
python语法
python语法考点
格式控制输出(选其一)
%
- 常用的格式化控制符
- %d:整数
- %s:字符串
- %f:浮点数
print("name:%5s weight:%5.2f."%("Alex",1.83))
#5表示占位符,2表示小数点后几位
format语句
- 占位符{}
- 格式限定符:,填充与对齐(^、<、>分别是居中、左对齐、右对齐,后面带宽度)
print("{:>8}{:>8}{:>8}".format(a,b,c))
- 精度与类型
print("{:8.2f}".format(5.796))
# 8表示字符宽度,2表示保留2位小数(四舍五入原则)
- 其它类型(b、d、o、x分别是二进制、十进制、八进制、十六进制)
print("二进制:{:b}".format(23))
print("八进制:{:o}".format(23))
print("十进制:{:d}".format(23))
print("十六进制:{:x}".format(23))
- 逗号作为金额的千位分隔符
print("{:,}".format(105922236))
Math库里的内置函数
- exp(x):返回e的x次方
- log:返回x的自然对数
- log10(x):返回x的10次方对数
- sqrt(x):返回x的平方根 ***
- pow(x,y):返回x的y次方根
- pi:返回圆周率Π的近似值
- e:返回自然对数的底数e的近似值
- ceil:向上取整 ***
- floor:向下取整 ***
- modf:返回输入参数的小数部分和整数部分
- fabs:返回输入参数的绝对值 ***
- factorial:计算输入参数的阶乘 ***
- degrees:将弧度转化为角度
- radians:将角度转化为弧度
- fmod(x,y):返回浮点数x和y的余数,相当于python中的%
- gcd(x,y):返回两个整数的最大公约数
- lcm(x,y):返回两个整数的最小公倍数
单行多个数据的输出
a,b = map(int,input().split())
多行输入存储
都为同一类型时
1、例题:
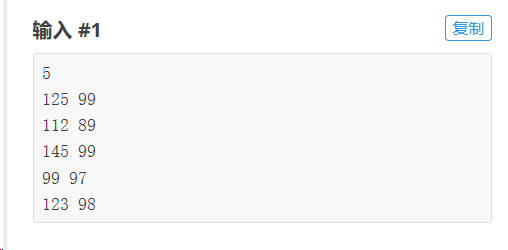
2、解法:
n = int(input())
li = [[i for i in map(int,input().split())] for j in range(n)] # 内层数组遍历一行数据,使用map,返回一个整数;第二层数组通过循环n次,遍历完n行数组,每行都使用内层数组的方法
print(li)
# 结果为:[[125, 99], [112, 89], [145, 99], [99, 97], [123, 98]]
为不同类型时
