萌新的秃头之始之编码与解码
1.ASCII编码
ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准ISO/IEC 646。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符 。 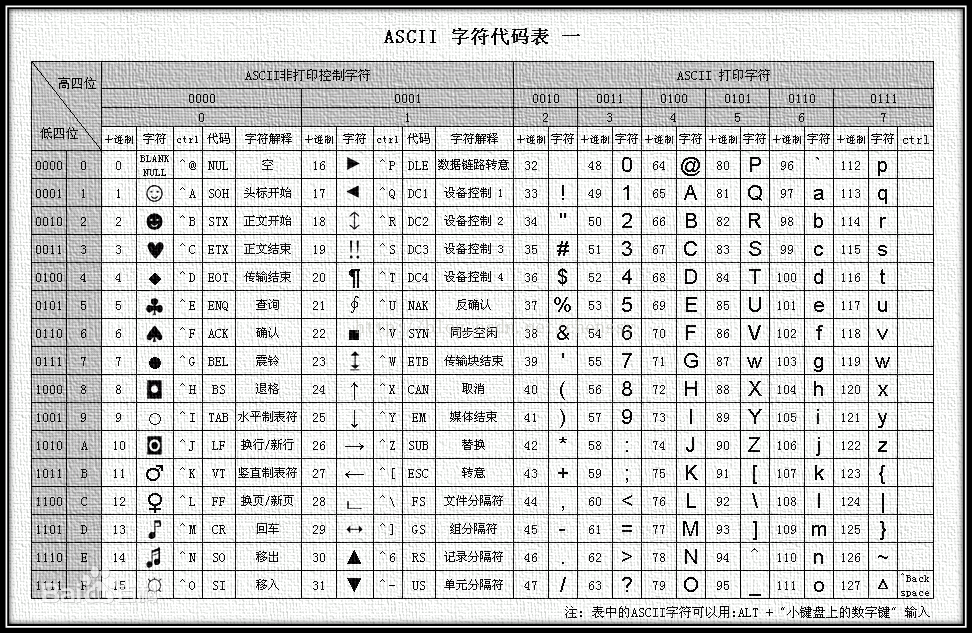
2.Unicode编码
Unicode是一个编码方案,Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
编码形式:\u0059\u006f\u0075

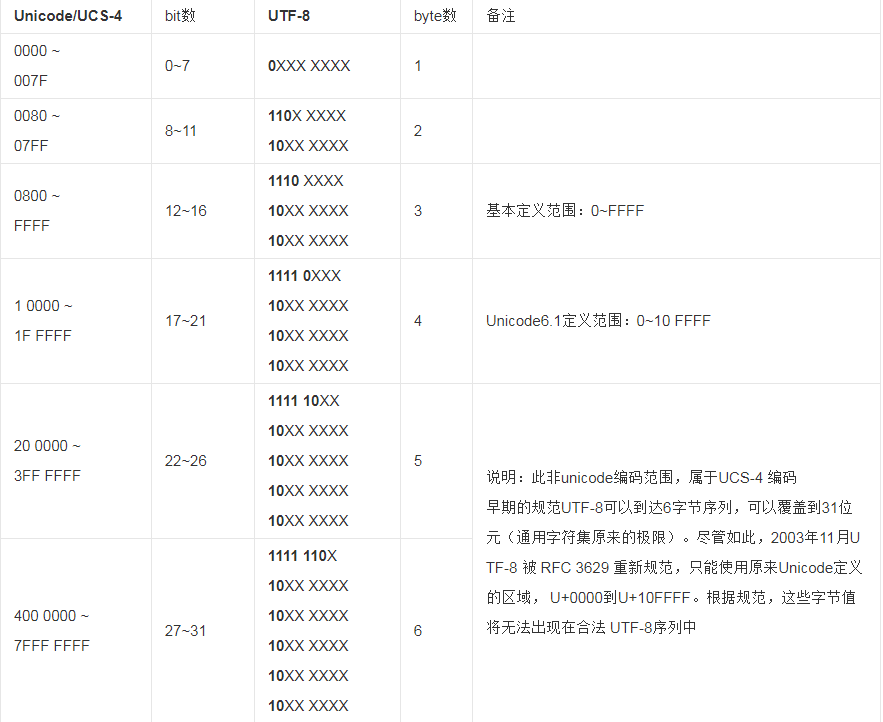
3. UTF-8编码
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部份修改后,便可继续使用。其他实现方式还包括UTF-16(字符用两个字节或四个字节表示)和UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
4.URL编码
url编码又叫百分号编码,是统一资源定位(URL)编码方式。URL地址(常说网址)规定了常用地数字,字母可以直接使用,另外一批作为特殊用户字符也可以直接用(/,:@等),剩下的其它所有字符必须通过%xx编码处理。任何特殊的字符(就是那些不是简单的七位ASCII,如汉字)将以百分符%用十六进制编码,当然也包括象 =,&;,和 % 这些特殊的字符。其实url编码就是一个字符ascii码的十六进制。不过稍微有些变动,需要在前面加上“%”。比如“\”,它的ascii码是92,92的十六进制是5c,所以“\”的url编码就是%5c。

