文本判别技术总结
20180606毕设更新:在2号终于有惊无险地完成了毕业答辩之后,终于有空,总结一下毕设内容,并且补上一些修改及最终代码。再加上一些吐槽的内容~
1、系统补充及修改
在这里详细地介绍一下整个系统的流程吧。
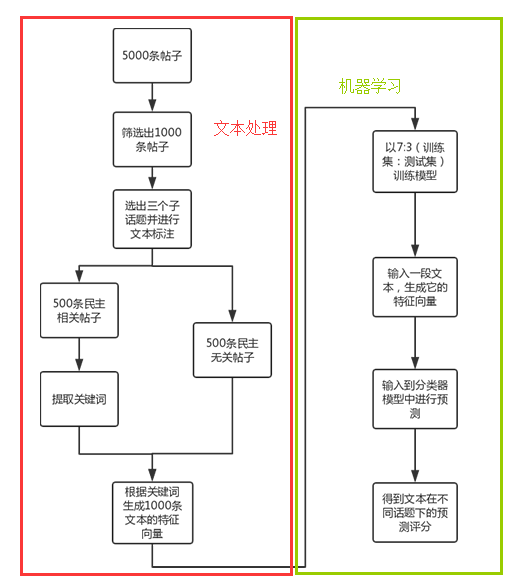
1.1 文本处理部分
1.1.1 文本标注
(1)挑选关键词
在此给定三个民主子话题——“民主制度”、“民主自由”和“民主监督”
(2)评分
给出相关度评分,1~5分,其中1为基本无关,5为非常相关。
| 基本无关 | 有点相关 | 基本相关 | 比较相关 | 非常相关 |
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 |
(3)标注
在这里我主要标注了505条,标注格式为:
| 文本 | 民主制度 | 民主自由 | 民主监督 |
|---|---|---|---|
| '首先这两个目标是我们追求的理念,并不意味着马上能实现或一定能完全达到;其次人人平等和共同富裕都是相对的,表明每个人都有自己的尊严、生存发展和被他人尊重的权利,共同富裕则强调社会贫富差距相对很小,社会整体处于富足的状态。最后人人平等是普遍认可的普世价值,共同富裕是社会稳定的重要基础,理应成为每个政府施政追求的目标。 | 1 | 3 | 1 |
1.1.2 提取关键词
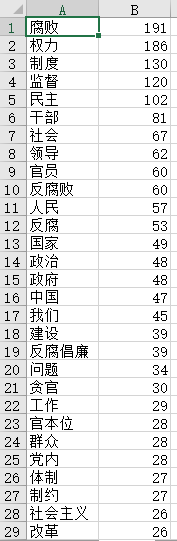
在这里,利用exckeyWords.py进行关键词抽取。
前面写的这三篇博客对代码有比较细致的讲解。
该文件需要输入"biao2.xls",该表格存储了民主相关文本的标注信息,中间产生t1.xls中间表格(为了去掉空格和空值)。
关键词抽取后得到若干关键词,并保存在sta.xls中。如图:
1.1.3 生成文本特征向量
(1)自动标注
我又从语料库中挑选出1000+条文本,删掉一些与民主特别相关的文本之后,所有文本直接标注1,1,1即与所有民主子话题无关。具体参考
非民主相关帖子处理代码未改动。
将与民主相关的标注文本与上述自动生成的标注文本合并在一起,便得到了1000+条的标注文本。
(2)获取误差测试集,机器学习数据集
挑选300条用来测试误差,其余的当作机器学习的输入数据集。由于一共有1090条文本,所以随机生成0~1089之间的数字,生成300个,但有可能多出来,所以需要将多的删掉,如果是少的话,就不处理。由于每次结果不太一样,所以尽量选择多选的情况。
Lr=[]
for i in range(350):
Lr.append(random.randint(0, 1090))
Lr=list(set(Lr))
Lr.sort()
Lrlen=len(Lr)
delta=abs(300-Lrlen)
#delta为误差测试集数量超过300时的差值
for i in range(delta):
j=-i
Lr.pop(j)
print(len(Lr))
Ll=list(range(0,1090))
#Ll中有的并且不在Lr中的数字放入di中,即需要机器学习的数据集
di=[v for v in Ll if v not in Lr]
print(len(di))
(3)向量生成
向量生成的详细过程参考
向量生成
,代码是"MLdata.py".其中输入文件sta.xls为关键词集合;输入文件FMbeifen.xls是标注文本;输出文件t2.xls是将向量以Excel表格存储;输出文件test.txt是存放全部向量的txt文本;输出文件test2.txt和test3.txt分别是存放误差测试集和数据集的向量.
