

正则表达式
用于检测、测试字符串规则的表达式.
经常用于检测字符串是否符合特定的规则,在网站上经常用于检测用户输入数据是否符合规范:
- 检测 用户名 是否为 8~10 数字 英文(大小写)
- 检测 电话号码是否符合规则
- 检测 邮箱地址是否符合规则等
正则HelloWorld
最简单的正则表达式:"HelloWorld" 表示
-
一共有10个字符
-
出现的顺序必须是 HelloWorld
-
Java 提供了正则API, 用于检测一个字符串是否符合,正则规则
- boolean matchs(正则表达式) 检测当前字符串是否符合正则规则
正则规则 rule = "HelloWorld"
字符串: s1 = "HelloKitty";
字符串: s2 = "HelloWorld";
// s1 s2 中那个字符串符合 rule 约定的规则?
boolean b1 = s1.matches(rule); //false
boolean b2 = s2.matches(rule); //true
package string;
public class RegDemo05 {
public static void main(String[] args) {
/*
* 测试正则表达式
*/
//定义正则表达式:最简单的,要求相同
String rule = "HelloWorld";
//定义被检测的字符串
String s1 = "HelloKitty";
String s2 = "HelloWorld";
//检测 s1 是否符合规则
boolean b1 = s1.matches(rule);
//检测 s2 是否符合规则
boolean b2 = s2.matches(rule);
System.out.println(b1);
System.out.println(b2);
}
}
字符集
匹配一个有效字符范围,其中[]内的字符都是可以出现的,但是只能出现某一个
语法:
[123456]
意义:
- 匹配一个字符
- 其有效范围: 1 2 3 4 5 6 中的某一个
正则规则例子:
Hello[123456]
- 匹配6个字符
- 前5个必须是Hello
- 第6个字符,必须 1 2 3 4 5 6 中的一个
如, 可以匹配的字符串:
- "Hello1"
- "Hello2"
- "Hello3"
- ...
- "Hello6"
- "Hello7" 不可以匹配!
- "HelloA" 不可以
正则例子: 我[草去艹]:草、去、艹中的一个
字符范围
| 规则 | 正则表达式 | 范围 |
|---|---|---|
| 匹配 0~9 一个字符 | [0123456789] | [0-9] |
| 匹配A-Z一个字符 | [ABCDEFGHIJKLMNOPQRSTUVWXYZ] | [A-Z] |
| 匹配a-z一个字符 | ... | [a-z] |
| 匹配a-zA-Z一个字符 | [a-zA-Z]中间无空格 |
栗子:
Hello[1-6]
数量词
约定左侧元素出现的次数。
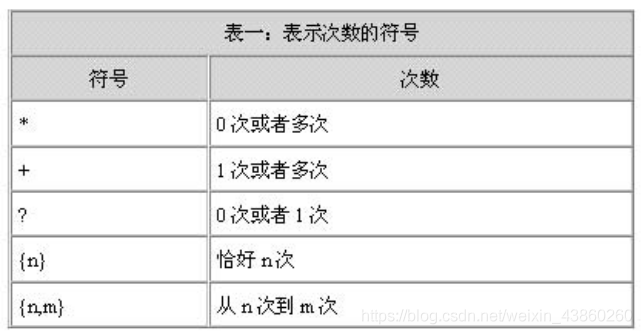
栗子:
\w\w\w\w\w\w 等价 \w{6}
语法:
X{n} 规定左侧X出现n次
X{n,m} 规定左侧X出现最少n次, 最多m次
X{0,n} 规定左侧X出现0到n次
X{n,} 规定左侧X出现最少n次
X? 和 X{0,1} 等价,X可以没有或者有一个
X+ 和 X{1,} 等价,X至少有一个,多了随意,简称:一个以上
X* 和 X{0,} 等价,X至少有0个,多了随意 简称:0个以上
栗子:
- 网站的用户名是 8~16个单词字符: \w
- 网站的密码是单词字符, 最少8个, 多了不限: \w
- 匹配Hello World,中间至少有一个空白: Hello\s+World
- 不能匹配 : "HelloWorld"
- 不能匹配: "Hello World!"
