软件工程寒假作业(2/2)
软件工程寒假作业(2/2)
作业摘要
| 这个作业属于哪个课程 | 2021春软件工程实践S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 1.阅读《构建之法》提问五个问题 2.完成词频统计作业 |
| 其他参考文献 | CSDN、博客园、Git、《构建之法》 |
目录:
Part1 阅读《构建之法》提问
阅读构建之法并提问
1.1我的问题:在讲述团队类型这小节内容时我看到这样一句话“软件团队有各种形式, 适用于不同的人员和需求。”,后面也提到了“随着团队的成熟和坏境的变化, 团队模式会演变成下面的几种形式”,有了这个问题(更具体点,团队模式会因为哪些因素而发生变化)
思考如下:书中列举了包括一窝蜂模式、主治医生模式、明星模式、社区模式、业余剧团模式等团队模式,团队模式的变化可能和上级的指示、项目的性质有关,如秘密团队、特工团队就和其他团队性质很不一样。还可能和公司本身的体系成熟度有关,刚开的小公司里面的团队模式可能就是一窝蜂团队,随着公司的制度体系不断完善,团队模式也会趋近成熟。好的软件开发离不开好的团队模式,只有不断探索出好的团队合作模式,才能为软件注入新血液。
1.2我的问题:在设计和开发章节提到了用户体验,很多章节也提到要注重用户体验,软件最终是为用户服务的。而且提到在用很久后,软件会越发难用,在用户长期使用但逐渐厌弃该软件,这是用户的问题还是开发团队的问题
思考如下:用户刚开始选择该软件并长期使用,证明该软件有利于该用户的工作生活,而使用时间愈长,对该软件的了解愈深,用户有了对该软件功能的新想法,用户可以选择及时和该软件的后台客服反映。软件开发方也应该及时收纳汇总不同用户的反馈,开发新的功能完善版本,这是双向反馈的过程,应该双方一起努力。
1.3我的问题:在角色-PM这小节,有个标题“PM做开发和测试之外的所有事情”,之前也学了一点和产品有关的知识,发现PM至少要学会Axture、墨刀等这些软件来画产品原型图。除此之外,和程序员的沟通交流也十分重要,也有过这样的疑惑:对PM来说,开发和测试并不是硬性要求对吗
思考如下:讲义之后的内容举例了微软公司的PM分类,有很多种:有做功能设计的PM; 有些需要对商业和客户很强的了解能力 (如 Office 应用软件的PM );有些需要广泛的经验和知识面, 商业拓展能力 (如 MSN 部门的 PM)等等(可能是大公司所以对应的PM类别更多、分工更细),对于PM来说,最大、最独特的贡献是保持团队的平衡,作为PM,更重要的是有自己的产品思维,有同理心,协调项目的进度,在程序员和客户之间充当沟通的桥梁。编码能力不是产品经理的硬性要求,但懂一些编程知识能够更有利于PM和程序员的需求沟通,也能很好缓和二者关系。
1.4我的问题:本书第4章“两人合作”中介绍到:代码复审核查表的其中一项内容是“代码容易维护么?”因为容易是个相对的概念,于是产生了这样的疑问“代码的容易维护是站在复审人员认为的容易还是代码达到了团队规定的编译警告等级”
思考如下:查阅资看到一个笔者将代码的可维护性分为编写时可维护性和运行时可维护性,编写时可维护性是指出现bug时能及时扑灭这个bug又不产生新bug,这时候的可维护性我觉得是站在复审人员角度考虑较为稳妥;运行时的可维护性是指在系统运行过程中(或无需再次编码发布、只需系统重启一次)修改系统的某项配置并使其生效,且不影响现在正在进行的业务和用户的操作,这时候可能和团队规定的编译警告等级有关(感觉。。)
1.5我的问题:讲义中将代码量比作树叶量,“代码量等于树叶量,当作如是观。 ”,那么,是否代码量越多,该程序员能力就越强
思考如下:测试人员的“量”的评价方法不是根据发现bug的多少来定义,开发人员的“量”也不是看代码量的多少,开发人员的成长应该是看代码是否有机结合起来解决客户的问题。
附加题
60年代中期,大容量、高速度计算机的出现,使计算机的应用范围迅速扩大,软件开发急剧增长。高级语言开始出现;操作系统的发展引起了计算机应用方式的变化;大量数据处理导致第一代数据库管理系统的诞生。软件系统的规模越来越大,复杂程度越来越高,软件可靠性问题也越来越突出。原来的个人设计、个人使用的方式不再能满足要求,迫切需要改变软件生产方式,提高软件生产率,软件危机开始爆发 。
part2:词频统计程序
1. Github项目地址
2. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| • Estimate | • 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 430 | 545 |
| • Analysis | • 需求分析(包括学习新技术) | 40 | 60 |
| • Design Spec | • 生成设计文档 | 20 | 30 |
| • Design View | • 设计复审 | 10 | 15 |
| • Coding Standard | • 代码规范(为目前的开发制定合适的规范) | 20 | 30 |
| • Design | • 具体设计 | 20 | 20 |
| • Coding | • 具体编码 | 250 | 300 |
| • Coding Review | • 代码复审 | 30 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| Reporting | 报告 | 80 | 105 |
| • Test Repor | • 测试报告 | 45 | 60 |
