
爬虫小练习
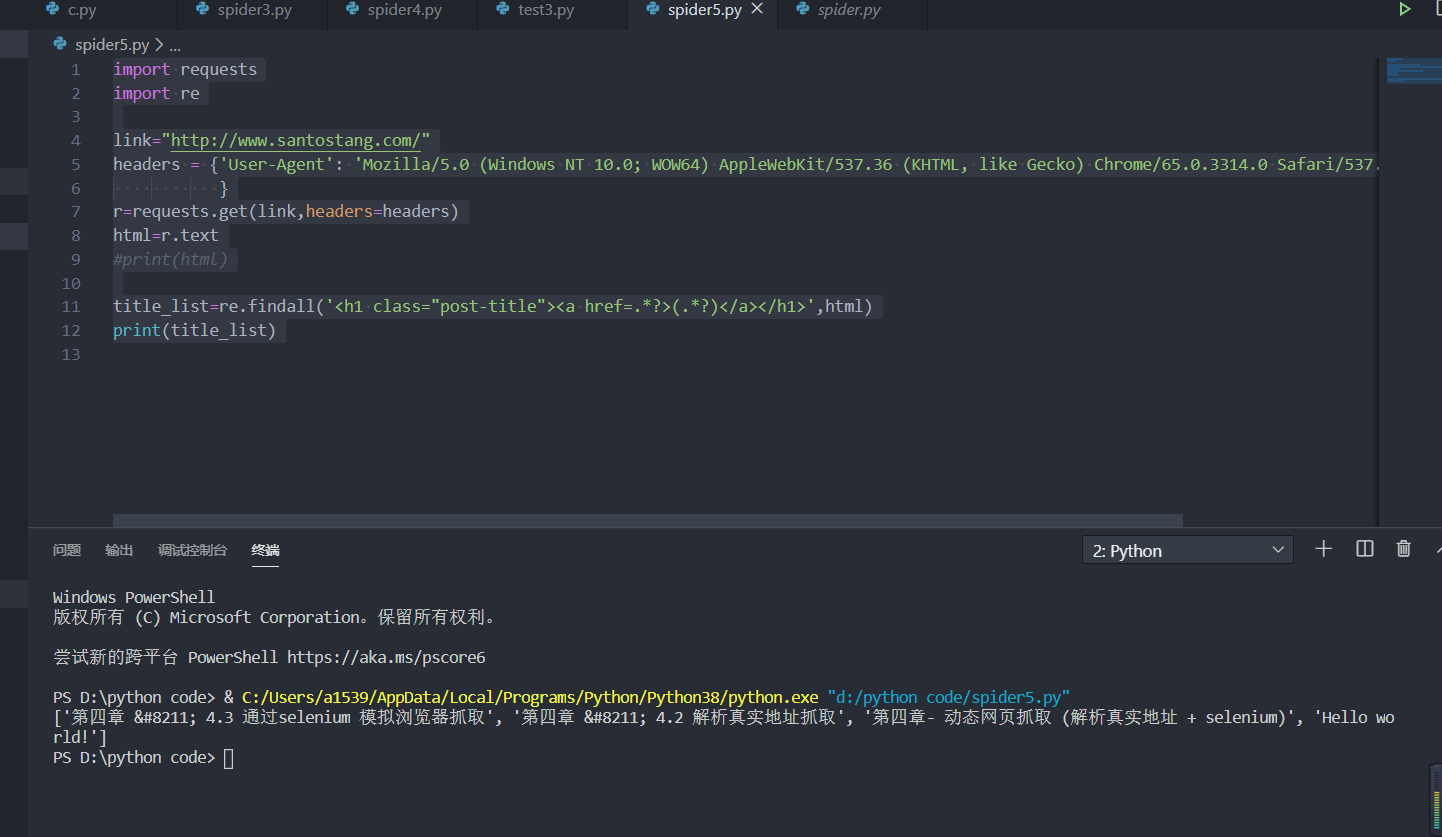
import requests import re link="http://www.santostang.com/" headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0' } r=requests.get(link,headers=headers) html=r.text #print(html) title_list=re.findall('<h1 class="post-title"><a href=.*?>(.*?)</a></h1>',html) print(title_list)
少说话多做事,收起自己多余的感情。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号