第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 实现具有文本查重功能的程序,熟悉PSP表格 |
| 作业Github地址 | https://github.com/c0nta1n/3118005359 |
-
题目:论文查重
- 题目要求:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
- 题目要求:
-
查阅资料
经查阅百度可知用python实现较为简单,实现思维导图如下:
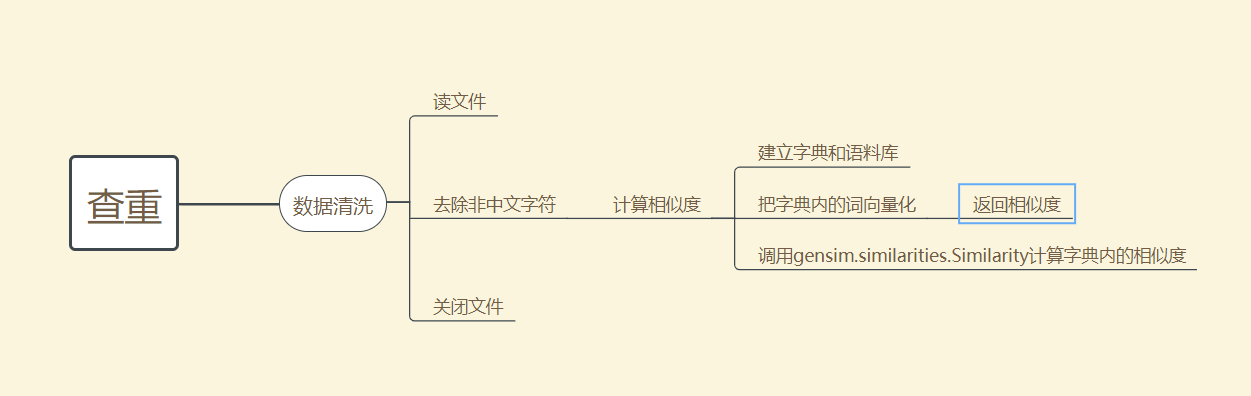
-
模块接口的设计与实现过程
sentenceclean()函数:读文件,jieba分词后,去除非中文字符。(独到之处:由于文档中过多html标签,且因查重的是中文文献,
特此用正则表达式把非中文字符全部去除)
def sentenceclean(path):
str = ''
f = open(path, 'r', encoding='UTF-8')
line = f.readline()
while line:
str = str + line
line = f.readline()
'''jieba中文分词'''
sentence1 = jieba.lcut(str)
'''由于是中文文本的查重,把除中文外的符号全部清除'''
d = "[\u4e00-\u9fa5]+"
sentence2 = []
for i in sentence1:
a = re.findall(d, i)
sentence2 += a
f.close()
return sentence2
参考大佬们的思路并阅读gensim官方文档的翻译后,写出calc_similarity()函数:
将文本转化为稀疏向量,调用gensim.similarities.Similarity计算出相似度。
(不去除停用词,不使用tfidf模型。主要是实现最简单的查重)
def calc_similarity(str1, str2):
texts = [str1, str2]
'''建立字典'''
dictionary = gensim.corpora.Dictionary(texts)
'''使用doc2bow制作语料库.