| • Size Measurement | • 计算工作量 | 15 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 25 |
| 合计 | 530 | 670 |
3.解题思路描述
- 需求分析
- 从某文件获取输入
- 统计字符数
- 统计单词数
- 统计有效行数
- 统计最多的十个单词及词频
- 将上述统计结果输出至输出文件 - 思路
首先,利用FileInputStream和StringBuffer将文件内容读入转化成字符串方便后续操作
其次,针对统计字符数功能,一个一个字符判断ASCII码是否处于32和126之间或是'\t\n\r'三者之一。针对统计单词数问题,先根据空白字符来进行分词操作,然后再根据单词的要求,即长度、格式等规定进行判断,然后再返回总数。
针对统计有效行数,和统计单词数目类似的,先分隔行,以'\n'划分,然后存入字符数组,最后再遍历数组,判断字符串的长度是否为0来得到有效行数的个数。
统计最多的十分单词及词频刚开始没有什么思路,查阅了CSDN后用了Map来存储,先和前面需求一样判断是否为单词,再把英文字母化成小写,再用Map存储,如果没存过,就将其存入并置value为1,若存过,则将该值增1,最后排序输出即可。
4. 代码制定规范
5.计算模块接口的设计与实现过程
相关类的设计
根据程序功能要求,划分为一个主函数和两个类
- WorldCount.java 主函数
- FileDeal.java 实现文件的读取和写入
- WordCount.java 完成统计字符数、单词数、有效行数和单词词频的功能
相关函数的设计
-
FileDeal.java:
ReadFile(String path)//文件读取
WriteToFile(String str,String file)//文件写入 -
WordDeal.java
getCharCount()//统计文件字符数
getWordCount()//统计单词总数
getLineCount()//统计有效行数
getWordFreq()//将单词存入Map且排序
ListToArray()//将排完序的List元素筛出前十个并存入数组
核心函数的流程图
getWordFreq():单词存入Map且排序
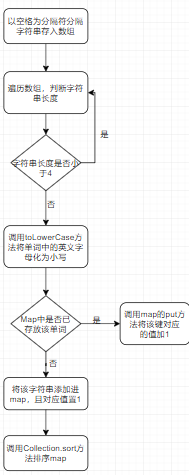
关键代码
getCharCount()根据ascii码来判断是否为字符
if (c >= 32 && c <= 126 || c == '\n' || c == '\t' || c == '\r')
{
charNum++;
}
以正则表达式"\s"为分隔符来分隔字符串放入字符数组,遍历字符串数组,根据长度先筛出不符合要求的,如果长度小于4则直接遍历下一个
String[] sp = s.split("\\s");
for (int i = 0; i < sp.length; i++)
{
if (sp[i].length() < 4)
{
continue;
}
}
当长度符合要求就判断前4位是否都为英文字母,设置标志位flag初始值为1,如果不是英文字母flag置0
else
{
// 判断字符串的前四位是否是英文字母
int flag = 1;
char c;
for (int j = 0; j < 4; j++)
{
c = sp[i].charAt(j);
if (!(c >= 'A' && c <= 'Z' || c >= 'a' && c <= 'z'))
{
flag = 0;
}
}
统计有效行数用"\n"为分隔符分隔后,trim()去掉空格后判断字符串长度是否为0来判断该行是否有效
for (int i = 0; i < line.length; i++)
{
if (line[i].trim().length() == 0)
continue;
validLine = validLine + 1;
}
统计单词词频率是先判断是否为单词(判断方法与统计单词数一样),再根据hashmap的get方法判断map中是否存在该键,存在则值加1,否则就存入该键
if (wordFrequence.get(spWord[i]) == null)
{
wordFrequence.put(spWord[i], 1);
}
else
wordFrequence.put(spWord[i], wordFrequence.get(spWord[i]) + 1);
map排序采用Collection的sort方法,其中重写了compare方法来按字典排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>()
{
// 对Map中内容进行排序,先按词频后按字典顺序
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2)
{
if (o1.getValue() == o2.getValue())
{
return o1.getKey().compareTo(o2.getKey());
}
return o2.getValue() - o1.getValue();
}
}
);
6.单元测试与性能分析
单元测试采用Java的JUint框架,编写WordDealTest测试类来测试,如下
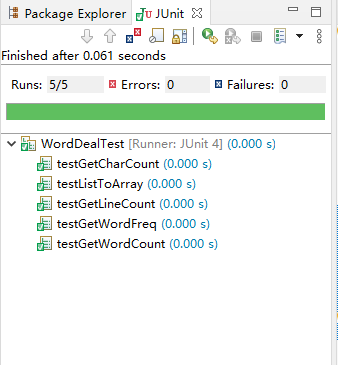
6.1 统计字符数测试
@Test
public void testGetCharCount() throws IOException
{
