跟目录添加到sys.path(针对项目的根目录的绝对路劲有模块可以帮助我们获取:os模块)
7.3 相对导入
1.储备知识
.在路径中意思是当前路经
..在路劲中的意思是上一层路经
../..在路劲中意思是上上一层路径
2. 相对导入可以不参考执行文件所在的路径,直接以当前模块文件路径为准,只能在模块文件中使用,不能在执行文件中使用,相对导入在项目比较复杂的情况下可能会出错
3. 相对导入尽量少用,推荐使用绝对导入
8. 编程思想的转变
8.1 小白阶段
- 按照需求从上往下堆叠代码(面条版) 单文件模式
- 相当于将所有的文件全部存储在C盘并且不分类
8.2 函数阶段
- 将代码按照功能的不同封装成不同的函数 单文件模式
- 相当于将所有文件在C盘下分类存储
8.3 模块阶段
- 根据功能的不同拆分不同的模块文件 多文件模式
- 相当于将所有的文件按照功能的不同分别分类到不同的盘中,目的为了更加方便快捷高效的管理资源
- 分模块文件多了之后还需要有文件夹
9. 软件开发目录规范
9.1 我们所使用的所有程序目录都有一定的规范,有多个文件夹
9.2 bin文件夹
用于存储程序的启动文件 start.py
9.3 conf文件夹
用于存储程序的配置文件 settings.py
9.4 core文件夹
用于存储程序的核心逻辑 src.py
9.5 lib文件夹
用于存储程序的公共功能 common.py
9.6 db文件夹
用于存储程序的数据文件 userinfo.txt
9.7 log文件夹
用于存储程序的日志文件 log.log
9.8 interface文件夹
用于存储程序的接口文件 user.py order.py goods.py
9.9 readme文件(文本文件)
用于编写程序的说明,介绍,广告,类似于产品说明书
9.10 requirements.txt文件
用于存储程序所需的第三方模块名称和版本
9.11 总结
- 编写软件的时候 可以不完全遵循上面的文件名
- start.py可以放在bin文件夹下也可以直接放在项目根目录
- db文件夹等我们学到真正的项目会被数据库替代
- log文件夹等我们学到真正的项目会被专门的日志服务替代
10. 内置模块
10.1 collections模块
10.1.1 简介
在内置数据类型(dict,list,set,tuple)的基础上,collections模块还提供几个额外的数据类型:Counter,deque,defaultdict,namedtuple,OrderdDict等
10.1.2 namedtuple 生成可以使用名字来访问元素内容的tuple
# 二维坐标系
from collections import namedtuple
Point = namedtuple('二维坐标系',['x','y'])
res1 = Point(1,2)
res2 = Point(3,4)
print(res1, res2) # 二维坐标系(x=1, y=2) 二维坐标系(x=3, y=4)