语料库是一组向量,向量中的元素是一个二元组(编号、频次数),对应分词后的文档中的每一个词。'''
corpus = [dictionary.doc2bow(text) for text in texts]
'''similarities.MatrixSimilarity类仅仅适合能将所有的向量都在内存中的情况。
例如,如果一个百万文档级的语料库使用该类,可能需要2G内存与256维LSI空间。
如果没有足够的内存,你可以使用similarities.Similarity类。
该类的操作只需要固定大小的内存,因为他将索引切分为多个文件(称为碎片)存储到硬盘上了。
它实际上使用了similarities.MatrixSimilarity和similarities.SparseMatrixSimilarity两个类。
因此它也是比较快的,虽然看起来更加复杂了。
similarity用于计算相似度,返回的是一组列表'''
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
'''计算text1的向量'''
test_corpus_1 = dictionary.doc2bow(str1)
'''计算测试文档的相似度'''
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
-
实现结果(测试文件是第一个文件与第三个文件)
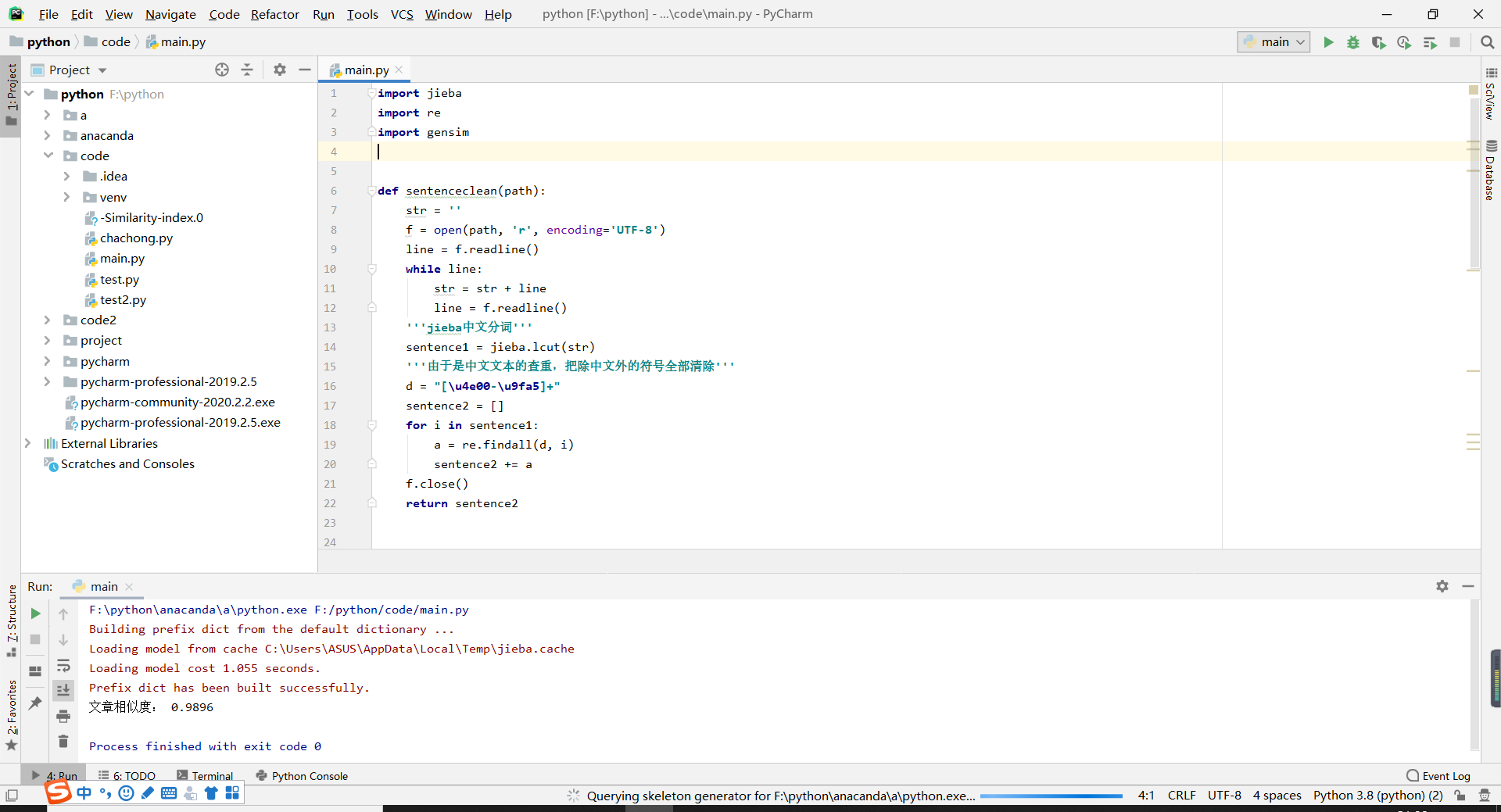
-
单元测试
-
性能测试:
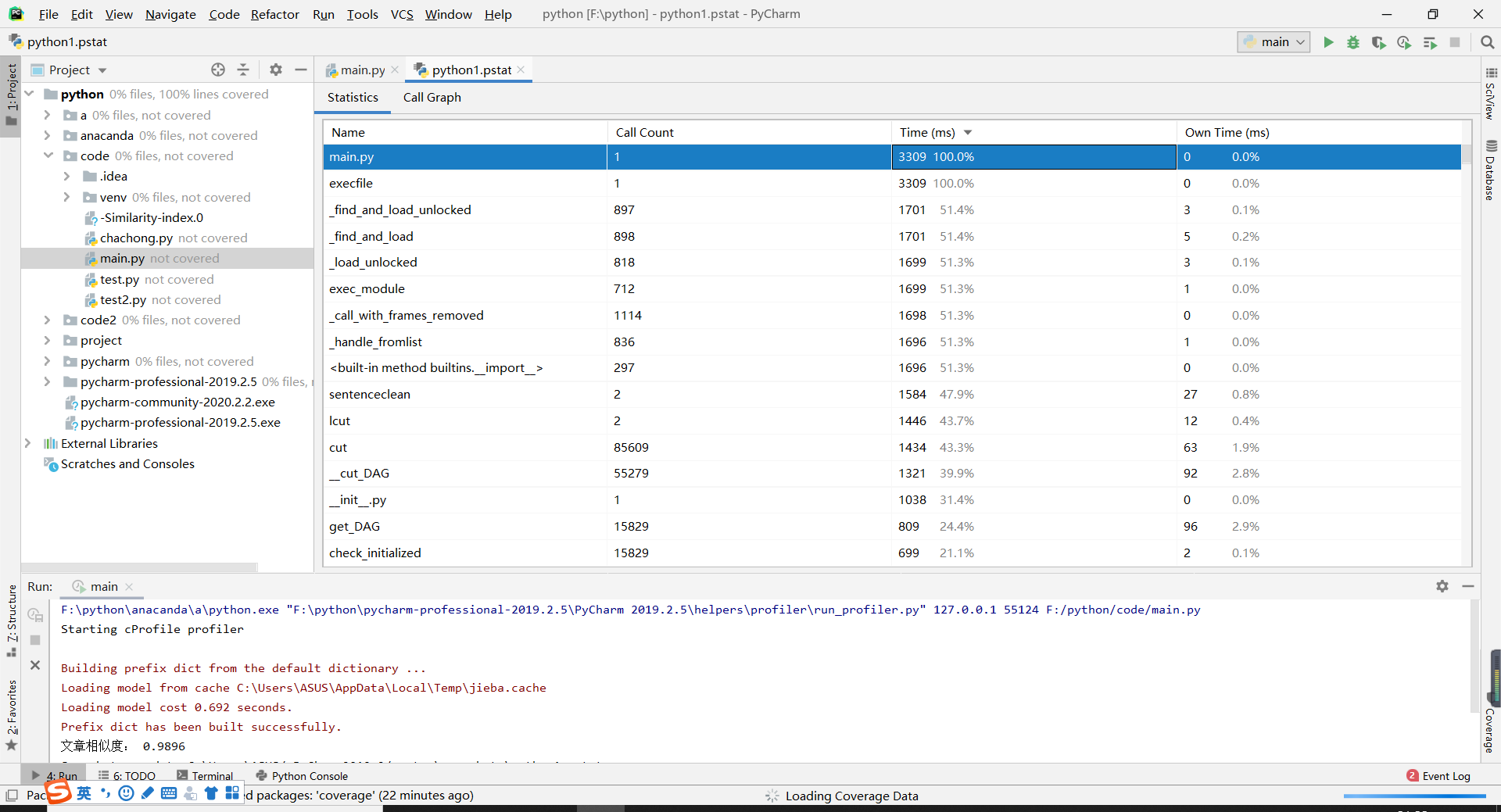
-
性能改进:从上图可知,用jieba分词的函数,所以会稍微慢一些。文本预处理和特征向量计算模块耗费时间比较多。
下一步可以自己用函数式编程方式改进。 -
代码覆盖率:
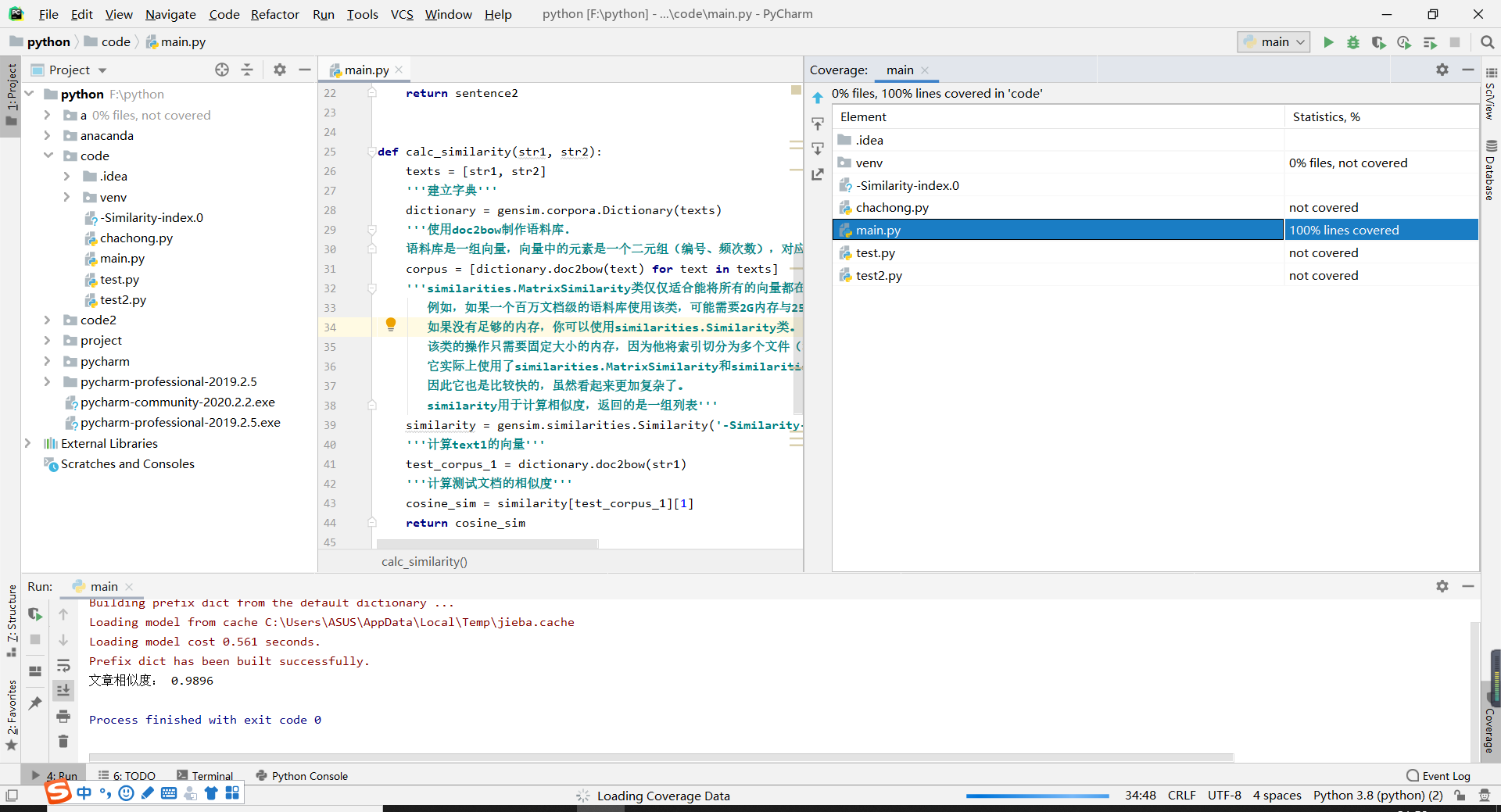