1、例题:
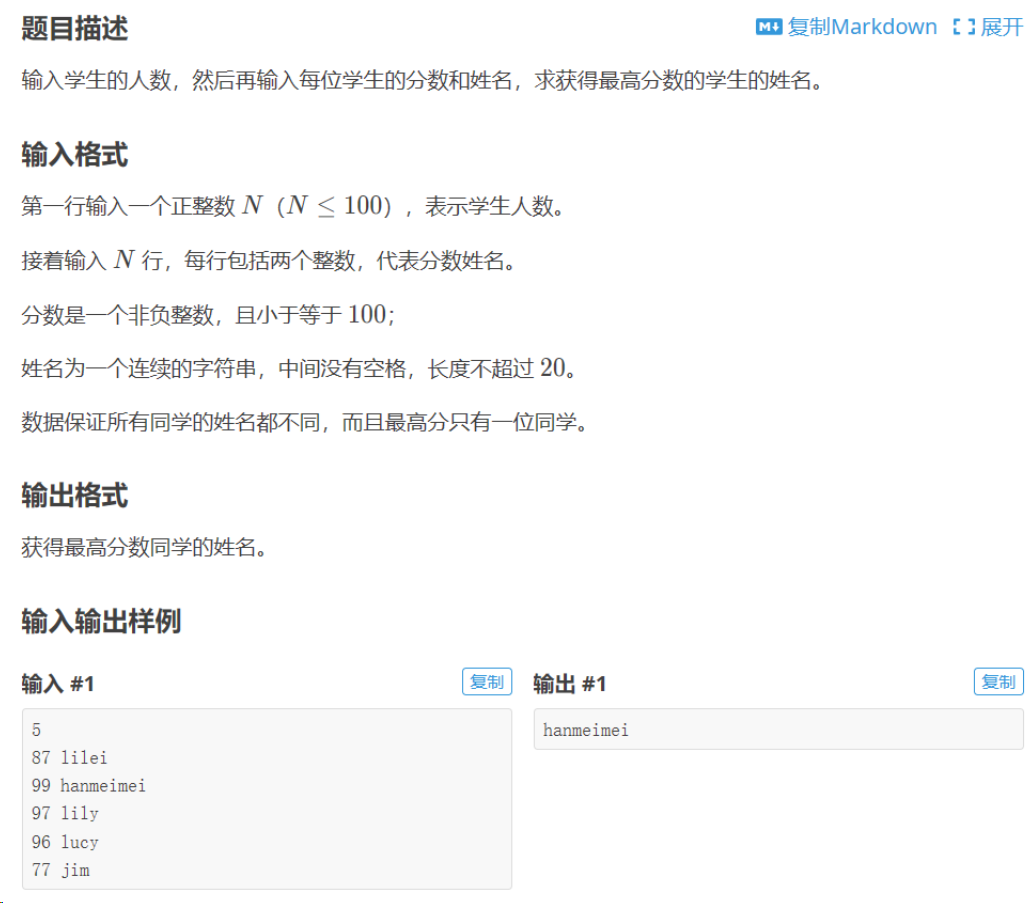
2、解法:
n = int(input())
li = [input().split() for _ in range(n)]
print(li)
# 输出为:[['87', 'lilei'], ['99', 'hanmeimei'], ['97', 'lily'], ['96', 'lucy'], ['77', 'jim']]
li = sorted(li, key=lambda x:x[0], reverse=True)
print(li[0][1])
Input与split搭配
# 将You want someone to help you转化为['You', 'want', 'someone', 'to', 'help', 'you']形式
s = input().split()
字符与ASCII的转换
-
ord():将字符转换为ASCII码
-
chr():将ASCII码转换为对应的字符
例题:
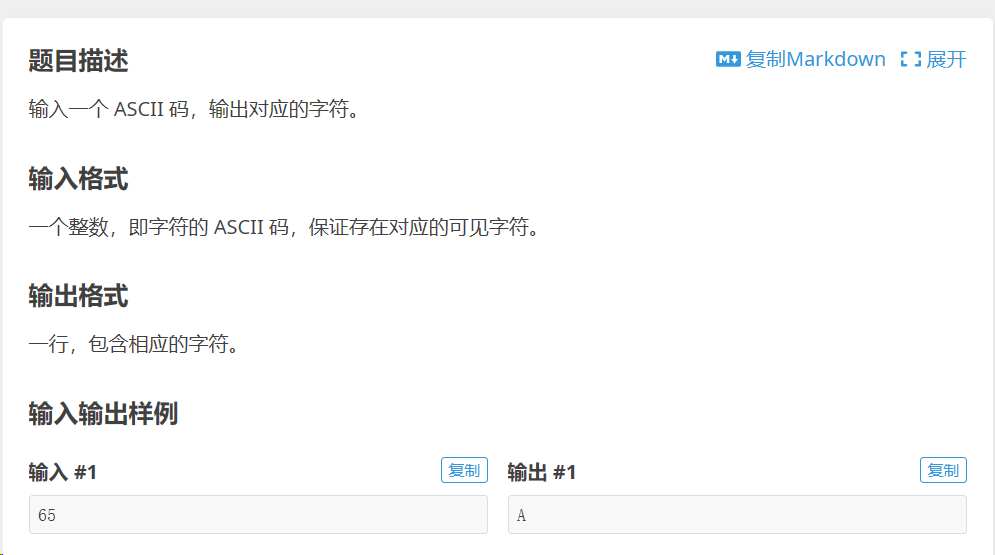
解答:
n = eval(input())
print(chr(n)) # 直接对chr()进行转换
获取正整数的最大范围
import sys
Maxsize = sys.maxsize