1.2 机器学习部分
之前的三篇写得很清楚了
2、机器学习分类实例(sklearn)——SVM(修改)/Decision Tree/Naive Bayes,
主要代码为:
svm.py; nby.py; dt.py
svmPre.py; nbyPre.py; dtPre.py
另外为了方便演示,我整合了一些代码为Bless.py,是希望答辩演示的时候能不崩溃。主要功能便是输入一段文本,自动地解析为特征向量,并根据对应算法,进行预测分类。
演示部分(采用SVM):


2、答辩相关
真的恶心,答辩当天,我是第二个上去讲ppt的。由于忘记将论文给评审老师看,所以下面四个老师,都直勾勾地看着我,一直问我问题。按理说应该一个看论文,一个看论文材料,结果问辩环节四个人一起问我。。。而且刚开始老师都神采奕奕的,疯狂怼我,宝宝心里苦。

3、吐槽
终于将毕设、论文、答辩都搞定了,老师叫我开始准备申请专利了。。。。说实在的,我不太想申请啊,感觉没做什么创新,没做什么工作。。。但似乎在他眼中,万物皆可申请成专利。。。硬着头皮先写吧。。。
4、论文
附上ppt/论文链接:https://pan.baidu.com/s/1XEwj70gf24oHdYcFX_LPPA
5、附录(代码&各个表格文件)
5.1 excKeyWords
import jieba.analyse
from openpyxl import load_workbook
from openpyxl import Workbook
from collections import Counter
def isCha(s):
for c in s:
if not('\u4e00' <= c <= '\u9fa5'):
return False
return True
wr=load_workbook('biao2.xlsx')
sheet=wr.get_sheet_by_name('Sheet1')
r=sheet.max_row
ww=Workbook()
sheet2 =ww.active
sheet2.title="new"
alphbet=['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T']
n=1
k=1
for i in sheet["A"]:
k=0
#print(i.value,end=" ")
content=str(i.value)
keywords=jieba.analyse.extract_tags(content,topK=20)
#print(keywords,len(keywords))
if len(keywords) >0:
for m in keywords:
a=alphbet[k]
# print(a,n,m)
if isCha(m):
sheet2["%s%d" % (a,n)].value=m
else:
sheet2["%s%d" % (a,n)].value=0
k=k+1
for j in range(20):
if j>=k:
a=alphbet[k]
sheet2["%s%d" % (a,n)].value=0
k=k+1
n=n+1
ww.save('t1.xlsx')
######################################################
wr2=load_workbook('t1.xlsx')
cursheet=wr2.active
L=[]
for row in cursheet.rows:
for cell in row:
if cell.value!=0:
L.append(cell.value)
LC=Counter(L)
ww2=Workbook()
sheet3 =ww2.active
sheet3.title="statis"
c1=1
LC2=sorted(LC.items(),key=lambda d:d[1],reverse=True)
for k in LC2:
n=1
for v in k:
if n%2==1:
sheet3["A%d" % c1].value=v
n=n+1
else:
sheet3["B%d" % c1].value=v
c1=c1+1
ww2.save('sta.xlsx')
5.2 MLdata
import random
from openpyxl import load_workbook
from openpyxl import Workbook
import jieba.analyse
wr=load_workbook('sta.xlsx')
osheet=wr.active
orow=osheet.max_row
ww=Workbook()
asheet=ww.active
asheet.title="ml"
alphabet=[]
o='A'
for i in range(26):
alphabet.append(o)
p=ord(o)+1
o=chr(p)
#print(alphabet)
k=0
n=1
e=0
m=0
num=200
tempL=[]
testL=[]
tempc=0
for i in osheet["A"]:
if tempc<num:
tempL.append(i.value)
testL.append(i.value)
else:
break
tempc=tempc+1
tempL.append("民主制度")
tempL.append("言论自由")
tempL.append("民主监督")
num2=num+3
for i in tempL:
if k<=num2:
if k<26:
a=alphabet[k]
asheet["%s%d" % (a,n)].value=str(i)
else:
if m==26:
m=0
e=e+1
b=alphabet[e]
c=alphabet[m]
d=b+c
asheet["%s%d" % (d,n)].value=str(i)
m=m+1
else:
break
k=k+1
print(e,m)
if num<26:
O1=alphabet[num]
O2=alphabet[num+1]
O3=alphabet[num+2]
else:
O1=alphabet[e]+alphabet[m-3]
O2=alphabet[e]+alphabet[m-2]
O3=alphabet[e]+alphabet[m-1]
ww.save('t2.xlsx')
#存储关键词
#生成文本特征向量
wr2=load_workbook('FMbeifen.xlsx')
osheet2=wr2.active
print(osheet2.max_row)
L1=[]
for i in osheet2["A"]:
k=0
content=str(i.value)
keywords=jieba.analyse.extract_tags(content,topK=1000)
L1.append(keywords)
L1.pop(0)
#print(L1)
count=0
L3=[]
L2=[]
flag=False
#print(testL)
for i in L1:
L2=[]
for g in testL:
flag=False
for j in i:
if g==j:
flag=True
if flag:
L2.append(1)
else:
L2.append(0)
L3.append(L2)
#print(L3)
k=0
n=2
for j in L3:
e=0
m=0
for i in j:
if k<=num2:
# 前26个字母直接存
if k<26:
