java基础知识--01
java基础知识
树越要往上长,它的根,越是要往下扎。 共勉!
接口和抽象类有什么区别?
接口的设计目的,是对类的行为进行约束(更准确的说是一种“有”约束,因为接口不能规定类不可以有什么行为),也就是提供一种机制,可以强制要求不同的类具有相同的行为。它只约束了行为的有无,但不对如何实现行为进行限制。对“接口为何是约束”的理解,我觉得配合泛型食用效果更佳。
而抽象类的设计目的,是代码复用。当不同的类具有某些相同的行为(记为行为集合A),且其中一部分行为的实现方式一致时(A的非真子集,记为B),可以让这些类都派生于一个抽象类。在这个抽象类中实现了B,避免让所有的子类来实现B,这就达到了代码复用的目的。而A减B的部分,留给各个子类自己实现。正是因为A-B在这里没有实现,所以抽象类不允许实例化出来(否则当调用到A-B时,无法执行)。
作者:阿法利亚
链接:https://www.zhihu.com/question/20149818/answer/150169365
来源:知乎
接口可以继承接口
抽象类可以实现接口
抽象类可以继承实体类,但和实体类的继承一样,也要求父类可继承,并且拥有子类可以访问到的构造器。
抽象类中可以有静态的main方法。
其实,抽象类和普通类的唯一区别就是不能创建实例对象和允许有abstract方法。
反射
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制。
- 获取对象的类 (getClass)
- 获取对象的属性(getFields / getDeclaredFields )
- 获取对象方法 (getMethod / getDeclaredMethods)
- 动态执行方法 object.invoke(methodName,参数1,2,3)
- 创建对象 Class.newInstance
- 学到了再补充…
Overload和Override的区别
Overload:
同一个类中,方法名一样,参数不一样,构成重载。
注意返回值不一样,参数一样,不构成重载
Override:
子类继承父类,重写了父类中某个方法,方法名,返回值,参数都一样,构成重写/覆盖。
注意:如果父类方法抛出RuntimeException,那么子类不能抛出Exception,只能抛出RuntimeException及其子类
== 和 equals() 的区别
==:
比较栈中地址是否一样
equals:
比较保存在栈的地址所指向的堆的内容是否一致
注意:
Object的equals是==。
类对象.equals(类对象),需要重写equals方法,才能做到比较内容而不是比较内存地址
堆、栈知识详解:
https://blog.csdn.net/qq_41498261/article/details/83583466
List Set Map区别
List Set 是Collection子类
List:
是一个有序的集合,可以插入重复值,null。
ArrayList底层是数组结构
LinkList底层是链表结构
Set:
是一个无序的集合,只能有一个null,不能插入重复值。重复值用hashCode()与equals()判断,如果hashcode一样,则用equals判断是否为同一个对象,故插入对象必须有equals方法。
HashSet : 为快速查找设计的Set。存入HashSet的对象必须定义hashCode()。
TreeSet : 保存次序的Set, 底层为树结构。使用它可以从Set中提取有序的序列。
LinkedHashSet : 具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
参考连接:
https://blog.csdn.net/mashaokang1314/article/details/83721792
Hashtable 和 HashMap的区别
继承的类不一样,Hashtable 继承自 Dictionary而 HashMap继承自AbstractMap
Hashtable :
方法是同步的
不允许value= null、key= null
HashMap:
方法是非同步的
允许key=null、value = null
Hashtable put方法的源码:
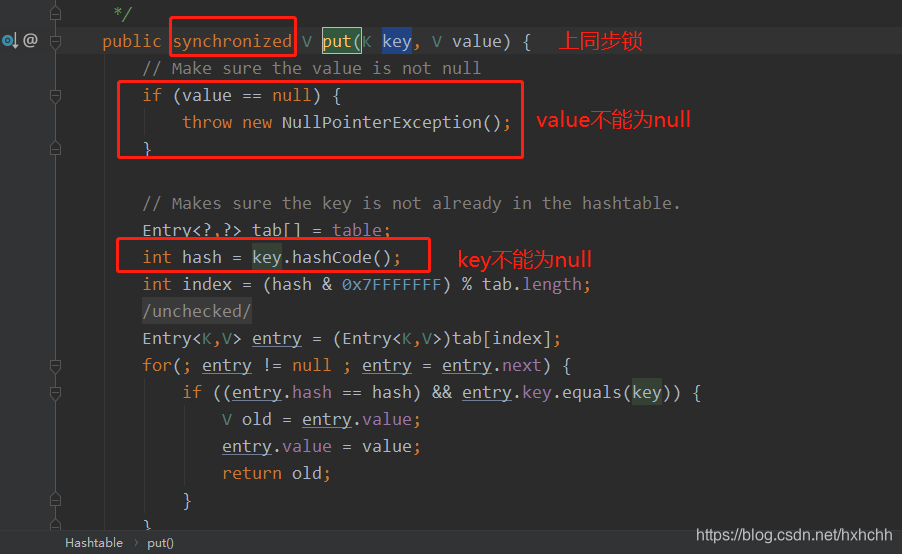
参考连接:
https://blog.csdn.net/java2000_net/article/details/2512510
map用法及遍历:
https://blog.csdn.net/qq_29373285/article/details/81487594
线程
创建:
1、继承线程类 extends Thread
2、实现接口 implements Runnable,然后new Thread(Runnable,ThreadName)新建线程
3、实现接口 implements Callable<返回类型> ,重写call方法、new FutureTask去包装该对象,作为入参新建 Thread。它可以有返回值
参考连接:
https://www.cnblogs.com/nongzihong/p/10512566.html
线程状态:
新建状态:刚new出来的时候
就绪:线程start
运行:线程获取cpu
阻塞:sleep或者wait
销毁:销毁后不可复用
sleep 和 wait区别:
sleep:不去争CPU,如果获取了同步锁,也不会释放同步锁。sleep是Thread类的静态方法,它更像是为了暂停而暂停,与同步锁的关系不大。可以在线程的任意地方使用,但是要捕获异常;sleep参数为毫秒,睡眠结束后,不会立即获取CPU,而是开始加入竞争CPU的队列,就像新来的一样。