print(res1.x) # 1
print(res2.y) # 4
# 三维坐标系
from collections import namedtuple
Point = namedtuple('三维坐标系','x y z')
res1 = Point(1,2,3)
res2 = Point(3,4,5)
print(res1, res2) # 三维坐标系(x=1, y=2, z=3) 三维坐标系(x=3, y=4, z=5)
print(res1.x) # 1
print(res2.y) # 4
print(res2.z) # 5
10.1.3 deque 高效实现插入和删除操作的双向列表,适合用于队列和栈
from collections import deque
q = deque()
q.append(11)
q.append(22)
q.append(33)
q.appendleft(44)
print(q) # deque([44, 11, 22, 33])
10.1.4 OrderedDict 有序字典,Key会按照插入的顺序排列,不是Key本身排序
from collections import OrderedDict
a = dict([('a', 1), ('b', 2), ('c', 3)])
b = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(b) # OrderedDict([('a', 1), ('b', 2), ('c', 3)])
10.1.5 Counter 目的是用来跟踪值出现的次数
from collections import Counter
c = Counter('abcdeabcdabcaba')
print(c) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
10.2 时间模块
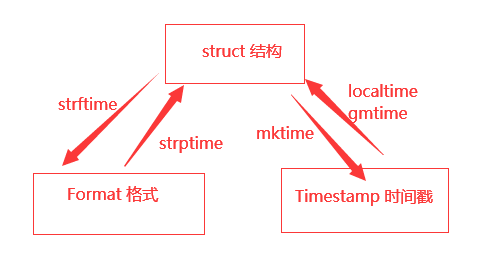
10.2.1 表示时间的三种格式
时间戳,结构化时间,格式化时间
10.2.2 时间戳 time.time()
# 时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
import time
print(time.time()) # 1657791294.936325
10.2.3 结构化时间 time.gmtime()
import time
# print(time.time()) # 1657791294.936325
print(time.gmtime()) # time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=59, tm_sec=19, tm_wday=3, tm_yday=195, tm_isdst=0)
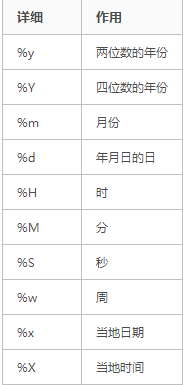