a=alphabet[k]
asheet["%s%d" % (a,n)].value=i
else:
if m==26:
m=0
e=e+1
b=alphabet[e]
c=alphabet[m]
d=b+c
asheet["%s%d" % (d,n)].value=i
m=m+1
k=k+1
n=n+1
k=0
print(n)
L5=[]
L5.append(O1)
L5.append(O2)
L5.append(O3)
L6=['B','C','D']
k=0
#L5=['GS', 'GT', 'GU']
#L6 是标注文件中的评分
for j in L5:
n=2
c=1
for i in osheet2[L6[k]]:
if c>1:
asheet["%s%d" % (j,n)].value=i.value
n=n+1
c=c+1
k=k+1
for j in L5:
n=2
for i in L3:
l=asheet["%s%d" % (j,n)].value
i.append(l)
n=n+1
ww.save('t2.xlsx')
file=open('test.txt','w')
for i in L3:
i = str(i).strip('[').strip(']')
file.write(i+'\n')
file.close()
Lr=[]
for i in range(350):
Lr.append(random.randint(0, 1090))
Lr=list(set(Lr))
Lr.sort()
Lrlen=len(Lr)
delta=abs(300-Lrlen)
for i in range(delta):
j=-i
Lr.pop(j)
Ll=list(range(0,1090))
di=[v for v in Ll if v not in Lr]
print(len(di),len(Ll),len(Lr))
#di训练集+测试集
#Lr用来测试误差的
file2=open('test2.txt','w')
for j in Lr:
vec=L3[j]
i = str(vec).strip('[').strip(']')
file2.write(i+'\n')
file2.close()
file3=open('test3.txt','w')
for j in di:
vec=L3[j]
i = str(vec).strip('[').strip(']')
file3.write(i+'\n')
file3.close()
5.3 SVM
import re
import sys
import numpy as np
from sklearn.svm import SVC
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
class TextArea(object):
def __init__(self):
self.buffer = []
def write(self, *args, **kwargs):
self.buffer.append(args)
def mf(L=[]):
for i in range(90):
s = re.findall("\d+(\.\d+)?",l)[i]
s='0'+s
s=float(s)
if i>=26 and i<=28 or i>=56 and i<=58 or i>=86 and i<=88:
L.append(s)
return L
with open("test.txt","r") as file:
result=[]
for line in file.readlines():
result.append(list(map(str,line.strip().split(','))))
vec = np.array(result)
x = vec[:,:-3]
y = vec[:,-3]
y2=vec[:,-2]
y3=vec[:,-1]
f = open("examout.txt","r")
newl =f.read()
newl=list(map(str,newl.strip().split(',')))
newv = np.array(newl)
new_test_x = newv[:]
###############################################################################
#模型训练
###############################################################################
# 模型1
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.2)
clf1 = SVC(kernel='linear',C=0.4)
clf1.fit(train_x,train_y)
pred_y = clf1.predict(test_x)
new_pred_y1 = clf1.predict(new_test_x.reshape(1,-1))
npy1=int(new_pred_y1[0])
###############################################################################
# 模型2
train_x2,test_x2,train_y2,test_y2 = train_test_split(x,y2,test_size=0.2)
clf2= SVC(kernel='linear',C=0.4)
clf2.fit(train_x2,train_y2)
pred_y2 = clf2.predict(test_x2)
new_pred_y2 = clf2.predict(new_test_x.reshape(1,-1))
npy2=int(new_pred_y2[0])
###############################################################################
# 模型3
train_x3,test_x3,train_y3,test_y3 = train_test_split(x,y3,test_size=0.2)
clf3= SVC(kernel='linear',C=0.4)
clf3.fit(train_x3,train_y3)
pred_y3 = clf3.predict(test_x3)
new_pred_y3 = clf3.predict(new_test_x.reshape(1,-1))
npy3=int(new_pred_y3[0])
###############################################################################
#输出处理
###############################################################################
print(classification_report(test_y,pred_y))
stdout = sys.stdout
sys.stdout = TextArea()
print(classification_report(test_y,pred_y))
print(classification_report(test_y2,pred_y2))
print(classification_report(test_y3,pred_y3))