5.Escape/Unescape编码
又叫%u编码,从以往经验看编码字符串出现有"u",它是unicode编码,那么Escape编码采用是那一种unicode实现形式呢。其实是UTF-16BE模式。这样一来问题非常简单了。 Escape编码/加密,就是字符对应UTF-16 16进制表示方式前面加%u。Unescape解码/解密,就是去掉"%u"后,将16进制字符还原后,由utf-16转码到自己目标字符。如:字符“中”,UTF-16BE是:“6d93”,因此Escape是“%u6d93”,反之也一样!因为目前%字符,常用作URL编码,所以%u这样编码已经逐渐被废弃了!
Uuencode是二进制信息和文字信息之间的转换编码,也就是机器和人眼识读的转换。Uuencode编码方案常见于电子邮件信息的传输,目前已被多用途互联网邮件扩展(MIME)大量取代。
Uuencode将输入文字以每三个字节为单位进行编码,如此重复进行。如果最后剩下的文字少于三个字节,不够的部份用零补齐。这三个字节共有24个Bit,以6-bit为单位分为4个群组,每个群组以十进制来表示所出现的数值只会落在0到63之间。将每个数加上32,所产生的结果刚好落在ASCII字符集中可打印字符(32-空白...95-底线)的范围之中。
Uuencode编码每60个将输出为独立的一行(相当于45个输入字节),每行的开头会加上长度字符,除了最后一行之外,长度字符都应该是“M”这个ASCII字符(77=32+45),最后一行的长度字符为32+剩下的字节数目这个ASCII字符。

7.Jother编码
当我们看到一大堆[]()+!这些字符组成的编码,就是Jother编码。
jother编码特点:
1、简单,不需要太多算法的知识。
2、是对javascript有了较深的了解后的产物。
具体的讲解移步大佬博客:https://blog.csdn.net/greyfreedom/article/details/45070667
解码:打开浏览器按F12,然后console将那堆解码的东西复制过去,按回车。