String textString="";
String text1 = "abcd8.+*1\n";
int loop=100;
for(int i=0;i<loop;i++)
textString+=text1;
WordDeal wd1 = new WordDeal(textString);
int cn1 = wd1.getCharCount();
assertEquals(1000, cn1);
}
6.2 统计单词数测试
测试用例含不满足长度要求的、不满足前4位为英文的,满足前两者要求但除英文与数字外有其他字符
@Test
public void testGetWordCount() throws IOException
{
String text1 = "";
String str[]={"word1","word2","file","你好","123file","file123","fil123","你好ii","fil","file*"};
for(int i=0;i<str.length;i++)
{
text1+=str[i]+" ";
}
WordDeal wd1 = new WordDeal(text1);
int wn1 = wd1.getWordCount();
assertEquals(4, wn1);
}
6.3 统计有效行数测试
测试空白行数多变情况
@Test
public void testGetLineCount() throws IOException
{
String text1="abcd\n222\n\n\n\n3123\n\n";
WordDeal wd1 = new WordDeal(text1);
int wn2 = wd1.getLineCount();
assertEquals(3, wn2);
}
6.4 获取频率最高的十个单词测试
测试的主要用例为同频率,按字典排序
@Test
public void testListToArray() throws IOException
{
String text1="";
String strs[]= {"word1","word2","word3","word4","word5","word5","word6","word7",
"word8","word9","word0"};
for(int i=0;i<strs.length;i++)
{
text1+=strs[i]+" ";
}
WordDeal wd1 = new WordDeal(text1);
List wf1 = wd1.getWordFreq();
String[] s1 = wd1.ListToArray(wf1);
}
除此之外,测试大文本数据:
String text1 = "";
String str[]={"word1","word2","file","你好","123file","file123","fil123"};
//测试大文本数据
for(int j=0;j<10000;j++)
{
for(int i=0;i<str.length;i++)
{
text1+=str[i]+" ";
}
}
WordDeal wd1 = new WordDeal(text1);
int wn1 = wd1.getWordCount();
assertEquals(40000, wn1);
大文本数据测试:
结果如下:

6.5 性能覆盖率

- 如何优化覆盖率?
1.尽量避免使用三目运算符,多IF条件判断,可以使用枚举+工厂类来规避,减少单元测试编写难度
2.减少不必要的判断:比如在new分配内存的失败,会抛出异常。此时可以在程序外层捕捉异常,或者静态分配内存/池。不论哪种方式,都不必要在每次new之后都做指针判空。
3.减少重复代码,相同逻辑如果散落在各处,对于提升覆盖率的明显会有更多的重复工作。
6.6 性能改进
在文件读入转化成字符串的函数ReadFile()中,用到了StringBuffer(也称字符缓冲区),StringBuffer类和String类最大区别在于它的它的内容和长度都是可以改变的。StringBuffer类似一个字符容器,当在其中添加或删除字符的时候,不会产生新的StringBuffer对象,所以性能方面有点改进。
7.异常处理说明
- 传参长度小于2的时候,强制退出
if(args.length != 2)
{
System.out.print("程序只接受两个参数");
return; //退出程序
}
- 输入文件如果不存在或是个目录,则提醒
if (!file.exists() || file.isDirectory())
{
System.out.println("请输入正确文件名!");
throw new FileNotFoundException();
}
- 其他异常用throws IOException抛出
8.心路历程与收获
这次项目让我接触并学习了git和github,版本控制其实对项目管理有很大的好处;也开始慢慢规范自己的代码书写,以前是比较不注重代码规范问题的;Personal Software Process (PSP, 个人开发流程,或称个体软件过程)也让我学着在开始编程前预估程序各模块的开发时间,重视开发的效率;编程过程中,通过查阅CSDN等资料用了之前不熟练的map和collection;还接触了一点Junit单元测试,以前测试只是手动测试;所以此次项目自己学了一点新的东西,觉得这次体验很棒。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号