text_area, sys.stdout = sys.stdout, stdout
# print to console
l=str(text_area.buffer)
L=[]
L=mf(L)
print(L)
fs1=[]
fs2=[]
fs3=[]
LL=range(9)
for i in LL[:9:3]:
fs1.append(L[i])
fs2.append(L[i+1])
fs3.append(L[i+2])
###############################################################################
#图形绘制
###############################################################################
import matplotlib.pyplot as plt
import numpy as np
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
def autolabel(rects):
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x()+rect.get_width()/1.-0.2, 1.03*height, '%s' % float(height))
x = np.arange(3)
data = [npy1, npy2, npy3]
labels = ['民主制度', '民主自由', '民主监督']
plt.ylim(ymax=5.5, ymin=0)
plt.ylabel("评分")
plt.title("预测")
plt.bar(x, data,alpha=0.9,tick_label=labels)
plt.show()
###############################################################################
total_width, n = 0.7, 3
x = np.arange(n)
width = total_width / n
x = x - (total_width - width) / 2
plt.ylim(ymax=1.3, ymin=0)
a=plt.bar(x, fs1,alpha=0.8, width=width, label='Precision')
b=plt.bar(x + width, fs2,alpha=0.8, width=width, label='Recall',tick_label = labels)
c=plt.bar(x + 2 * width, fs3, alpha=0.8,width=width, label='F1-score')
autolabel(a)
autolabel(b)
autolabel(c)
plt.legend()
plt.show()
5.4 svmPre
和svm类似
import numpy as np
from sklearn.svm import SVC
from sklearn.cross_validation import train_test_split
with open("test3.txt","r") as file:
result=[]
for line in file.readlines():
result.append(list(map(str,line.strip().split(','))))
vec = np.array(result)
x = vec[:,:-3]
y = vec[:,-3]
y2=vec[:,-2]
y3=vec[:,-1]
f = open("test2.txt","r")
newl=[]
for line in f.readlines():
newl.append(list(map(str,line.strip().split(','))))
newv = np.array(newl)
new_test_x = newv[:,:-3]
new_test_y1=newv[:,-3]
new_test_y2=newv[:,-2]
new_test_y3=newv[:,-1]
###############################################################################
#模型训练
###############################################################################
# 模型1
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.3)
clf1 = SVC(kernel='linear',C=0.4)
clf1.fit(train_x,train_y)
pred_y = clf1.predict(test_x)
new_pred_y1 = clf1.predict(new_test_x)
###############################################################################
# 模型2
train_x2,test_x2,train_y2,test_y2 = train_test_split(x,y2,test_size=0.2)
clf2= SVC(kernel='linear',C=0.4)
clf2.fit(train_x2,train_y2)
pred_y2 = clf2.predict(test_x2)
new_pred_y2 = clf2.predict(new_test_x)
###############################################################################
# 模型3
train_x3,test_x3,train_y3,test_y3 = train_test_split(x,y3,test_size=0.3)
clf3= SVC(kernel='linear',C=0.4)
clf3.fit(train_x3,train_y3)
pred_y3 = clf3.predict(test_x3)
new_pred_y3 = clf3.predict(new_test_x)
###############################################################################
#预测分析
testnum=298
count1=0
count2=0
count3=0
count4=0
count5=0
count6=0
for i in range(testnum):
py1=int(new_pred_y1[i])
py2=int(new_pred_y2[i])
py3=int(new_pred_y3[i])
cy1=int(new_test_y1[i])
cy2=int(new_test_y2[i])
cy3=int(new_test_y3[i])
if abs(py1-cy1)<2:
count1=count1+1
if abs(py2-cy2)<2:
count2=count2+1
if abs(py3-cy3)<2:
count3=count3+1
if py1==cy1:
count4=count4+1
if py2==cy2:
count5=count5+1
if py3==cy3:
