
接口自动化数据文件与脚本分离
注意:只能在方法里边写东西
1、封装地址
用pytest和request写完脚本之后,就可以着手考虑优化的问题了,首先就是地址的问题,每个地址都有一个共有的ip地址,就很麻烦
1.1、通过变量相加的方式
可以从以下两个方面来解决url的问题,可以新建一个py文件,把变量放进去,就像token值一样,然后把HOST和url相加就可以得到地址
HOST = "http://118.24.105.78:2333"
使用时先导入变量:from utils.common import HOST
u = HOST+"url地址"
但是使用这种添加变量的方式在每次使用的时候都要去加一下,就很麻烦,使用第二种方式就显得容易得多
1.2、通过封装方法
第二种方法,更为普遍,可以封装一个方法
common.py里封装的方法为:
HOST = "http://118.24.105.78:2333" def get_url(url): """ 获取完整的接口地址 """ return HOST + url
使用:在使用时倒入即可:
注意这是两个文件夹下边的文件的倒入,要使用万精油环境变量的方式倒入:
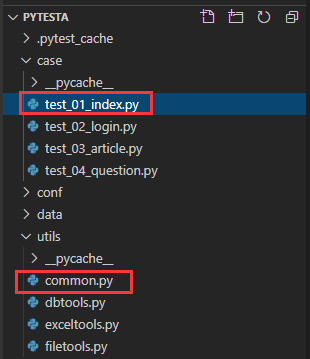
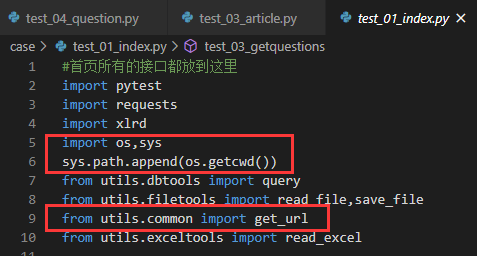
在写case的时候,u = get_url("接口文档上的地址")

2、数据文件与脚本分离
接下来就是数据文件的问题了,之前接口上所有的数据都写到了代码里,但是这样的话就导致了代码的耦合性太高,如果数据文件和脚本分离后,接口信息变动,就不用去修改对应的代码,只需要修改数据文件即可
一般存放数据文件都是存在excel表格中,或者是存放在MySQL数据表中,这里使用excel存放
2.1、建立excel文档
首先新建一个excel文档,这个文档里要放入于接口相关的信息:编号、名称、接口地址、参数、请求头、HTTP状态码、结果码

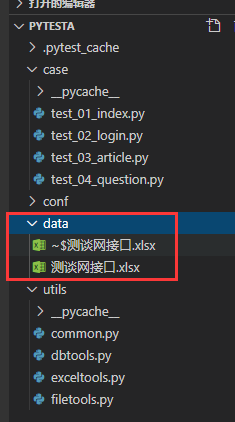
2.2、建立分层data,导入数据文件
先建立一个data文件夹,将刚才写的excel放入data文件夹中
2.3、读取excel中的数据