10.2.4 格式化时间 time.strftime()
# %Y-%m-%d %H-%M-%S
import time
# print(time.time()) # 1657791294.936325
# print(time.gmtime())
print(time.strftime('%Y-%m-%d %H-%M-%S')) # 2022-07-14 19-00-56
10.2.5
10.2.6
10.3 时间模块之datetime模块
10.3.1 date 年月日 datetime 年月日 时分秒
import datetime
res = datetime.datetime.today()
res1 = datetime.date.today()
print(res) # 2022-07-15 15:08:04.912520
print(res1) # 2022-07-15
print(res.year) # 2022
print(res.month) # 7
print(res.weekday()) # 4
print(res.isoweekday()) # 5
10.3.2 timedelta括号内有很多参数 没有的时间可以通过换算得来
import datetime
res1 = datetime.date.today()
t1 = datetime.timedelta(days=4)
print(res1 + t1) # 2022-07-19
print(res1 - t1) # 2022-07-11
10.3.3 指定时间
import datetime
print(datetime.datetime.now()) # 2022-07-15 15:21:17.986353(获取当前时间)
print(datetime.datetime.utcnow()) # 2022-07-15 07:21:17.986353(获取当前格林威治时间)
c = datetime.datetime(2020, 5, 12, 12, 12)
print('指定日期:',c) # 指定日期: 2020-05-12 12:12:00
10.4 os模块
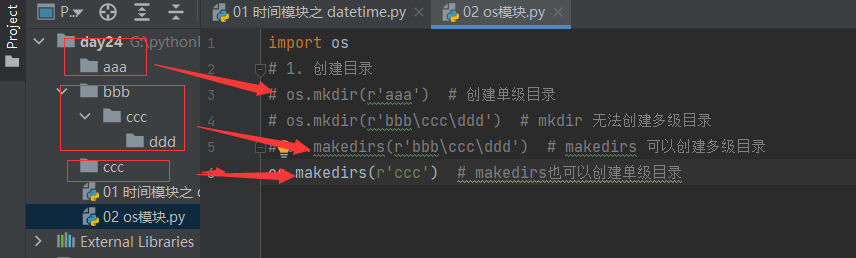
10.4.1 创建目录
import os
# 1. 创建目录
# os.mkdir(r'aaa') # 创建单级目录
# os.mkdir(r'bbb\ccc\ddd') # mkdir 无法创建多级目录
# os.makedirs(r'bbb\ccc\ddd') # makedirs 可以创建多级目录
os.makedirs(r'ccc') # makedirs也可以创建单级目录
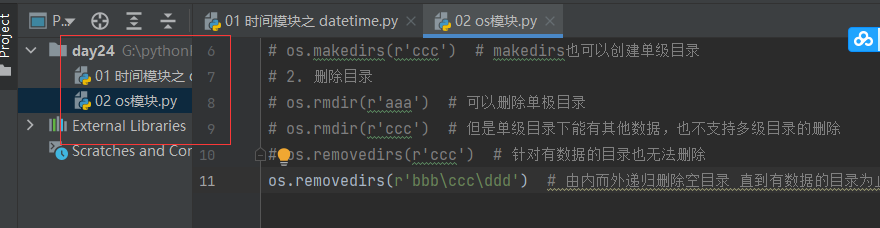
10.4.2 删除目录
import os
