FusionInsight HD组件介绍
FusionInsight HD组件介绍
FusionInsight系统的整体逻辑架构图如下所示:
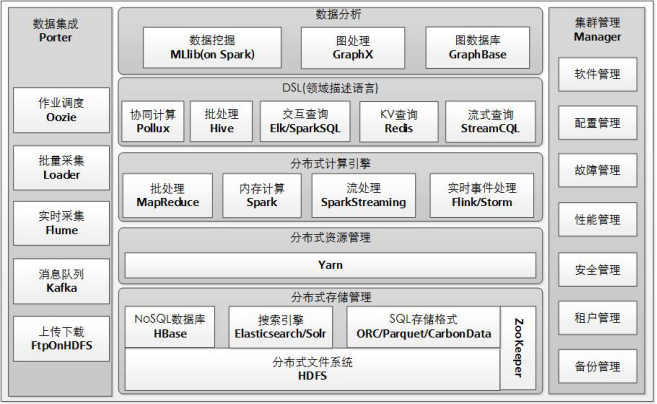
FusionInsight HD 对开源组件进行封装和增强,对外提供稳定的大容量的数据存储、查询和分析能力。
各自组件提供功能如下:
- Manager:作为运维系统,为FusionInsight HD提供高可靠、安全、容错、易用的集群管理能力,支持大规模集群的安装/升级/补丁、配置管理、监控管理、告警管理、用户管理、租户管理等。
- HDFS:Hadoop分布式文件系统(Hadoop Distributed File System),提供高吞吐量的数据访问,适合大规模数据集方面的应用。
- HBase:提供海量数据存储功能,是一种构建在HDFS之上的分布式、面向列的存储系统。
- Oozie:提供了对开源Hadoop组件的任务编排、执行的功能。以Java Web应用程序的形式运行在Java servlet容器(如:Tomcat)中,并使用数据库来存储 工作流定义、当前运行的工作流实例(含实例的状态和变量)。
- ZooKeeper:提供分布式、高可用性的协调服务能力。帮助系统避免单点故障,从而建立可靠的应用程序。
- Redis:提供基于内存的高性能分布式K-V缓存系统。
- Yarn:Hadoop 2.0中的资源管理系统,它是一个通用的资源模块,可以为各类应用程序进行资源管理和调度。
- Mapreduce:提供快速并行处理大量数据的能力,是一种分布式数据处理模式和执行环境。
- Spark:基于内存进行计算的分布式计算框架。
- Hive:建立在Hadoop基础上的开源的数据仓库,提供类似SQL的Hive QL语言操作结构化数据存储服务和基本的数据分析服务。
- Loader:基于Apache Sqoop 实现FusionInsight HD与关系型数据库、ftp/sftp文件服务器之间数据批量导入/导出工具;同时提供Java API/shell任务调度接口,供第三方调度平台调用。
- Hue:提供了开源Hadoop组件的WebUI,可以通过浏览器操作HDFS的目录和文件,调用Oozie来创建、监控和编排工作流,可操作Loader组件,查看ZooKeeper集群情况。
- Flume:一个分布式、可靠和高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写入各种数据接受方(可定制)的能力。
- Solr:一个高性能,基于Lucene的全文检索服务器。Solr对Lucene进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文检索引擎。
- Elasticsearch:一个兼有搜索引擎和NoSQL数据库功能的开源系统,基于JAVA/Lucene构建,开源、分布式、支持RESTful请求。Elasticsearch服务支持结构化、非结构化文本的多条件检索、统计和报表生成,拥有完善的监控体系,提供一系列系统,集群以及查询性能等关键指标,让用户更专注于业务逻辑的实现。多用于日志搜索和分析、时空检索、时序检索和报表、智能搜索等场景。
- Kafka:一个分布式的、分区的、多副本的实时消息发布-订阅系统。提供可扩展、高吞吐、低延迟、高可靠的消息分发服务。
- Storm:一个分布式、可靠、容错的实时流式数据处理的系统,并提供类SQL(StreamCQL)的查询语言。
- Flink:分布式的、高可用的、能保证Exactly Once语义的针对流数据和批数据的处理引擎。
- SparkSQL:基于Spark引擎的高性能SQL引擎,可与Hive实现元数据共享。
- Elk:一个分布式交互查询分析数据仓库引擎,支持标准的SQL2003规范,支持标准SQL对数据的并行插入、删除、修改、查询等功能。
- MLlib:提供基于Spark的数据挖掘算法库。
- GraphX:提供基于Spark的图处理算法库。
- GraphBase : 提供关系数据存储、查询、分析能力。
- Pollux: 一个兼容相同数据中心和跨数据中心多数据源协助查询的系统。
愿路途漫长,以后莫失莫忘。 愿你不骄不躁,安稳顺心。
作者:菜鸟-传奇
本文版权归作者和博客园共有,重在学习交流,不以任何盈利为目的,欢迎转载。
敲敲小黑板:《刑法》第二百八十五条 【非法侵入计算机信息系统罪;非法获取计算机信息系统数据、非法控制计算机信息系统罪】违反国家规定,侵入国家事务、国防建设、尖端科学技术领域的计算机信息系统的,处三年以下有期徒刑或者拘役。违反国家规定,侵入前款规定以外的计算机信息系统或者采用其他技术手段,获取该计算机信息系统中存储、处理或者传输的数据,或者对该计算机信息系统实施非法控制,情节严重的,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号