列表的调转
reverse():在列表内调转,不用重新赋值
li = [5,4,3,2,1]
li.reverse()
print(li)
# 结果为[1,2,3,4,5]
正则表达式
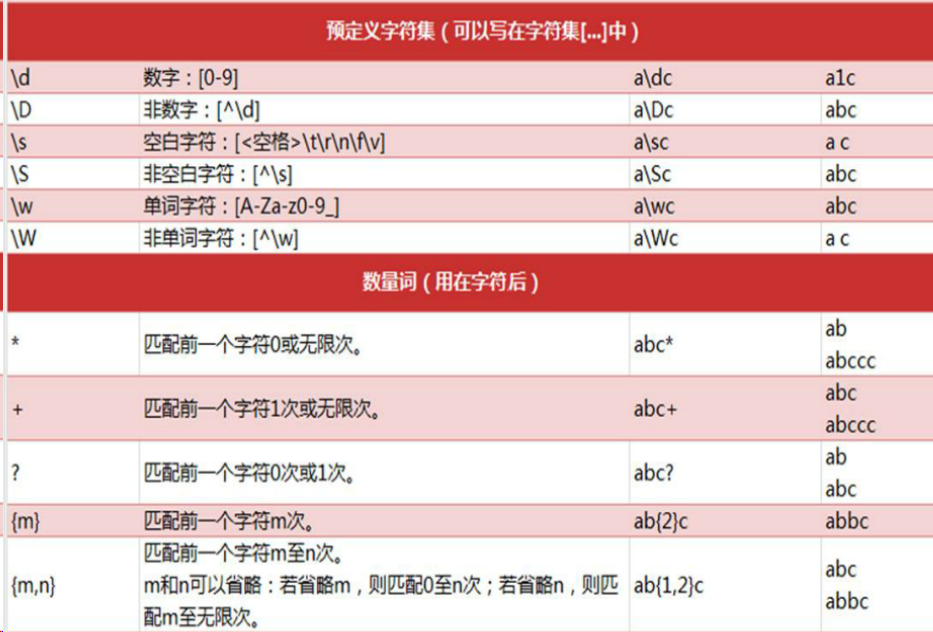
元字符
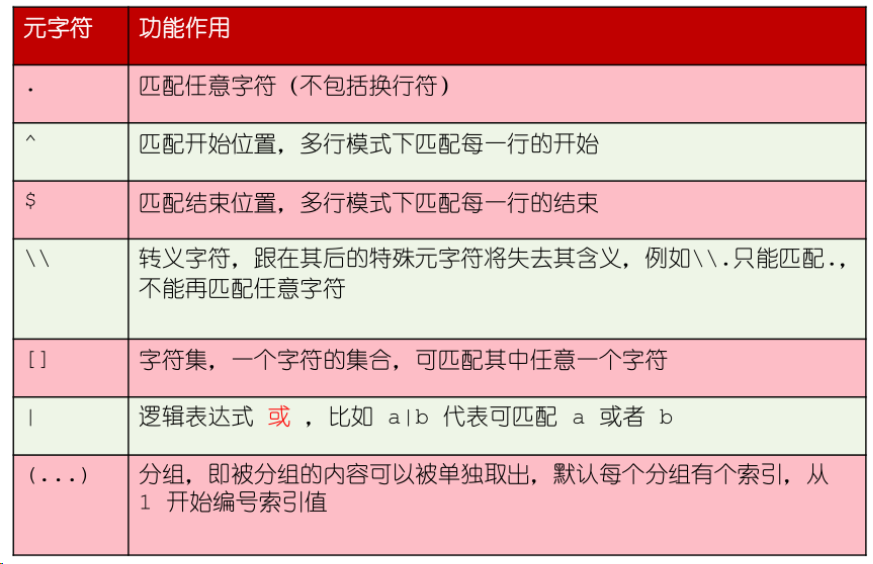
预定义字符集与数量词
re模块及其函数的运用
步骤
-
将正则表达式的字符串编译为Pattern实例
import re pattern = re.compile("") -
使用Pattern实例处理文本并获得匹配结果
re模块常用的函数:
![image]()
例题
例题1

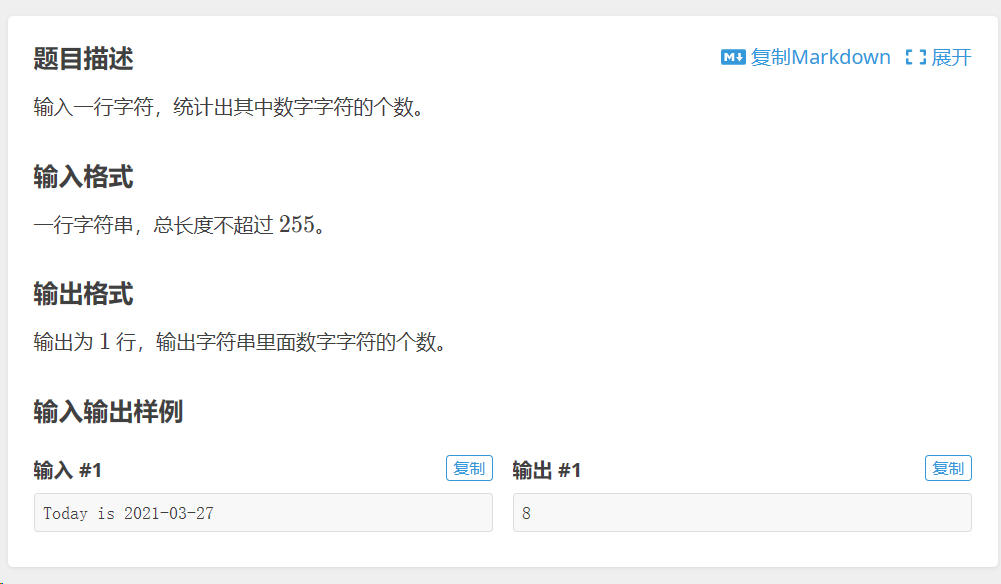
解答1:
str1 = input().split()
count = 0
import re
pattern = re.compile(r"\d")
for i in str1:
li = re.findall(pattern,i)
count += len(li)
print(count)
例题2:
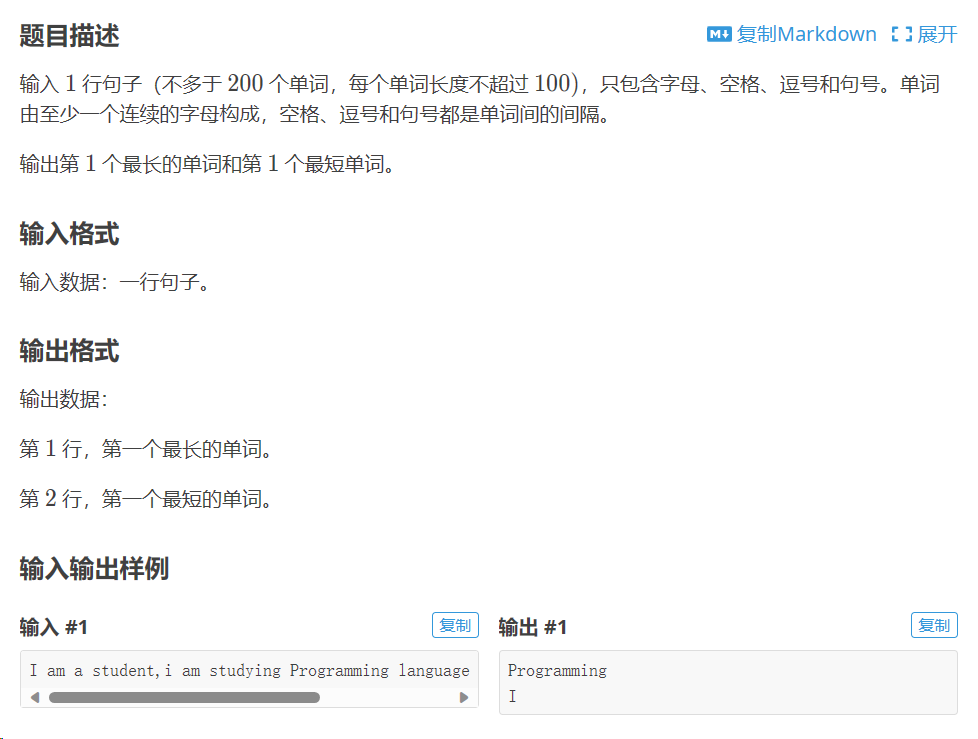
解答2:
import re
pattern = re.compile("[ ,.]")
