
一、String对象支持四种利用正则表达式的方法,分别为search(),replace(),match(),split()
1、search()方法以正则表达式作为参数,返回第一个与之匹配的子串开始的位置,如果没有任何与之匹配的子串,它返回-1。
2、replace()方法执行检索和替换操作,它的第一个参数是正则表达式,第二个参数是要进行替换的字符串或者闭包。
3、 match()方法的唯一一个参数是正则表达式,它的行为取决于这个正则表达式的标志,如果正则表达式包含了标志g,它的返回值就是包含了出现在字符串中 匹配的数组。如果该正则表达式不包含标志g,它也返回一个数组,它的第一个元素是匹配的字符串,余下的元素则是正则表达式中的各个分组。
4、split()方法是能够支持模式匹配的。
二、RegExp对象定义了两个用于模式匹配的方法,它们是exec()和test()
1、 RegExp的exec()方法和String的match()方法很类似,它对一个指定的字符串执行一个正则表达式匹配,如果没有找到任何一个匹配,它 将返回null,否则返回一个数组,这个数组的第一个元素包含的是与正则表达式相匹配的字符串,余下的所有元素包含的是匹配的各个分组。而且,正则表达式 对象的index属性还包含了匹配发生的字符串的位置,属性input引用的则是被检索的字符串。
如果正则表达式具有g标志,它将把该对象的lastIndex属性设置到紧接着匹配字符串的位置开始检索,如果exec()没有发现任何匹配,它将把 lastIndex属性重置为0,这一特殊的行为可以使你可以反复调用exec()遍历一个字符串中所有的正则表达式匹配。
2、RegExp对象的test()参数为一个字符串,如果这个字符串包含正则表达式的一个匹配,它就返回true,否则返回false
当一个具有g标志的正则表达式调用test()方法时,它的行为和exec()相同,既它从lastIndex处开始检索特定的字符串,如果它发现匹配,就将lastIndex设置为紧接在那个匹配之后的字符的位置,这样我们就可以使用方法test()来遍历字符串了。
RegExp
RegExp 对象来使用正则表达式,要创建 RegExp 对象有两种方法,
var patt = new RegExp(pattern, modifiers); var patt = /pattern/modifiers;
参数说明如下:
- pattern:正则表达式,按照正则表达式的语法定义的正则表达式;
- modifiers:修饰符,用来设置字符串的匹配模式,可选值如下表所示:
| 修饰符 | 描述 |
|---|---|
| i | 执行对大小写不敏感的匹配 |
| g | 执行全局匹配(查找所有的匹配项,而非在找到第一个匹配项后停止) |
| m | 执行多行匹配 |
| s | 允许使用.匹配换行符 |
| u | 使用 Unicode 码的模式进行匹配 |
| y | 执行“粘性”搜索,匹配从目标字符串的当前位置开始 |
提示:在正则表达式中.、*、?、+、[、]、(、)、{、}、^、$、|、\等字符被赋予了特殊的含义,若要在正则表达式中使用这些字符的原本意思时,需要在这些字符前添加反斜线进行转义,例如若要匹配.,则必须编写为\.。
描述字符
根据正则表达式语法规则,大部分字符仅能够描述自身,这些字符被称为普通字符,如所有的字母、数字等。

描述字符范围
在正则表达式语法中,放括号表示字符范围。在方括号中可以包含多个字符,表示匹配其中任意一个字符。如果多个字符的编码顺序是连续的,可以仅指定开头和结尾字符,省略中间字符,仅使用连字符~表示。如果在方括号内添加脱字符^前缀,还可以表示范围之外的字符。例如:
- [abc]:查找方括号内任意一个字符。
- [^abc]:查找不在方括号内的字符。
- [0-9]:查找从 0 至 9 范围内的数字,即查找数字。
- [a-z]:查找从小写 a 到小写 z 范围内的字符,即查找小写字母。
- [A-Z]:查找从大写 A 到大写 Z 范围内的字符,即查找大写字母。
- [A-z]:查找从大写 A 到小写 z 范围内的字符,即所有大小写的字母。
示例1
字符范围遵循字符编码的顺序进行匹配。如果将要匹配的字符恰好在字符编码表中特定区域内,就可以使用这种方式表示。
如果匹配任意 ASCII 字符:
var r = /[\u0000-\u00ff]/g;
如果匹配任意双字节的汉字:
