

序列化-源码-创建字段与类
1 运行django项目
class Foo(objiect,metaclass=MyType):
v1=123
v2=456
#类不是先创建,先创建值。
#好比
Foo=MyType("foo",(),{"v1":123,"v2":456})
#所以是值v1=123先创建,如果是有方法也是先创建方法,打包传递给MyType,才将类创建出来。
创建字段对象
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import serializers
from api import models
# 先进行实例化对象
class InfoSerializer(serializers.Serializer):
id = serializers.IntegerField()
title = serializers.CharField()
order = serializers.IntegerField()
#只对这一步进行分析id = serializers.IntegerField()
class Field:
_creation_counter = 0
def __init__(self, *, read_only=False...):
self._creation_counter = Field._creation_counter
Field._creation_counter += 1 #这个玩意需要注意
class IntegerField(Field):
def __init__(self, **kwargs):
...#执行完一些功能
super().__init__(**kwargs)#然后执行父类的init,然后父类是谁 field
class InfoSerializer(serializers.Serializer):
id = serializers.IntegerField() # 对象,内部_creation_counter=0
title = serializers.CharField() # 对象,内部_creation_counter=1
order = serializers.IntegerField # 对象,内部_creation_counter=2
后续会通过这个计数器排序,以此来实现字段的先后执行。
创建类
class SerializerMetaclass(type):
@classmethod
def _get_declared_fields(cls, bases, attrs):#被pop掉的成员放在了这
#然后就会得到fields=[("id",对象),("title",对象),("order",对象)]
fields = [(field_name, attrs.pop(field_name))#成员都在这,pop就是删除自己的成员
for field_name, obj in list(attrs.items())#去循环自己的成员
if isinstance(obj, Field)]#进行判断,例:isinstance(id,IntegerField) #True
fields.sort(key=lambda x: x[1]._creation_counter)#进行了排序
known = set(attrs)
def visit(name):
known.add(name)
return name
base_fields = [
(visit(name), f)
for base in bases if hasattr(base, '_declared_fields')
for name, f in base._declared_fields.items() if name not in known
]# 找它所有的父类
return OrderedDict(base_fields + fields)#相当于两个列表相加
def __new__(cls, name, bases, attrs):#现在执行new,name就是它的类名,bases就是它继承的类,attrs就是它的成员。
attrs['_declared_fields'] = cls._get_declared_fields(bases, attrs)#相当于多加了一个成员_declared_fields。
#cls._get_declared_fields,这个取的是它所有的字段对象,包含的是自己的和父类的。
return super().__new__(cls, name, bases, attrs)
用户请求到来,数据库获取数据+序列化类
