
segment anything
What is the structure of the model?
- A ViT-H image encoder that runs once per image and outputs an image embedding
- A prompt encoder that embeds input prompts such as clicks or boxes
- A lightweight transformer based mask decoder that predicts object masks from the image embedding and prompt embeddings
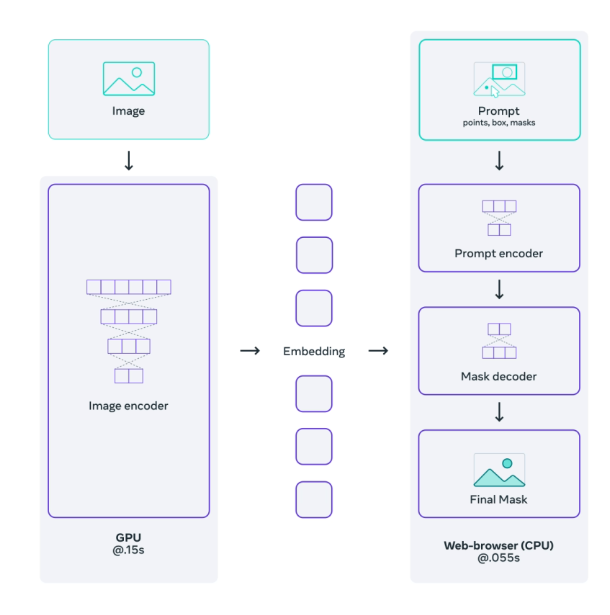
How big is the model?
- The image encoder has 632M parameters.
- The prompt encoder and mask decoder have 4M parameters.
How long does inference take?
- The image encoder takes ~0.15 seconds on an NVIDIA A100 GPU.
- The prompt encoder and mask decoder take ~50ms on CPU in the browser using multithreaded SIMD execution.
How long does it take to train the model?
- The model was trained for 3-5 days on 256 A100 GPUs.
posted on 2023-04-06 22:51 MissSimple 阅读(298) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号