var r = /[^\u0000-\u00ff]/g;
如果匹配任意大小写字母和数字:
var r = /[a-zA-Z0-9]/g;
使用 Unicode 编码设计,匹配数字:
var r = /[\u0030-\u0039]/g;
使用下面字符模式可以匹配任意大写字母:
var r = /[\u0041-\u004A]/g;
使用下面字符模式可以匹配任意小写字母:
var r = /[\u0061-\u007A]/g;
示例2
在字符范围内可以混用各种字符模式。
var s = "abcdez"; //字符串直接量 var r = /[abce-z]/g; //字符a、b、c,以及从e~z之间的任意字符 var a = s.match(r); //返回数组["a","b","c","e","z"]
示例3
在中括号内不要有空格,否则会误解为还要匹配空格。
var r = /[0-9]/g;
示例4
字符范围可以组合使用,以便设计更灵活的匹配模式。
var s = "abc4 abd6 abe3 abf1 abg7"; //字符串直接量 var r = /ab[c-g][1-7]/g; //前两个字符为ab,第三个字符为从c到g,第四个字符为1~7的任意数字 var a = s.match(r); //返回数组["abc4","abd6","abe3","abf1","abg7"]
示例5
使用反义字符范围可以匹配很多无法直接描述的字符,达到以少应多的目的。
var r = /[^0123456789]/g;
在这个正则表达式中,将会匹配除了数字以外任意的字符。反义字符类比简单字符类的功能更强大和实用。
选择匹配
选择匹配类似于 JavaScript 的逻辑与运算,使用竖线|描述,表示在两个子模式的匹配结果中任选一个。例如:
1) 匹配任意数字或字母
var r = /\w+|\d+/;
2) 可以定义多重选择模式。设计方法:在多个子模式之间加入选择操作符。
var r = /(abc)|(efg)|(123)|(456)/;
为了避免歧义,应该为选择操作的多个子模式加上小括号。
示例
设计对提交的表单字符串进行敏感词过滤。先设计一个敏感词列表,然后使用竖线把它们连接在一起,定义选择匹配模式,最后使用字符串的 replace() 方法把所有敏感字符替换为可以显示的编码格式。代码如下:
var s = '<meta charset="utf-8">'; //待过滤的表单提交信息 var r = /\'|\"|\<|\>/gi; //过滤敏感字符的正则表达式 function f() { //替换函数 ////把敏感字符替换为对应的网页显示的编码格式,&#+unicode 为html解析 Unicode 的方式 return "&#" + arguments[0].charCodeAt(0) + ";"; } var a =s.replace(r,f); //执行过滤替换 document.write(a); //在网页中显示正常的字符信息 console.log(a);
重复匹配
在正则表达式语法中,定义了一组重复类量词,如表所示。它们定义了重复匹配字符的确数或约数。
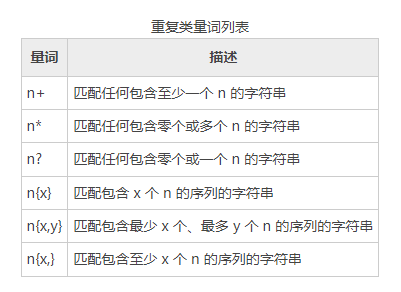
示例
下面结合示例进行演示说明,先设计一个字符串:
var s = "ggle gogle google gooogle goooogle gooooogle goooooogle gooooooogle goooooooogle";
1) 如果仅匹配单词 ggle 和 gogle,可以设计:
var r = /go?gle/g; var a = s.match(r);
量词?表示前面字符或子表达式为可有可无,等效于:
var r = /go{0,1}gle/g; var a = s.match(r);
2) 如果匹配第 4 个单词 gooogle,可以设计:
var r = /go{3}gle/g; var a = s.match(r);
等效于:
var r = /gooogle/g; var a = s.match(r);
3) 如果匹配第 4 个到第 6 个之间的单词,可以设计:
var r = /go{3,5}gle/g; var a = s.match(r);
4) 如果匹配所有单词,可以设计:
var r = /go*gle/g; var a = s.match(r);