# os.rmdir(r'aaa') # 可以删除单极目录
# os.rmdir(r'ccc') # 但是单级目录下能有其他数据,也不支持多级目录的删除
# os.removedirs(r'ccc') # 针对有数据的目录也无法删除
os.removedirs(r'bbb\ccc\ddd') # 由内而外递归删除空目录 直到有数据的目录为止
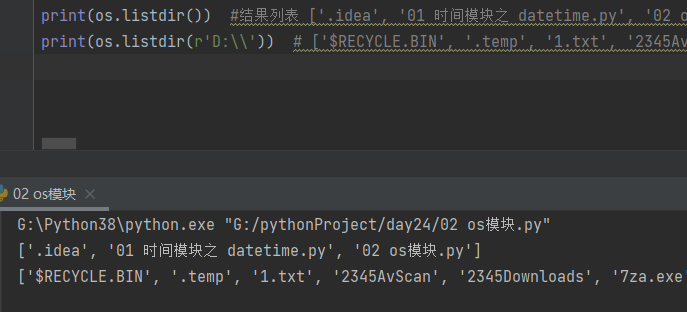
10.4.3 列举指定路径下的文件名称(文件、目录)
import os
print(os.listdir()) #结果列表 ['.idea', '01 时间模块之 datetime.py', '02 os模块.py']
print(os.listdir(r'D:\\')) # ['$RECYCLE.BIN', '.temp', '1.txt', ...... 'zlib1.dll', '作业']
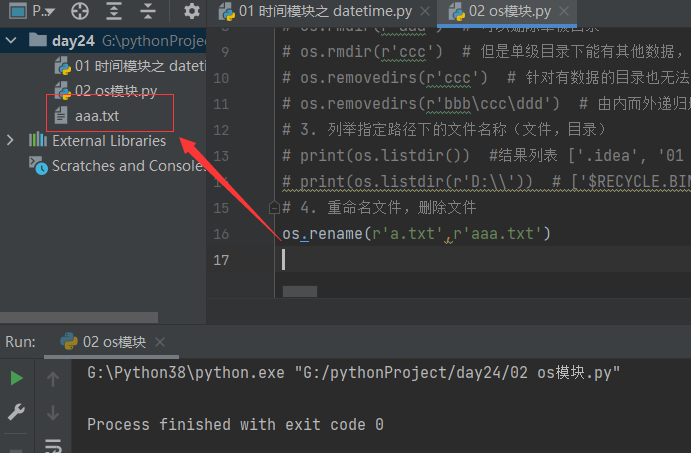
10.4.4 重命名文件 删除文件
# 重命名
import os
os.rename(r'a.txt',r'aaa.txt')
# 删除文件
import os
os.remove(r'aaa.txt')
10.4.5 获取当前工作路径(所在的路径) 绝对路径
import os
# print(os.getcwd()) # G:\pythonProject\day24
# os.chdir(r'..')
os.mkdir(r'zzzzz')
print(os.getcwd())
10.4.6 与程序启动文件相关
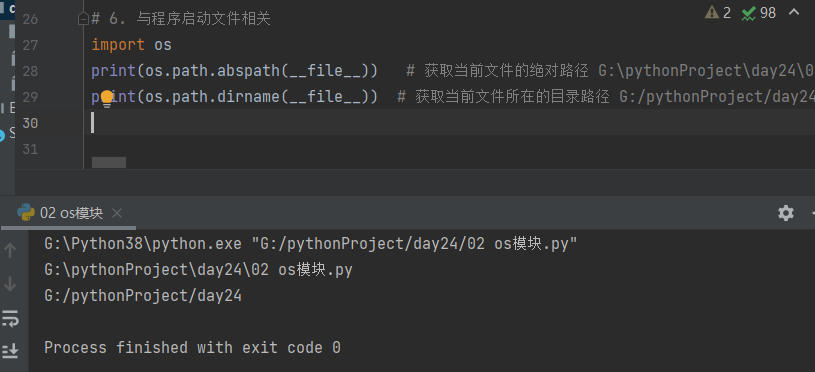
import os
print(os.path.abspath(__file__)) # 获取当前文件的绝对路径 G:\pythonProject\day24\02 os模块.py
print(os.path.dirname(__file__)) # 获取当前文件所在的目录路径 G:/pythonProject/day24
10.4.7 判断路径是否存在(文件、目录)
# isdir只用于路径是否是目录,isfile只用于路径是否是文件
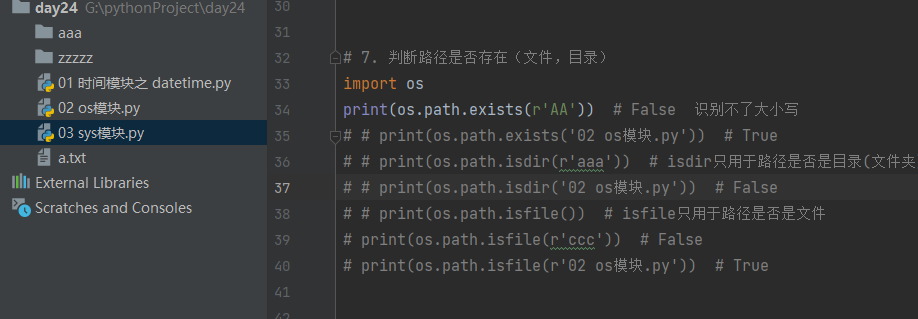
import os
# print(os.path.exists(r'AA')) # False 很多程序一般情况下默认都忽略大小写 如果为AAA返回是Ture
# print(os.path.exists('02 os模块.py')) # True
# print(os.path.isdir(r'aaa')) # isdir只用于路径是否是目录(文件夹)
# print(os.path.isdir('02 os模块.py')) # False
# print(os.path.isfile()) # isfile只用于路径是否是文件
print(os.path.isfile(r'ccc')) # False
print(os.path.isfile(r'02 os模块.py')) # True