wait:
wait是Object的方法,也就是说可以对任意一个对象调用wait方法,调用wait方法(无参)将会将调用者的线程挂起,直到其他线程调用同一个对象的notify方法才会重新激活调用者。
暂停后,不去争CPU,释放锁。参数为毫秒(可以无参),时间到后,检测是否可以获取锁,如果不可以,继续等待。
无参数的情况下,必须外界干预才能唤醒,如notify。
只能在同步控制方法或者同步控制块里面使用
join():
让父线程等待子线程结束之后才能继续运行。
生产者消费者模型理解:
https://ask.csdn.net/questions/7407745?expend=true
多线程:
线程池创建:
1、newFiexedThreadPool(int Threads):创建固定数目线程的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
//注意任务队列长度
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
2、newCachedThreadPool():创建一个可缓存的线程池,调用execute 将重用以前构造的线程(如果线程可用)。如果没有可用的线程,则创建一个新线程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
//注意最大线程数
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
3、newSingleThreadExecutor()创建一个单线程化的Executor。
//注意队列长度
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
4、newScheduledThreadPool(int corePoolSize)创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
//注意最大线程数
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
线程池创建的正确方式:
不使用Executors的创建的原因:

正确的创建方式:
new ThreadPoolExecutor(参数…);
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters and default thread factory and rejected execution handler.
* It may be more convenient to use one of the {@link Executors} factory
* methods instead of this general purpose constructor.
*
* @param corePoolSize 保留在池中的线程数,即使如果它们空闲,
* 除非设置了{@code allowCoreThreadTimeOut}
* @param maximumPoolSize 允许最大的线程数目
* @param keepAliveTime 当线程数目大于核心数目,多余空闲线程最长的等待新任务时间
* @param keepAliveTime的时间单位,如TimeUnit.SECONDS
* @param workQueue 阻塞队列,如new ArrayBlockingQueue<>(10)
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue} is null
*/
队列阻塞:
A. 如果运行的线程少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队。
B. 如果运行的线程等于或多于 corePoolSize,则 Executor 始终首选将请求加入队列,而不添加新的线程。
C. 如果无法将请求加入队列,则创建新的线程,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。
总结:
- 线程池可立即运行的最大线程数 即maximumPoolSize 参数。
- 线程池能包含的最大线程数 = 可立即运行的最大线程数 + 线程队列大小 (一部分立即运行,一部分装队列里等待)
- 核心线程数可理解为建议值,即建议使用的线程数,或者依据CPU核数
- add,offer,put三种添加线程到队列的方法只在队列满的时候有区别,add为抛异常,offer返回boolean值,put直到添加成功为止。
- 同理remove,poll, take三种移除队列中线程的方法只在队列为空的时候有区别, remove为抛异常,poll为返回boolean值, take等待直到有线程可以被移除。
参考连接1:
https://blog.csdn.net/cheng911215/article/details/38707871
参考连接2:
https://ifeve.com/java-blocking-queue/
线程池线程复用原理:
线程完成一个run任务后,不会销毁该线程,而是从任务队列寻找下一个任务,相当于把所有任务的run方法串连起来。
参考连接:
https://www.cnblogs.com/qq289736032/p/11159951.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号