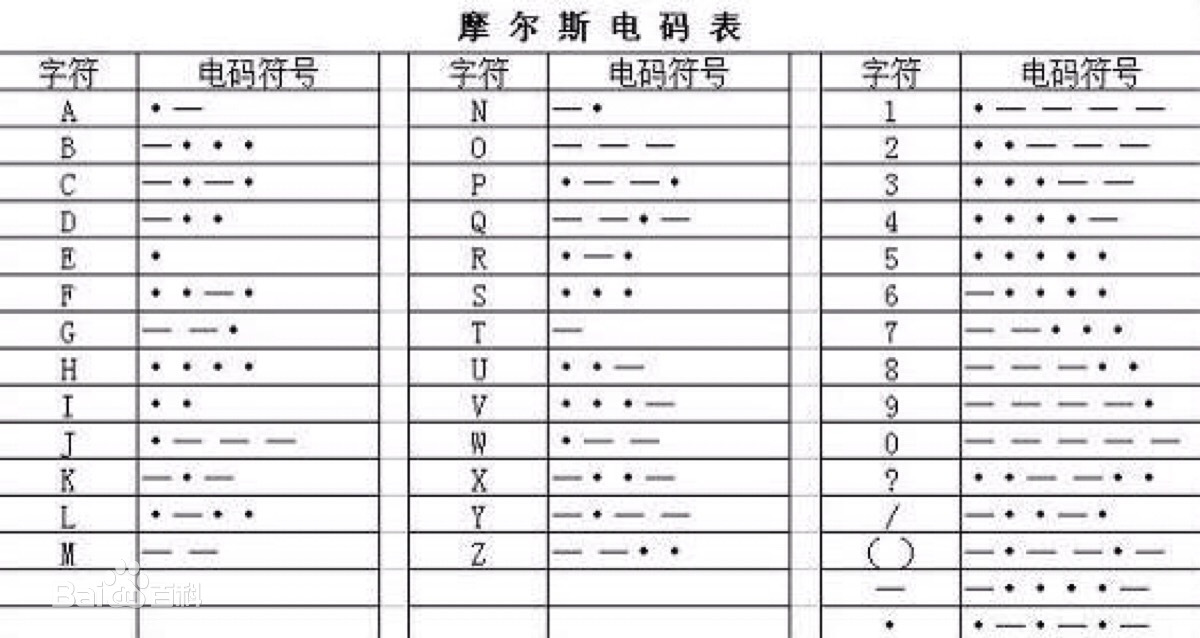
8.摩尔斯电码
摩尔斯电码(又译为摩斯密码,Morse code)是一种时通时断的信号代码,通过不同的排列顺序来表达不同的英文字母、数字和标点符号。它发明于1837年,发明者有争议,是美国人塞缪尔·莫尔斯或者艾尔菲德·维尔。 摩尔斯电码是一种早期的数字化通信形式,但是它不同于现代只使用零和一两种状态的二进制代码,它的代码包括五种: 点、划、点和划之间的停顿、每个字符之间短的停顿、每个词之间中等的停顿以及句子之间长的停顿。
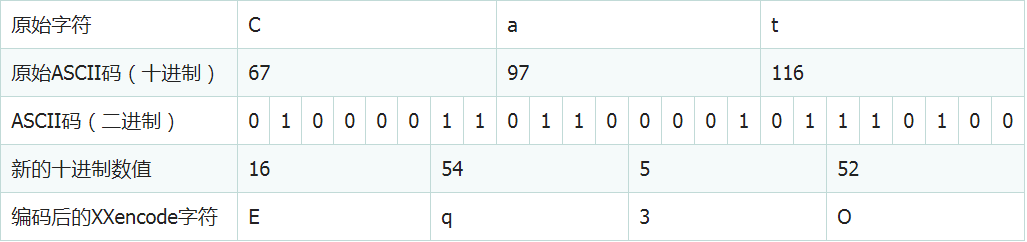
9.XXencode编码(https://www.jb51.net/article/85886.htm)
XXencode将输入文本以每三个字节为单位进行编码。如果最后剩下的资料少于三个字节,不够的部份用零补齐。这三个字节共有24个Bit,以6bit为单位分为4个组,每个组以十进制来表示所出现的数值只会落在0到63之间。以所对应值的位置字符代替。它所选择的可打印字符是:+-0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmno
pqrstuvwxyz,一共64个字符。跟base64打印字符相比,就是uuencode多一个“-” 字符,少一个”/” 字符。 但是,它里面字符顺序与Base64完全不一样。与UUencode比较,这里面所选择字符,都是常见字符,没有特殊字符。这也决定它当年流行使用原因!每60个编码输出(相当于45个输入字节)将输出为独立的一行,每行的开头会加上长度字符,除了最后一行之外,长度字符都应该是“h”这个字符(45,刚好是64字符中,第45位'h'字符),最后一行的长度字符为剩下的字节数目 在64字符中位置所代表字符。
10.Base编码(https://zhuanlan.zhihu.com/p/51316306)
base64、base32、base16可以分别编码转化8位字节为6位、5位、4位。16,32,64分别表示用多少个字符来编码,Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。

呜呜,秃了秃了,跪求大佬带带萌新啊!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号