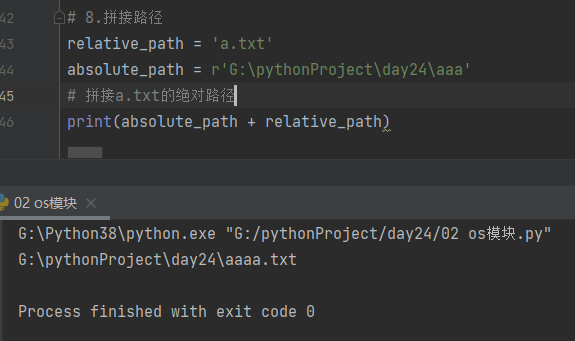
10.4.8 拼接路径
- 加号(+)拼接
relative_path = 'a.txt'
absolute_path = r'G:\pythonProject\day24\aaa'
# 拼接a.txt的绝对路径
print(absolute_path + relative_path)
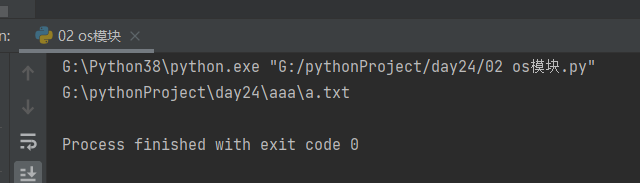
2. join方法:涉及到路径拼接,不要使用加号,建议使用os模块的里面join方法,join方法可以自动识别当前所在的操作系统并自动切换正确的分隔符 windows用\ mac用/
import os
relative_path = 'a.txt'
absolute_path = r'G:\pythonProject\day24\aaa'
res = os.path.join(absolute_path, relative_path)
print(res)
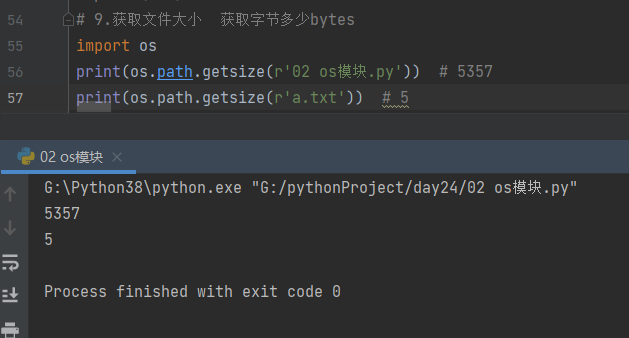
10.4.9 获取文件大小 bytes
import os
print(os.path.getsize(r'02 os模块.py')) # 5357
print(os.path.getsize(r'a.txt')) # 5
10.5 sys模块
10.5.1 sys模块主要是跟python解释器打交道
import sys
print(sys.path) # 结果列表 ['G:\\pythonProject\\day24', 'G:\\pythonProject\\day24', 'G:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_display', 'G:\\Python38\\python38.zip', 'G:\\Python38\\DLLs', 'G:\\Python38\\lib', 'G:\\Python38', 'G:\\Python38\\lib\\site-packages', 'G:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
print(sys.version) # 查看解释器信息 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)]
print(sys.platform) # 查看当前平台 win32
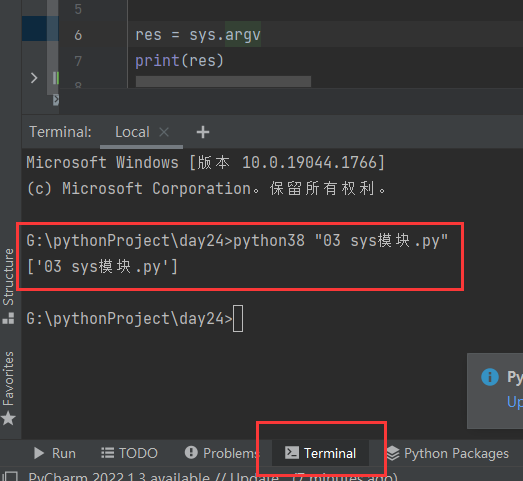
10.5.2 代码举例
import sys
res = sys.argv
print(res)
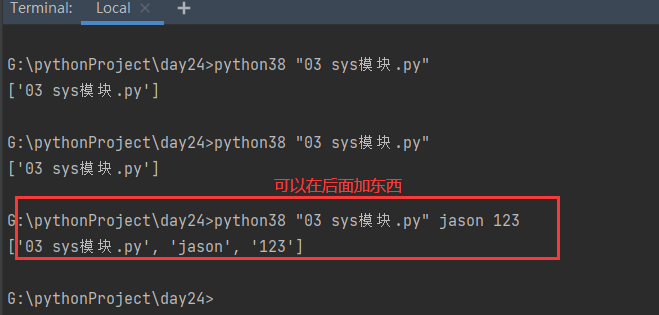
import sys
res = sys.argv
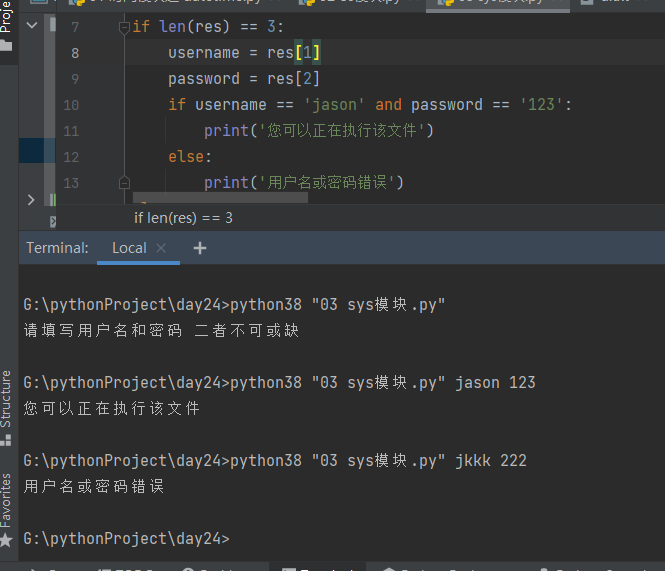