queryset = models.UserInfo.objects.all()
ser = DepartSerializer(instance=queryset, many=True)
instance=models.UserInfo.object.all().firsr()
ser = UserSerializer(instance=instance,many=False)
#先去找new方法,如果找不到就在父类里找。
class SerializerMetaclass(type):
pass
class BaseSerializer(obje):
执行完new方法就执行init方法,同样找不到就父类找,最后还是在basel里找到init方法。
def __init__(self, instance=None, data=empty, **kwargs):
self.instance = instance
***
def __new__(cls, *args, **kwargs):#最后在base里找到了new方法
if kwargs.pop('many', False):
return cls.many_init(*args, **kwargs)#如果many等于TRUE,走这里。
return super().__new__(cls, *args, **kwargs)#如果many等于False。创建当前类的对象。
如果many=True,那么就要找many_init,同样找不到就父类找最后还是在basel里找到方法。
@classmethod
def many_init(cls, *args, **kwargs):#cls代表当前类 也就是指InfoSerializer
child_serializer = cls(*args, **kwargs) #在这个地方实例化了InfoSerializer这个对象
meta = getattr(cls, 'Meta', None)#然后读取InfoSerializer这个对象中的Meta
list_serializer_class = getattr(meta, 'list_serializer_class', ListSerializer)
return list_serializer_class(*args, **list_kwargs)
序列化的过程
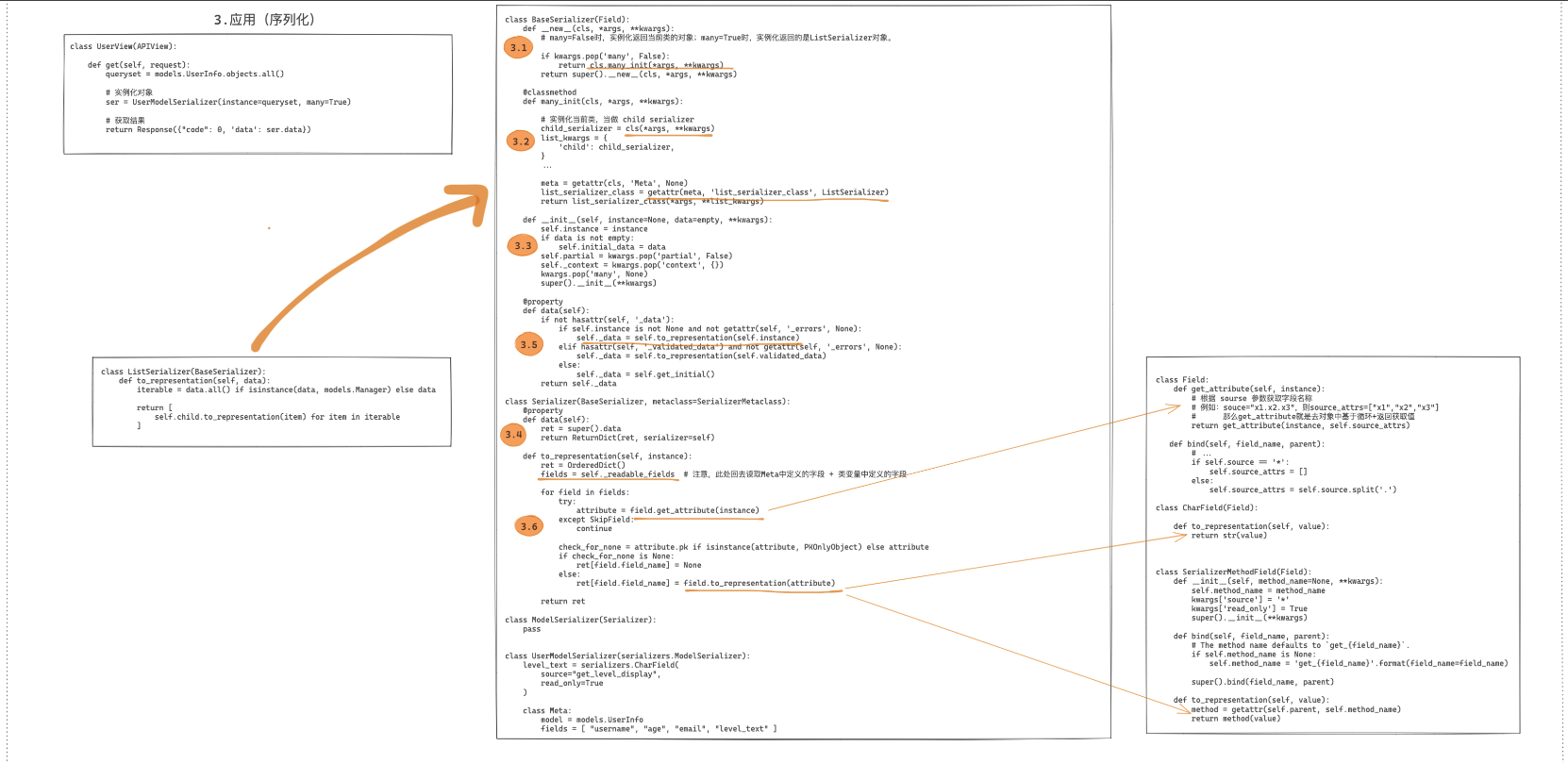
class UserView(APIView):
def get(self, request, *args, **kwargs):
# 1.获取数据
queryset = models.UserInfo.objects.all()
# 2.序列化 封装了我们的数据
ser = UserSerializer(instance=queryset, many=True)
# 3.返回给用户这里ser.data才是真正触发序列化的存在
context = {"status": True, "data": ser.data}
return Response(context)
触发序列化ser.data-当前类
class SerializerMetaclass(type):
class BaseSerializer(obje):
def __init__(self, instance=None, data=empty, **kwargs):
self.instance = instance
***
def __new__(cls, *args, **kwargs):
if kwargs.pop('many', False):
return cls.many_init(*args, **kwargs)
return super().__new__(cls, *args, **kwargs)
@property
def data(self):
if hasattr(self, 'initial_data') and not hasattr(self, '_validated_data'):
msg = (
'When a serializer is passed a `data` keyword argument you '
'must call `.is_valid()` before attempting to access the '
'serialized `.data` representation.\n'
'You should either call `.is_valid()` first, '
'or access `.initial_data` instead.'
