一只亚马逊商品信息小爬虫
阅读本文需要一点Python基础,建议大佬绕过...
要爬取的页面(亚马逊搜索页面):
.jpg)
要取的内容:

代码:
import requests import re import json from bs4 import BeautifulSoup from urllib.parse import urljoin headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36' } #用于伪造请求头 original_url = 'https://www.amazon.cn' def get_onePage(key,page): url = "https://www.amazon.cn/s?k="+key+'&page='+str(page) #k后面的为搜索的关键字 r = requests.session() #利用requests.session()去请求页面可以记住cookies res = r.get(url=url,headers=headers) res.encoding = res.apparent_encoding #设置编码为requests从内容中分析出的编码方式而不是网站给出的编码 soup = BeautifulSoup(res.text,"lxml") result = soup.find_all(name='div',attrs={'data-index':True,'class':re.compile("sg-col-4-of-16 sg-col")}) onePage = {} temp = {} for i in result: ''' 这里是获取详情,跟网页的结构有关,其实不必太在意这部分 ''' title = i.find(name="span",attrs={'class':'a-size-base-plus a-color-base a-text-normal'}) title = title.string if title else '' #标题 imgUrl = i.find(name="img", attrs={'class': 's-image'}) imgUrl = imgUrl.attrs['src'] if imgUrl else '' #商品图片链接 price = i.find(name="span", attrs={'class': 'a-offscreen'}) price = price.string if price else '' #商品价格 star = i.find(name="span", attrs={'class': 'a-icon-alt'}) star = star.string if star else '' #星星 numberOfStar = i.find(name="span", attrs={'class': 'a-size-base'}) numberOfStar = numberOfStar.string if numberOfStar else '' #(给星星的)评价的人数 selfSupport = i.find(name="span", attrs={'class': 's-self-operated aok-align-bottom aok-inline-block a-text-normal'}) selfSupport = selfSupport.string if selfSupport else '' #是否是自营 detailUrl = i .find(name='a',attrs={'class':'a-link-normal a-text-normal'}) detailUrl = urljoin(original_url,detailUrl.attrs['href'])if detailUrl else '' #商品详情链接 onePage[detailUrl] = [{'title':title},{'imgUrl':imgUrl},{'price':price},{'star':star},{'numberOfStar':numberOfStar},{'selfSupport':selfSupport}] return onePage for i in range(1,11): #没有登录的话亚马逊只给出10页的匹配到关键字的商品 content = get_onePage('电脑', i) with open('amazon.json','a',encoding='utf-8') as f: json.dump(content, f, ensure_ascii=False, sort_keys=True, indent=4) #获取的内容格式写入json文件
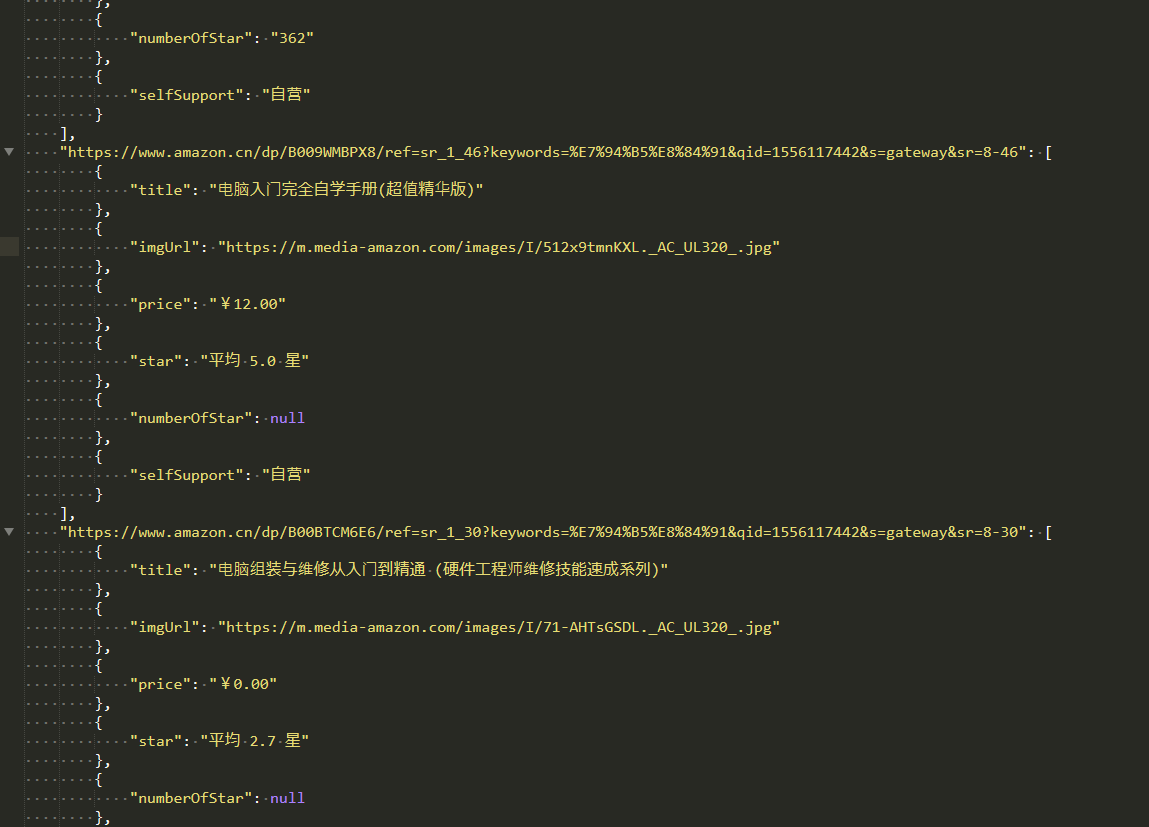
保存的结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号