if len(res) == 3:
username = res[1]
password = res[2]
if username == 'jason' and password == '123':
print('您可以正在执行该文件')
else:
print('用户名或密码错误')
else:
print('请填写用户名和密码 二者不可或缺')
10.6 json模块
10.6.1 json模块简介
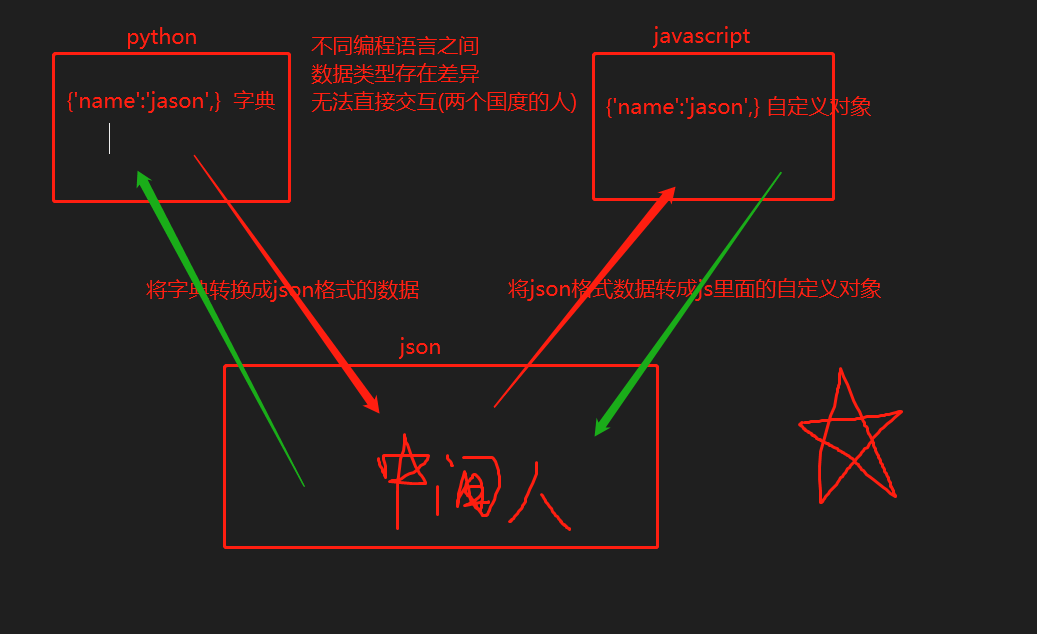
- json模块也称之为序列化模块
- json模块是不同编程语言之间数据交互必备的模块(处理措施)
10.6.2 json格式数据
- 数据基于网络传输肯定是二进制 那么在python中只有字符串可以调用encode方法转成二进制数据 所以json格式的数据也属于字符串
- json格式的数据有一个非常明显的特征,首先肯定是字符串 其次引号是标志性的双引号
10.6.3 json方法名字
- dumps() 将其他数据类型转换成json格式字符串
- loads() 将json格式字符串转化成对应的数据类型
import json
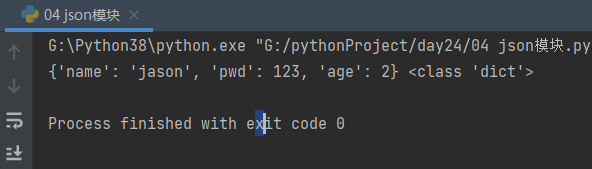
d = {'name': 'jason', 'pwd': 123, 'age': 2}
# 需求:将上述字典保存到文件中 并且将来读取出来之后还是字典d = {'name': 'jason', 'pwd': 123}
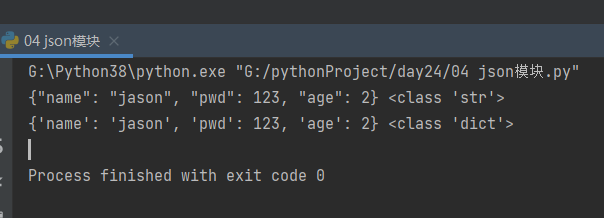
res = json.dumps(d)
print(res, type(res)) # 序列化,将其他数据类型转换成json格式字符串
# {"name": "jason", "pwd": 123, "age": 2} <class 'str'>
res1 = json.loads(res)
print(res1, type(res1)) # 反序列化,将json格式字符串转换成对应编程语言中的数据类型
# {'name': 'jason', 'pwd': 123, 'age': 2} <class 'dict'>
3. dump() 将其他数据数据以json格式字符串写入文件
4. load() 将文件中json格式字符串读取出来并转换成对应的数据类型
with open(r'b.txt','w',encoding='utf8') as f:
# f.write(json.dumps(d))
json.dump(d, f) # 直接让字典写入文件(json自动帮你完成转换)
with open(r'b.txt','r',encoding='utf8') as f:
# data = f.read()
# res = json.loads(data)
# print(res, type(res))
res = json.load(f)
