

关于fork函数中的内存复制和共享
原来刚刚开始做linux下面的多进程编程的时候,对于下面这段代码感到很奇怪,
1 #include<unistd.h> 2 #include<stdio.h> 3 #include<string.h> 4 #include<stdlib.h> 5 #include<stdarg.h> 6 #include<errno.h> 7 #define LEN 2 8 void err_exit(char *fmt,...); 9 int main(int argc,char *argv[]) 10 { 11 pid_t pid; 12 int loop; 13 14 for(loop=0;loop<LEN;loop++) 15 { 16 if((pid=fork()) < 0) 17 err_exit("[fork:%d]: ",loop); 18 else if(pid == 0) 19 { 20 printf("Child process\n"); 21 } 22 else 23 { 24 sleep(5); 25 } 26 } 27 28 return 0; 29 }
为什么这段程序会创建3个子进程,而不是两个,为什么在第20行后面加上一个return 0;就创建的又是两个子进程了?原来一直搞不明白,后来了解了C语言程序的存储空间布局以及在fork之后父子进程是共享正文段(代码段CS)之后才明白这其中的缘由!具体原理是啥,且容我慢慢道来!
首先得明白一个东西就是C程序的存储空间布局,如下图所示:
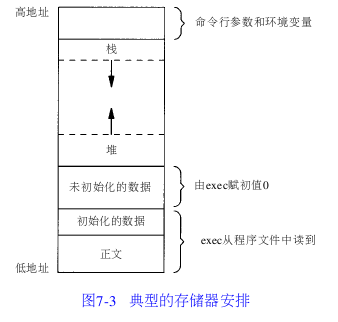 (原图出自《UNIX环境高级编程》7.6节)
(原图出自《UNIX环境高级编程》7.6节)
当一个C程序执行之后,它会被加载到内存之中,它在内存中的布局如上图,分为这么几个部分,环境变量和命令行参数、栈、堆、数据段(初始化和未初始化的)、正文段,下面挨个来说明这几段分别代表了什么:
环境变量和命令行参数:这些指的就是Unix系统上的环境变量(比如$PATH)和传给main函数的参数(argv指针所指向的内容)。
数据段:这个是指在C程序中定义的全局变量,如果没有初始化,那么就存放在未初始化的数据段中,程序运行时统一由exec赋值为0。否则就存放在初始化的数据段中,程序运行时由exec统一从程序文件中读取。(了解汇编的朋友们想必知道汇编语言中的数据段DS,这和汇编中的数据段其实是一个东西)。
堆:这一部分主要用来动态分配空间。比如在C语言中用malloc申请的空间就是在这个区域申请的。
正文段:C语言代码并不是直接执行的,而是被编译成了机器指令才能够在电脑上执行,最终生成的机器指令就是存放在这个区域(汇编中的代码段CS指的就是这片区域)。
栈:个人感觉这是C程序内存布局最关键的部分了。这个部分主要用来做函数调用。具体而言怎么说呢,程序刚开始栈中只有main这一个函数的内容(即main的栈帧),如果main函数要调用func函数,那么func函数的返回地址(main函数的地址),func函数的参数,func函数中定义的局部变量,还有func函数的返回值等等这些都会被压入栈中,这时栈中就多了func函数的内容(func的栈帧)。然后func函数运行完了之后再来弹栈,把它原来压的内容去掉(即清除掉func栈帧),此时栈中又只剩下了main的栈帧。(这片区域就是汇编中的栈段SS)
OK,这就是C程序的存储器布局。这里我联想到另外一点,就是全局变量和静态变量是存储在数据段中的,而局部变量是存储在栈中的,栈中数据在函数调用完之后一弹栈就没了,这就是为什么全局变量的生存周期比局部变量的生存周期要长的原因。
了解了C程序在存储器的布局之后,我们再来了解fork的内存复制机制,关于这个,我们只需要了解一句话就够了,“子进程复制父进程的数据空间(数据段)、栈和堆,父、子进程共享正文段。”也就是说,对于程序中的数据,子进程要复制一份,但是对于指令,子进程并不复制而是和父进程共享。具体来看下面这段代码(这是我在上面那段代码上稍微添加了一点东西):
1 /* 这个程序会创建3个子进程,理解这句话,父子进程复制数据段、栈、堆,共享正文段 2 * 3 */ 4 #include<unistd.h> 5 #include<stdio.h> 6 #include<string.h> 7 #include<stdlib.h> 8 #include<stdarg.h> 9 #include<errno.h> 10 #define BUFSIZE 512 11 #define LEN 2 12 void err_exit(char *fmt,...); 13 int main(int argc,char *argv[]) 14 { 15 pid_t pid; 16 int loop; 17 18 for(loop=0;loop<LEN;loop++) 19 { 20 printf("Now is No.%d loop:\n",loop); 21 22 if((pid=fork()) < 0) 23 err_exit("[fork:%d]: ",loop); 24 else if(pid == 0) 25 { 26 printf("[Child process]P:%d C:%d\n",getpid(),getppid()); 27 } 28 else 29 { 30 sleep(5); 31 } 32 } 33 34 return 0; 35 }
为什么上面那段代码会创建三个子进程?我们来具体分析一下它的执行过程:
首先父进程执行循环,通过fork创建一个子进程,然后sleep5秒。
再来看父进程创建的这个子进程,这里我们记为子进程1.子进程1完全复制了这个父进程的数据部分,但是需要注意的是它的正文段是和父进程共享的。也就是说,子进程1开始执行代码的部分并不是从main的 { 开始执行的,而是主函数执行到哪里了,它就接着执行,具体而言就是它会执行fork后面的代码。所以子进程1首先会打印出它的ID和它的父进程的ID。然后继续第二遍循环,然后这个子进程1再来创建一个子进程,我们记为子进程11,子进程1开始sleep。
子进程11接着子进程1执行的代码开始执行(即fork后面),它也是打印出它的ID和父进程ID(子进程1),然后此时loop的值再加1就等于2了,所以子进程2直接就返回了。
那个子进程1sleep完了之后也是loop的值加1之后变成了2,所以子进程1也返回了!
然后我们再返回去看父进程,它仅仅循环了一次,sleep完之后再来进行第二次循环,这次又创建了一个子进程我们记为子进程2。然后父进程开始sleep,sleep完了之后也结束了。
那么那个子进程2怎么样了呢?它从fork后开始执行,此时loop等于1,它打印完它的ID和父进程ID之后,就结束循环了,整个子进程2就直接结束了!
这就是上面那段代码的运行流程,进程间的关系如下图所示:

上图中那个loop=%d就是当这个进程开始执行的时候loop的值。上面那段代码的运行结果如下图:

这里这个3498进程就是我们的主进程,3499就是子进程1,3500就是子进程11,3501就是子进程2。
最后,我们再来回答一下我们开始的时候提出的那个问题,为什么在子进程的处理部分“ if(pid == 0) ”最后加一个return 0,就会创建两个子进程了,就是因为子进程1运行到这里直接就结束了,不再进行第二遍循环了,所以就不会再去创建那个子进程11了,所以最后一共就是创建了两个子进程啊!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号