words = re.split(pattern,input()) # 使用正则表达式对字符串进行分割
word = [i for i in words if i != ""] # 运用列表推导式对正则表达式分割符遗留的空字符串进行处理
word_num = [len(j) for j in word]
max_num = max(word_num)
min_num = min(word_num)
for i in word:
if len(i) == max_num:
print(i)
break
for j in word:
if len(j) == min_num:
print(j)
break
字符串
字符串的比较
字符串的比较是通过字符串字典序列一步步进行比较的
a = "1234"
b = "23"
print(a<b)
# 结果为True
lower和upper的用法
lower和upper只会把字符串中的每个字母转化为小写和大写形式,不会改变原字符串,需额外定义一个变量,输出结果为字符串形式
- 例题
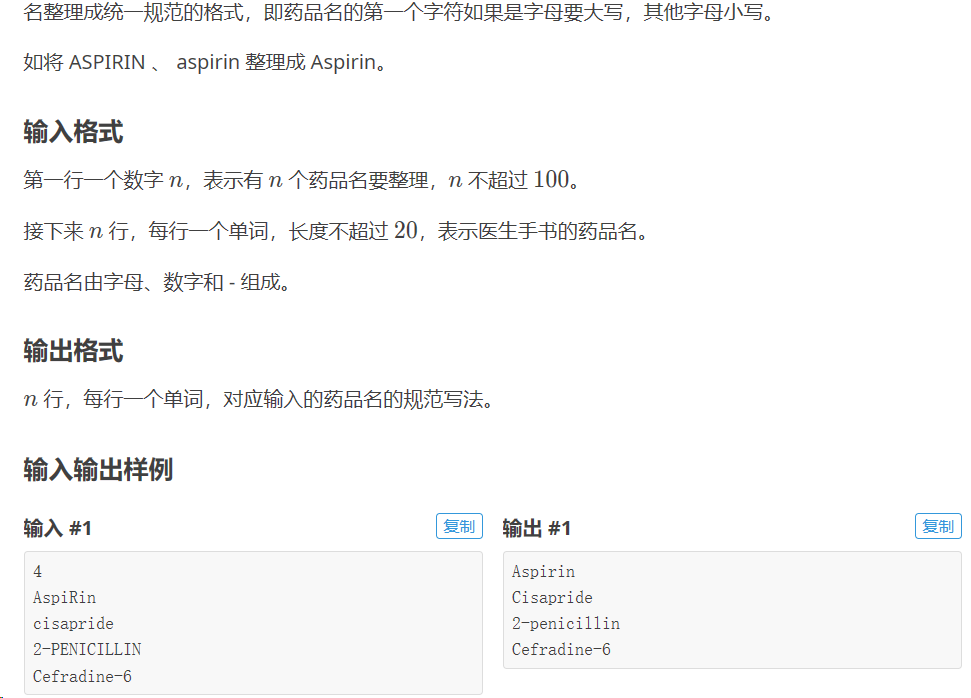
- 代码实现
n = int(input())
li = [input() for _ in range(n)]
for i in li:
print(i[0].upper()+i[1:len(i)+1].lower())
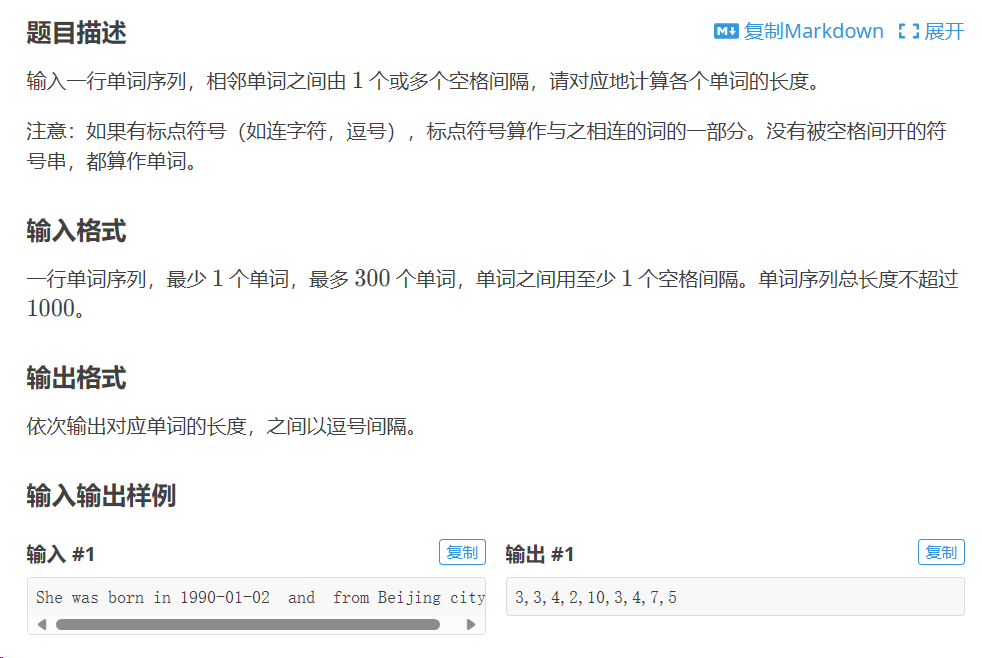
连接方法join的用法
将可迭代对象(该迭代对象的元素必须为字符串形式)通过规定的形式进行连接,最后生成一个字符串
-
例子
![image]()
-
代码实现
li = input().split() length = [] for i in li: length.append(str(len(i))) print(",".join(length))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号