print(res, type(res)) # {'name': 'jason', 'pwd': 123, 'age': 2} <class 'dict'>
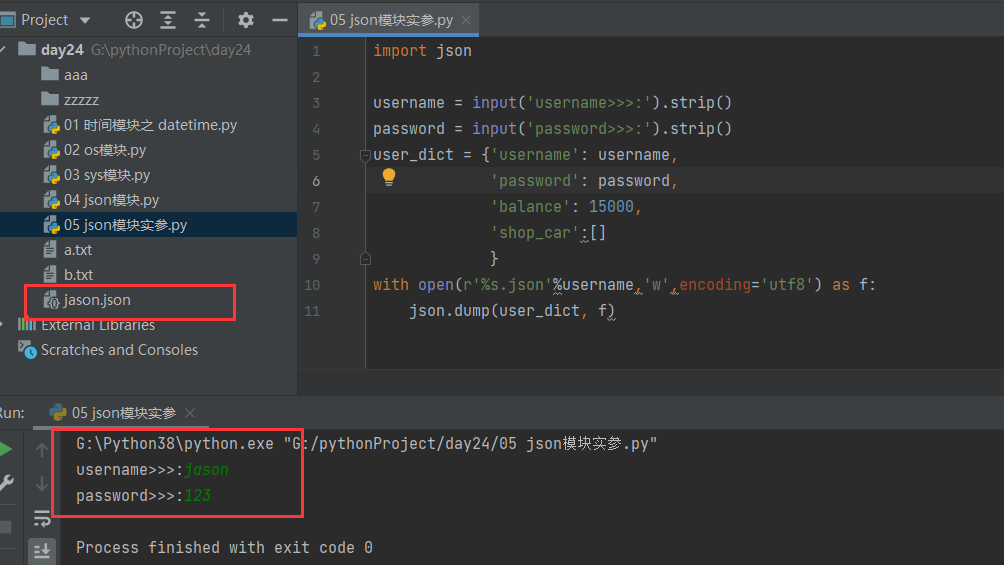
10.6.4 json模块实参
涉及到用户数据的存储 可以单用户单文件
jason.json
kevin.json
oscar.json
import json
username = input('username>>>:').strip()
password = input('password>>>:').strip()
user_dict = {'username': username,
'password': password,
'balance': 15000,
'shop_car':[]
}
with open(r'%s.json'%username,'w',encoding='utf8') as f:
json.dump(user_dict, f)

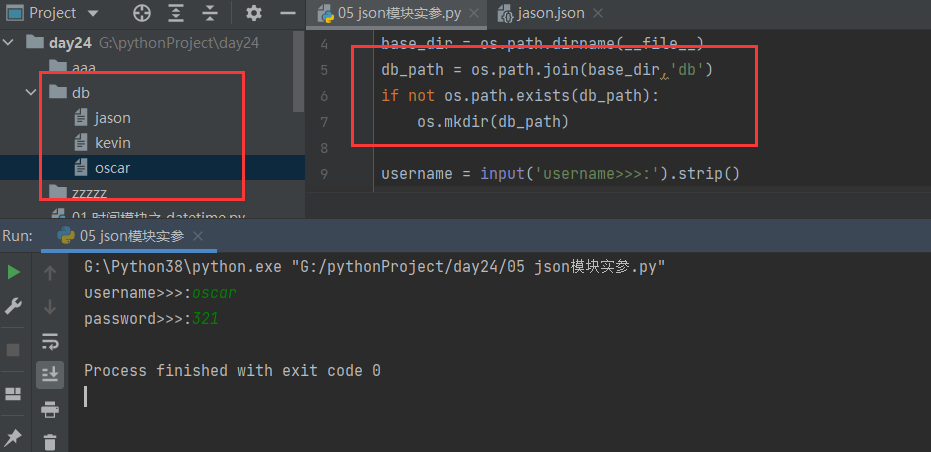
import json
import os
base_dir = os.path.dirname(__file__)
db_path = os.path.join(base_dir,'db')
if not os.path.exists(db_path):
os.mkdir(db_path)
username = input('username>>>:').strip()
password = input('password>>>:').strip()
user_dict = {'username': username,
'password': password,
'balance': 15000,
'shop_car':[]
}
file_path = os.path.join(db_path, '%s'%username)
with open(file_path,'w',encoding='utf8') as f:
json.dump(user_dict, f)
import json
import os
base_dir = r'G:\pythonProject\day24\db'
username = input('username>>>:').strip()
username_list = os.listdir(base_dir)
if username in username_list:
file_path = os.path.join(base_dir, username)
with open(file_path, 'r', encoding='utf8') as f:
data = json.load(f)
print(data, type(data))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号