count6=count6+1
#
p1=round(count1/testnum,2)
p2=round(count2/testnum,2)
p3=round(count3/testnum,2)
p4=round(count4/testnum,2)
p5=round(count5/testnum,2)
p6=round(count6/testnum,2)
##############################################################################
#图形绘制
##############################################################################
import matplotlib.pyplot as plt
import numpy as np
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
def autolabel(rects):
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x()+rect.get_width()/2.-0.1, 1.03*height, '%s' % float(height))
x = np.arange(3)
data = [p1,p2,p3]
data2=[p4,p5,p6]
labels = ['民主制度', '民主自由', '民主监督']
plt.ylim(ymax=1.1, ymin=0)
plt.ylabel("准确率")
plt.title("预测准确率")
a=plt.bar(x, data,alpha=1.0,tick_label=labels,color=['darkgray','tan','indianred'])
autolabel(a)
plt.show()
plt.ylim(ymax=1.1, ymin=0)
b=plt.bar(x, data2,alpha=1.0,tick_label=labels,color=['darkgray','tan','indianred'])
autolabel(b)
plt.show()
5.5 Bless
from openpyxl import load_workbook
from openpyxl import Workbook
import jieba.analyse
import numpy as np
from sklearn.svm import SVC
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
wr=load_workbook('sta.xlsx')
osheet=wr.active
testL=[]
num=200
tempc=0
for i in osheet["A"]:
if tempc<num:
testL.append(i.value)
else:
break
tempc=tempc+1
import easygui as g
content=g.textbox(msg='输入一段文本:', title='输入文本 ')
keywords=jieba.analyse.extract_tags(content,topK=1000)
L3=[]
L2=[]
flag=False
#生成文本向量
for g in testL:
flag=False
for i in keywords:
if g==i:
flag=True
break
if flag:
L2.append(1)
else:
L2.append(0)
#模型数据训练导入
with open("test.txt","r") as file:
result=[]
for line in file.readlines():
result.append(list(map(str,line.strip().split(','))))
vec = np.array(result)
x = vec[:,:-3]
y = vec[:,-3]
y2=vec[:,-2]
y3=vec[:,-1]
newv = np.array(L2)
new_test_x = newv[:]
###############################################################################
#模型训练
##############################################################################
# 模型1
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.2)
clf1 = SVC(kernel='linear',C=0.4)
clf1.fit(train_x,train_y)
pred_y = clf1.predict(test_x)
new_pred_y1 = clf1.predict(new_test_x.reshape(1,-1))
npy1=int(new_pred_y1[0])
##############################################################################
# 模型2
train_x2,test_x2,train_y2,test_y2 = train_test_split(x,y2,test_size=0.2)
clf2= SVC(kernel='linear',C=0.4)
clf2.fit(train_x2,train_y2)
pred_y2 = clf2.predict(test_x2)
new_pred_y2 = clf2.predict(new_test_x.reshape(1,-1))
npy2=int(new_pred_y2[0])
#############################################################################
# 模型3
train_x3,test_x3,train_y3,test_y3 = train_test_split(x,y3,test_size=0.2)
clf3= SVC(kernel='linear',C=0.4)
clf3.fit(train_x3,train_y3)
pred_y3 = clf3.predict(test_x3)
new_pred_y3 = clf3.predict(new_test_x.reshape(1,-1))
npy3=int(new_pred_y3[0])
##############################################################################
#输出处理
###############################################################################
import easygui as gg
if len(content)>0:
msg = gg.msgbox("民主话题预测评分 \n民主制度:%d 民主自由:%d 民主监督:%d " %(npy1,npy2,npy3))
else:
msg = gg.msgbox("请输入内容!")
朴素贝叶斯和决策树与svm方法类似,不再赘述

 浙公网安备 33010602011771号
浙公网安备 33010602011771号