)
raise AssertionError(msg)
if not hasattr(self, '_data'):
if self.instance is not None and not getattr(self, '_errors', None):
self._data = self.to_representation(self.instance)#这是主要的,核心序列化,json格式
elif hasattr(self, '_validated_data') and not getattr(self, '_errors', None):
self._data = self.to_representation(self.validated_data)
else:
self._data = self.get_initial()
return self._data
class Serializer(BaseSerializer, metaclass=SerializerMetaclass):
@property
def data(self):
ret = super().data #这有super().data,调用了父类里的data
return ReturnDict(ret, serializer=self)
@cached_property
def fields(self):
fields = BindingDict(self)
for key, value in self.get_fields().items():
fields[key] = value
return fields
@property
def _readable_fields(self):
for field in self.fields.values():
if not field.write_only:
yield field
def to_representation(self, instance):# instance
ret = OrderedDict()
fields = self._readable_fields#获取所有的字段+meta里面的fields字段创建对象
for field in fields:
try:
attribute = field.get_attribute(instance)
except SkipField:
continue
check_for_none = attribute.pk if isinstance(attribute, PKOnlyObject) else attribute
if check_for_none is None:
ret[field.field_name] = None
else:
ret[field.field_name] = field.to_representation(attribute)
return ret #序列化返回后的结果
class ModelSerializer(Serializer):
def get_fields(self):
declared_fields = copy.deepcopy(self._declared_fields)#类变量中定义那些字段对象
model = getattr(self.Meta, 'model')#数据库的表=类 model=models.UserInfo
depth = getattr(self.Meta, 'depth', 0)
if depth is not None:
assert depth >= 0, "'depth' may not be negative."
assert depth <= 10, "'depth' may not be greater than 10."
# Retrieve metadata about fields & relationships on the model class.
info = model_meta.get_field_info(model)
field_names = self.get_field_names(declared_fields, info)
# Determine any extra field arguments and hidden fields that
# should be included
extra_kwargs = self.get_extra_kwargs()
extra_kwargs, hidden_fields = self.get_uniqueness_extra_kwargs(
field_names, declared_fields, extra_kwargs
)
# Determine the fields that should be included on the serializer.
fields = OrderedDict()
for field_name in field_names:
# If the field is explicitly declared on the class then use that.
if field_name in declared_fields:
fields[field_name] = declared_fields[field_name]
continue
extra_field_kwargs = extra_kwargs.get(field_name, {})
source = extra_field_kwargs.get('source', '*')
if source == '*':
source = field_name
# Determine the serializer field class and keyword arguments.
field_class, field_kwargs = self.build_field(
source, info, model, depth
)
# Include any kwargs defined in `Meta.extra_kwargs`
field_kwargs = self.include_extra_kwargs(
field_kwargs, extra_field_kwargs
)
# Create the serializer field.
fields[field_name] = field_class(**field_kwargs)
# Add in any hidden fields.
fields.update(hidden_fields)
return fields

触发序列化-当前类
后面老师讲的我晕了,捋不过来了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号