量词*表示前面字符或表达式可以不出现,或者重复出现任意多次。等效于:
var r = /go(0,)gle/g; var a = s.match(r);
5) 如果匹配包含字符“o”的所有词,可以设计:
var r = /go+gle/g; var a = s.match(r);
量词+表示前面字符或子表达式至少出现 1 次,最多重复次数不限。等效于:
var r = /go{1,}gle/g; var a = s.match(r);
重复类量词总是出现在它们所作用的字符或子表达式后面。如果想作用于多个字符,需要使用小括号把它们包裹在一起形成一个子表达式。
惰性匹配
重复类量词都具有贪婪性,在条件允许的前提下,会匹配尽可能多的字符。
- ?、{n} 和 {n,m} 重复类具有弱贪婪性,表现为贪婪的有限性。
- *、+ 和 {n,} 重复类具有强贪婪性,表现为贪婪的无限性。
示例1
越是排在左侧的重复类量词匹配优先级越高。下面示例显示当多个重复类量词同时满足条件时,会在保证右侧重复类量词最低匹配次数基础上,使最左侧的重复类量词尽可能占有所有字符。
var s = "<html><head><title></title></head><body></body></html>"; var r = /(<.*>)(<.*>)/ var a = s.match(r); //左侧表达式匹配"<html><head><title></title></head><body></body></html>" console.log(a[1]); console.log(a[2]); //右侧表达式匹配“</html>”
与贪婪匹配相反,惰性匹配将遵循另一种算法:在满足条件的前提下,尽可能少的匹配字符。定义惰性匹配的方法:在重复类量词后面添加问号?限制词。贪婪匹配体现了最大化匹配原则,惰性匹配则体现最小化匹配原则。
示例2
下面示例演示了如何定义匹配模式。
var s = "<html><head><title></title></head><body></body></html>"; var r = /<.*?>/ var a = s.match(r); //返回单个元素数组["<html>"]
在上面示例中,对于正则表达式 /<.*?>/ 来说,它可以返回匹配字符串 "<>",但是为了能够确保匹配条件成立,在执行中还是匹配了带有 4 个字符的字符串“html”。惰性取值不能够以违反模式限定的条件而返回,除非没有找到符合条件的字符串,否则必须满足它。
针对 6 种重复类惰性匹配的简单描述如下:
- {n,m}?:尽量匹配 n 次,但是为了满足限定条件也可能最多重复 m 次。
- {n}?:尽量匹配 n 次。
- {n,}?:尽量匹配 n 次,但是为了满足限定条件也可能匹配任意次。
- ??:尽量匹配,但是为了满足限定条件也可能最多匹配 1 次,相当于 {0,1}?。
- +?:尽量匹配 1 次,但是为了满足限定条件也可能匹配任意次,相当于 {1,}?。
- *? :尽量不匹配,但是为了满足限定条件也可能匹配任意次,相当于 {0,}?。
边界量词
边界就是确定匹配模式的位置,如字符串的头部或尾部,具体说明如表所示。

var s = "how are you"
1) 匹配最后一个单词
var r = /\w+$/; var a = s.match(r); //返回数组["you"]
2) 匹配第一个单词
var r = /^\w+/; var a = s.match(r); //返回数组["how"]
3) 匹配每一个单词
var r = /\w+/g; var a = s.match(r); //返回数组["how","are","you"]
声明词量
一共分为四种
- (?=a) 零宽正向先行断言
- (?!a)零宽负向先行断言
- (?<=a)零宽正向后行断言
- (?<!a)零宽负向后行断言
专业术语听起来确实有点云里雾里,通俗的讲就是匹配某个位置,位置指某个字符的左边或右边,零宽指的是不替换字符左右的字符,而是插入该位置。
(?=a) 零宽正向先行断言
该正则匹配某字符前面的位置。
let reg = /(?=o)/g let str = 'hello world' let s = str.replace(reg,'A') console.log(s) //输出hellAo wAorld
经过上面的代码可以看到,A匹配到了o前面的位置