- 能匹配: "Hello World"
- 能匹配: "Hello World"
- 能匹配: "Hello World"
预定义字符集:是一种简便的规定
大写字母一般表示非
| 规则 | 正则 | 预定义字符集 | 栗子 |
|---|---|---|---|
| 匹配一个数字 | [0-9] | \d | Hello\d |
| 匹配一个单词字符 | [a-zA-Z0-9_] | \w | A\w |
| 匹配一个空白字符 | [\t\n\r\f] | \s | Hello\sWorld |
| 匹配任意一个字符 | . | A. | |
| 匹配一个非数字 | [^0—9] | \D | |
| 匹配一个非空白 | [^\t\n\r\f] | \S | |
| 匹配一个非单词字符 | [^0—9A—Z_a—z] | \W |
栗子, 网站上规则 用户名规则是6个单词字符:
正则规则: \w\w\w\w\w\w
java String: "\\w\\w\\w\\w\\w\\w"
测试案例:
package string;
public class RegDemo07 {
public static void main(String[] args) {
/*
* 测试 用户名规则:6个单词字符组成
* - \ 在java字符串中需要进行转义为 \\
*/
//正则表达式:
String reg = "\\w\\w\\w\\w\\w\\w";
System.out.println(reg);
//被检查的字符串
String s1 = "Jerry1"; //可以通过检查
String s2 = "Tom-12"; //不可以通过检查,因为"-"不为单词字符
String s3 = "Andy"; //不可以通过检查
System.out.println(s1.matches(reg));
System.out.println(s2.matches(reg));
System.out.println(s3.matches(reg));
}
}
特殊字符转义⭐⭐⭐
简单说,写进Java编程中的正则String,需要在原正则表达式上进行修改,原因如下:
在其他语言中,\\表示:我想要在正则表达式中插入一个普通的(字面上的)反斜杠,请不要给它任何特殊的意义。在 Java 中,\\表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
所以,在其他的语言中(如 Perl),一个反斜杠\就足以具有转义的作用,而在 Java 中正则表达式中则需要有两个反斜杠才能被解析为其他语言中的转义作用。
也可以简单的理解在 Java 的正则表达式中,\\代表其他语言中的一个\,这也就是为什么表示一位数字的正则表达式是\\d,而表示一个普通的反斜杠是\\
| 我们想要匹配的: | 正则表达式 | 写进Java编程regex中 |
|---|---|---|
| 匹配字母d: | "d" | "d" |
| 匹配数字0-9: | "\d" | "\\d" |
| 匹配0-7 | "[0-7]" | "[0-7]" |
| 匹配字符"[" | "\[" | "\\[" |
| 匹配字符"\" | "\ \" | "\\\\" |
有哪些字符需要转义:
[ ] ? + * . , 需要使用 \特殊字符进行转义,否则系统将会理解为特殊的含义,例如* 理解为0次或多次
\. 匹配点
\[ 匹配 [
\? 匹配 ?
\* 匹配 *
\+ 匹配 +
\\ 匹配 \
...
如下正则的意义:匹配 www.tedu.cn 域名
-
www.tedu.cn 匹配:
-
www.tedu.cn 通过
-
wwwAteduAcn 通过
-
www-tedu-cn 通过
-
www\.tedu\.cn匹配------------Java中:"www\\.tedu\\.cn"- www.tedu.cn 通过
- wwwAteduAcn 不通过
- www-tedu-cn 不通过
案例:如何检查一个字符串是否为正确的IPv4地址
正确IP:
"192.168.1.25" "192.168.199.1" "10.0.0.20" "8.8.8.8"
错误的IP:
"10-10-10-20" "192点168点5点25"
正则:\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}----java中\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}
分组
讲一组规则作为整体进行处理
栗子正则:
-
\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3} -
(\d{1,3}\.)(\d{1,3}\.)(\d{1,3}\.)\d{1,3} -
(\d{1,3}\.){3}\d{1,3}
package string;
public class RegDemo11 {
public static void main(String[] args) {
/*
* 检查IP地址是否符合规则
*/
//定义正则规则
//String reg = "\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}";
String reg = "\\d{1,3}(\\.\\d{1,3})(\\.\\d{1,3})(\\.\\d{1,3})";
//String reg = "(\\d{1,3}\\.){3}\\d{1,3}"; //测试分组
//定义被检查的字符串
String ip1 = "192.168.2.70";
String ip2 = "10.0.0.20";
String ip3 = "8.8.8.8";
//定义错误的被检查字符串
String ip4 = "192点168点2点70";
String ip5 = "192-168-2-70";
//检查
System.out.println(ip1.matches(reg));
System.out.println(ip2.matches(reg));
System.out.println(ip3.matches(reg));
System.out.println(ip4.matches(reg));
System.out.println(ip5.matches(reg));
}
}
栗子2:
-
\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3} -
\d{1,3}(\.\d{1,3})(\.\d{1,3})(\.\d{1,3}) -
\d{1,3}(\.\d{1,3}){3}
区别:
(\d{1,3}\.){3}\d{1,3} (分组){3} 分组的整体出现3次
\d{1,3}\.{3}\d{1,3} \.{3} .必须出现2次,可以匹配 “192...168”
java 正则API
- matches 检查字符串是否整体符合正则表达式规则
- split 劈开
- replaceAll 全部替换
Split 劈开字符串(重要)
将一个字符串劈开为几个子字符串:
- "192.168.5.140" 劈开为 "192" "168" "5" "140"
- "1, Tom, 110, tom@tedu.cn" 劈开为 "1" "Tom" "110" "tom@tedu.cn"
使用方法:
str 存储的是被劈开的字符串
正则 用于匹配劈开的位置点,可以按一个字符切开也可以按两个字符切开 如: , 或者 \.
返回值 是劈开以后的数组,每个元素是 劈开的子字符串段落
劈开以后,匹配的位置就没有了
String[] arr = str.split(正则);
案例:
String str = "1, Tom, 110, tom@tedu.cn";
// , , ,
// arr= "1" " Tom" " 110" " tom@tedu.cn"
String[] arr = str.split(",");
for(int i=0; i<arr.length; i++){
System.out.println(arr[i]);
}
replaceAll
replace: 替换
all:全部
将正则表达式匹配到的字符,都替换为新字符串
例子:
我草疫情又严重了,我去,又要做核算了。
需要替换为 ***疫情又严重了,***,又要做核算了。
代码:
Scanner scanner = new Scanner(System.in);
System.out.print("请输入:");
String str = scanner.nextLine();
//String str = "我草疫情又严重了,我去,又要做核算了。";
// str.replaceAll("正则", 替换字符串);
String s = str.replaceAll("我[去草靠艹]", "***");
System.out.println(s);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号