2.3.1、安装xlrd
读取excel,会用到python的一个第三方包:xlrd,这是python专门用来读取excel 的一个包
要想使用这个包,首先就是要安装它,管理员方式打开cmd,输入命令:pip install xlrd(这个一般来说都是要加-i参数的,但是这个可能比较小吧,没加也很快下载好了)
2.3.2、封装方法读取excel
接下里就是去封装一个方法来读取excel
① 先再utils里新建一个exceltools.py文件
② 导入xlrd,封装方法
""" 读取excel """ import xlrd def read_excel(excel_path, sheet_name, skip_first=True): """ 方法:python读取excel 参数: - excel_path:excel的路径 - sheet_name:表格名字 - skip_first: 是否跳过首行,True:跳过;False:不跳过,默认值是跳过 返回值:[[1, "xxx接口成功", "/login"...], []] """ results = [] datas = xlrd.open_workbook(excel_path) #就相当于在打开excel table = datas.sheet_by_name(sheet_name) #读取excel中的每一个sheet if skip_first == True: start_row = 1 else: start_row = 0 # 循环读取每一行数据 for row in range(start_row, table.nrows): results.append(table.row_values(row)) return results #测试 if __name__ == "__main__": a = read_excel("./data/测谈网接口.xlsx", "问题详情页面") print(a)
只用在封装方法这里import xlrd就行了,别的地方可以不用导入xlrd
2.3.3、使用封装好的读取excel的方法
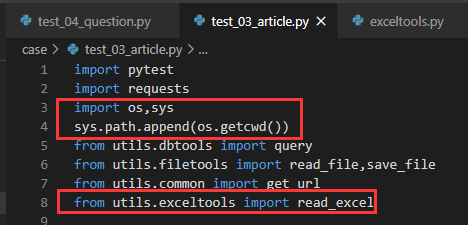
① 使用前先导入刚才封装好的方法
这里由于是不同文件夹下的不同文件的导入,还是得使用万精油方式:
②在py文件方法外边先读取出全部数据
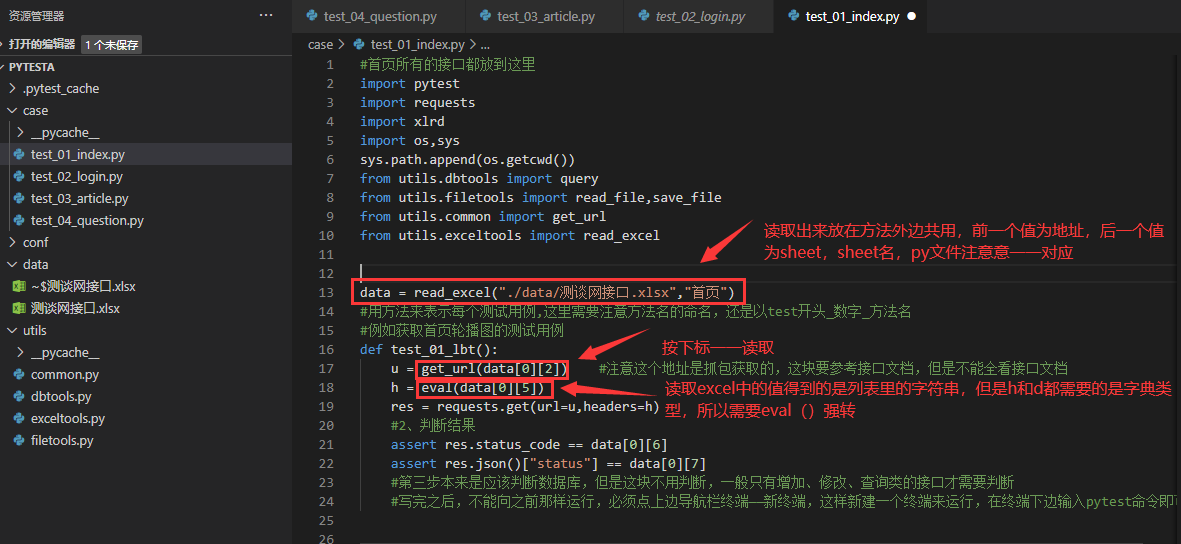
使用时还需要在方法外边将excel读取出来(共用嘛,所以需要在方法外边)
他读取出来之后的返回值是放在一个大的列表中(每一个sheet放在一个大的列表里),然后大的列表里有无数个小的列表,excel中有几行数据就有几个小的列表,这里就通过下标来取值来读出了
③ 按下标一一取值读取
边分离可以边执行,看是否会报错
由于header和请求数据python代码需要的是字典类型,但是读取excel中读取出来的是字符串类型,这里就涉及到了数据类型的转换,用eval()进行强转
涉及到token值的地方,python代码中用了read_file()来读取token值,在写excel数据文件的时候,直接将这个方法原封不动的搬过去就行,到时候再用eval()方法强转,会自动把token值获取到,这一点是eval()方法的强大之处之一
3、接口自动化测试用例的编写
就是把普通的接口测试用例转换成了python代码而已
写接口自动化测试用例的时候要注意以下几点:
- 场景一般都只考虑正向场景,因为一般来讲,都是先接口测试,然后再功能测试,然后功能稳定之后才是自动化测试,所以,在这之前异常的场景就已经在解耦测试中测试到了的
- 如果时间充足的情况下,可以考虑将异常场景也加入(比如参数异常,参数传入的数据异常等等)
- 添加一个用例,会涉及到数据文件的添加以及测试方法中脚本文件的添加等等
3、测试报告
allure:第三方专门的网页测试报告
1、使用allure需要有Java环境
2、安装allure-commandline工具,并配置环境变量(将安装路径下的bin目录添加到path中)
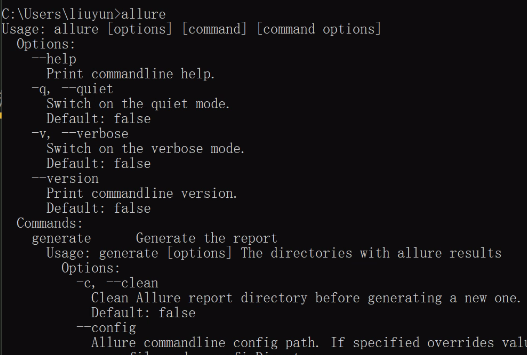
3、验证环境变量:新打开一个cmd,输入allure,如果没有出错,就没问题,如下图所示
4、安装allure-pytest第三方包,以管理员身份打开cmd:pip3 install allure-pytest -i https://pypi.tuna.tsinghua.edu.cn/simple
5、以管理员身份重启VScode
6、运行(这里就不是只输入pytest了):输入命令pytest --alluredir=result,这时会在目录里边自动生成一个report文件夹,文件夹下边就保存着每一个case 的结果
7、把result结果文件编译成测试报告,运行命令:allure generate result -o report --clean
8、打开result里边的测试报告,输入命令:allure open -h 127.0.0.1 -p 10086 report
不出意外的话会自动弹出一个网站(默认是英文的,左下角可以改成中文的),如果没有弹出,就自己手动复制网址去打开就行
如果想退出,就在VScode里边Ctrl+S就行,但是退出后测试报告就失效了,所以一定要最后再去做这一步
注:除了第三步,第四步在cmd里,别的命令都是在VScode里边执行的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号