let reg = /l(?=o)/g let str = 'hello world' let s = str.replace(reg,'A') console.log(s) //输出helAo world
该正则匹配后面紧跟o的l字符,只有第二个l满足该条件,所以被替换
(?!a)零宽负向先行断言
与上面的(?!a)相反,这个表达式匹配后面没有a字符的位置
let reg = /(?!l)/g let str = 'hello' let s = str.replace(reg,'A') console.log(s) //输出AhAellAoA
该正则匹配后面没有字符l的位置,因此除了两个l字母前,均插入了A字符
let reg = /l(?!o)/g let str = 'hello' let s = str.replace(reg,'A') console.log(s) //输出heAlo
该正则表示匹配后面无o字符的l字符,因为只有第一个l后面没有o,因此被替换
(?<=a)零宽正向后行断言
与(?=a)位置相反,匹配a字符后面的位置
let reg = /(?<=l)/g let str = 'hello' let s = str.replace(reg,'A') console.log(s) //输出helAlAo
该正则匹配了所有l后面的位置,在该位置插入A字符
let reg = /(?<=l)o/g let str = 'hello' let s = str.replace(reg,'A') console.log(s) //输出hellA
该正则匹配前面为l的o字符
(?<!a)零宽负向后行断言
与(?!a)位置相反,匹配前面没有a字符的位置
let reg = /(?<!l)/g let str = 'hello' let s = str.replace(reg,'A') console.log(s) //输出AhAeAlloA
该正则匹配所有前面没有l的位置
let reg = /(?<!e)l/g let str = 'hello' let s = str.replace(reg,'A') console.log(s) //输出helAo
只有第二个l前面没有e因此,第二个被替换
总结
- (?=a) 零宽正向先行断言 可以理解为一个指针从第一个字符前面开始,由前向后移动,碰到a字符时在a字符前面停下,代表该位置
- (?<=a)零宽正向后行断言 可以理解为一个指针从最后一个字符后面开始,由后向前移动,碰到a字符时在a字符后面停下,代表该位置
- (?!a)零宽负向先行断言 与(?=a)相反,除去a前面的所有位置都将被匹配
- (?<!a)零宽负向后行断言 与(?<=a)相反,除去a后面所有位置都将被匹配
使用正则表达式
JavaScript RegExp 对象中提供了一些列方法来执行正则表达式,如下表所示:
| 方法 | 描述 |
|---|---|
| compile() | 在 1.5 版本中已废弃,编译正则表达式 |
| exec() | 在字符串搜索匹配项,并返回一个数组,若没有匹配项则返回 null |
| test() | 测试字符串是否与正则表达式匹配,匹配则返回 true,不匹配则返回 false |
| toString() | 返回表示指定对象的字符串 |
此外 String 对象中也提供了一些方法来执行正则表达式,如下表所示:
| 方法 | 描述 |
|---|---|
| search() | 在字符串中搜索匹配项,并返回第一个匹配的结果,若没有找到匹配项则返回 -1 |
| match() | 在字符串搜索匹配项,并返回一个数组,若没有匹配项则返回 null |
| matchAll() | 在字符串搜索所有匹配项,并返回一个迭代器(iterator) |
| replace() | 替换字符串中与正则表达式相匹配的部分 |
| split() | 按照正则表达式将字符串拆分为一个字符串数组 |
贪婪 * 和惰性 *?
var str = '{{name}}---{{val}}123{{sex}}'
// 贪婪匹配 str.match(/\{\{(.*)\}\}/g)
--- ["{{name}}---{{val}}123{{sex}}"]
// 惰性匹配 str.match(/\{\{(.*?)\}\}/g)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号