-
命令行参数输入输出:
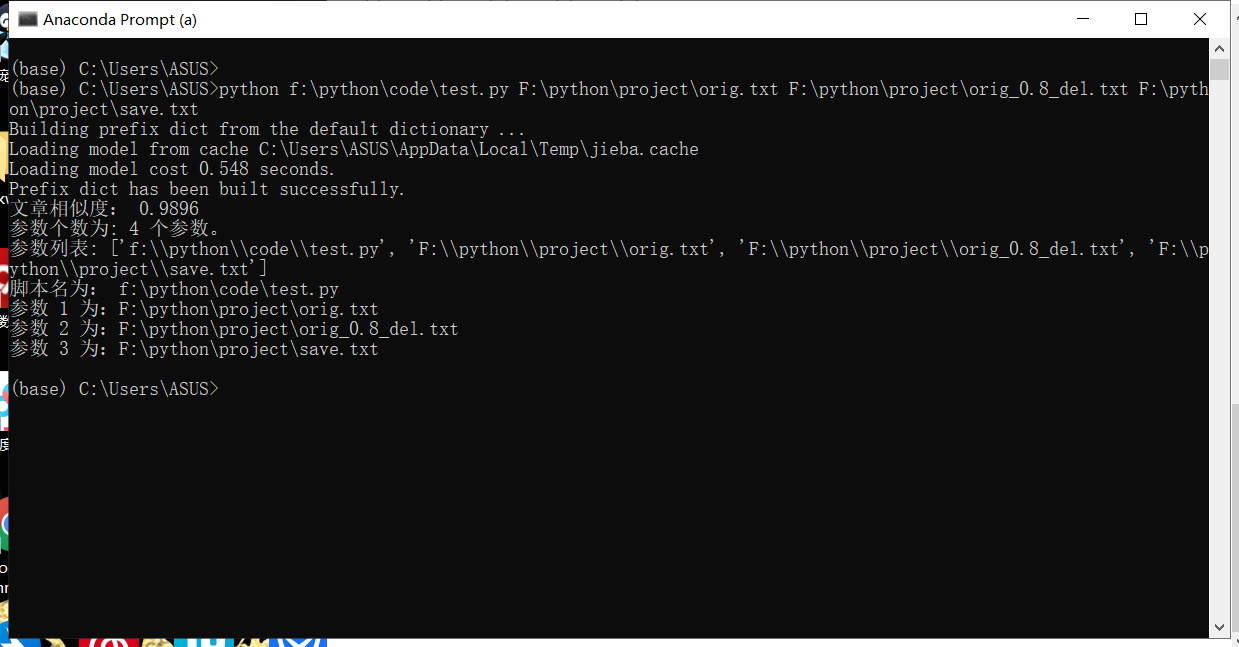
-
-
保存文件
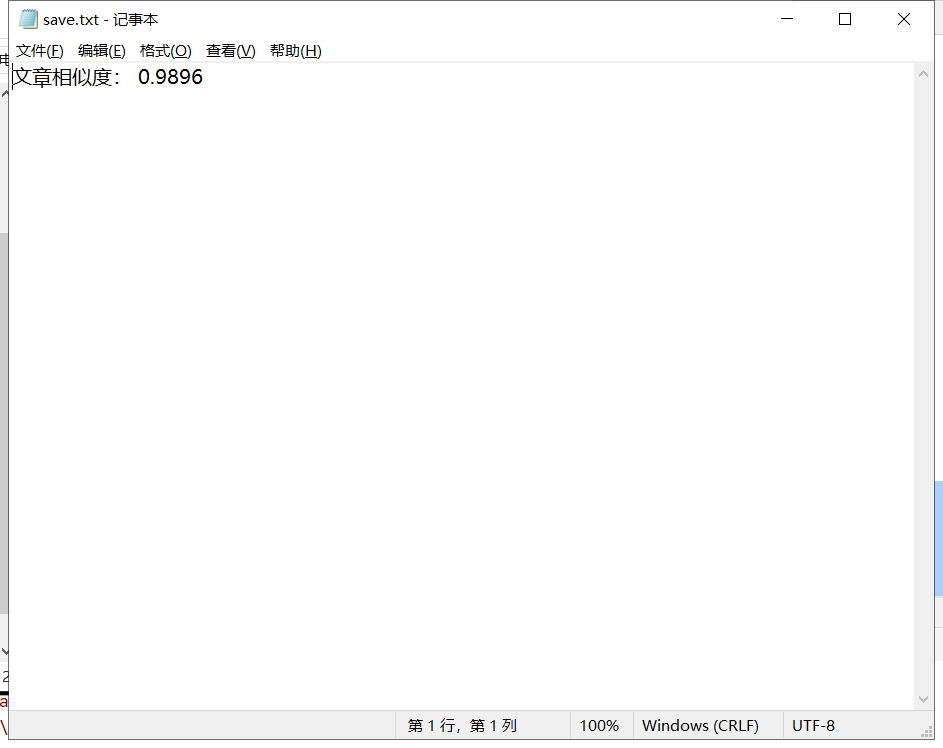
-
异常处理
- 写了一个空文本判断是否异常的模块,曾经因为str文本突然变为空了,所以运行失败
#空文本判断异常
if len(str1) == 0:
print("原始文本为空")
raise
elif len(str2) == 0:
print("相似文本为空")
raise
-
p2p表格
p2p表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 35 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 120 | 150 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 15 | 15 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 40 | 45 |
| · Coding | · 具体编码 | 30 | 40 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| Reporting | 报告 | 30 | 30 |
| · Test Repor | · 测试报告 | 15 | 15 |
| · Size Measurement | · 计算工作量 | 15 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 8 | 10 |
| · 合计 | 453 | 530 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号