

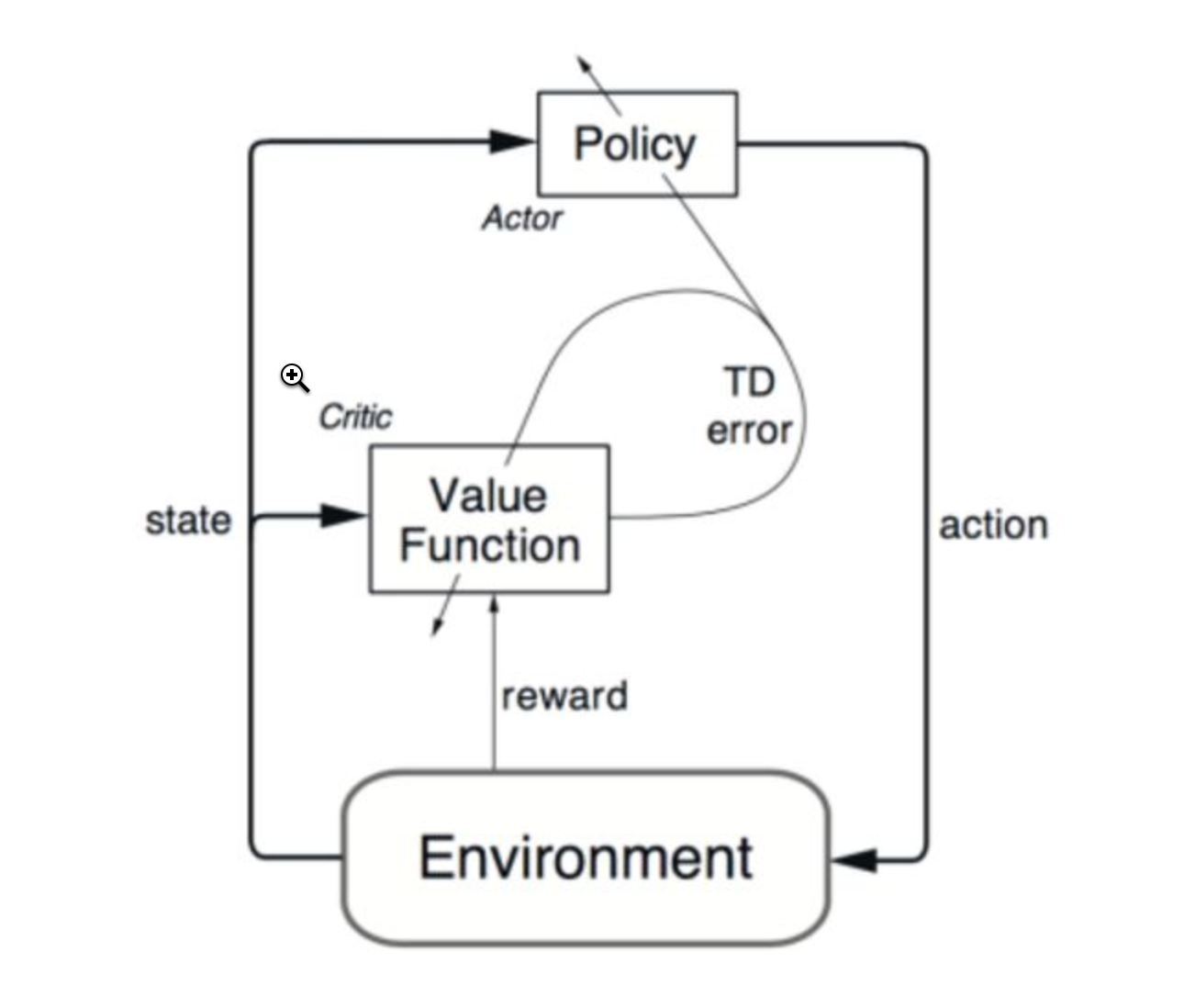
深度增强学习--Actor Critic
Actor Critic value-based和policy-based的结合
1 import sys 2 import gym 3 import pylab 4 import numpy as np 5 from keras.layers import Dense 6 from keras.models import Sequential 7 from keras.optimizers import Adam 8 9 EPISODES = 1000 10 11 12 # A2C(Advantage Actor-Critic) agent for the Cartpole 13 # actor-critic算法结合了value-based和policy-based方法 14 class A2CAgent: 15 def __init__(self, state_size, action_size): 16 # if you want to see Cartpole learning, then change to True 17 self.render = True 18 self.load_model = False 19 # get size of state and action 20 self.state_size = state_size 21 self.action_size = action_size 22 self.value_size = 1 23 24 # These are hyper parameters for the Policy Gradient 25 self.discount_factor = 0.99 26 self.actor_lr = 0.001 27 self.critic_lr = 0.005 28 29 # create model for policy network 30 self.actor = self.build_actor() 31 self.critic = self.build_critic() 32 33 if self.load_model: 34 self.actor.load_weights("./save_model/cartpole_actor.h5") 35 self.critic.load_weights("./save_model/cartpole_critic.h5") 36 37 # approximate policy and value using Neural Network 38 # actor: state is input and probability of each action is output of model 39 def build_actor(self):#actor网络:state-->action 40 actor = Sequential() 41 actor.add(Dense(24, input_dim=self.state_size, activation='relu', 42 kernel_initializer='he_uniform')) 43 actor.add(Dense(self.action_size, activation='softmax', 44 kernel_initializer='he_uniform')) 45 actor.summary() 46 # See note regarding crossentropy in cartpole_reinforce.py 47 actor.compile(loss='categorical_crossentropy', 48 optimizer=Adam(lr=self.actor_lr)) 49 return actor 50 51 # critic: state is input and value of state is output of model 52 def build_critic(self):#critic网络:state-->value,Q值 53 critic = Sequential() 54 critic.add(Dense(24, input_dim=self.state_size, activation='relu', 55 kernel_initializer='he_uniform')) 56 critic.add(Dense(self.value_size, activation='linear', 57 kernel_initializer='he_uniform')) 58 critic.summary() 59 critic.compile(loss="mse", optimizer=Adam(lr=self.critic_lr)) 60 return critic 61 62 # using the output of policy network, pick action stochastically 63 def get_action(self, state): 64 policy = self.actor.predict(state, batch_size=1).flatten()#根据actor网络预测下一步动作 65 return np.random.choice(self.action_size, 1, p=policy)[0] 66 67 # update policy network every episode 68 def train_model(self, state, action, reward, next_state, done): 69 target = np.zeros((1, self.value_size))#(1,1) 70 advantages = np.zeros((1, self.action_size))#(1, 2) 71 72 value = self.critic.predict(state)[0]#critic网络预测的当前q值 73 next_value = self.critic.predict(next_state)[0]#critic网络预测的下一个q值 74 75 ''' 76 理解下面部分 77 ''' 78 if done: 79 advantages[0][action] = reward - value 80 target[0][0] = reward 81 else: 82 advantages[0][action] = reward + self.discount_factor * (next_value) - value#acotr网络 83 target[0][0] = reward + self.discount_factor * next_value#critic网络 84 85 self.actor.fit(state, advantages, epochs=1, verbose=0) 86 self.critic.fit(state, target, epochs=1, verbose=0) 87 88 89 if __name__ == "__main__": 90 # In case of CartPole-v1, maximum length of episode is 500 91 env = gym.make('CartPole-v1') 92 # get size of state and action from environment 93 state_size = env.observation_space.shape[0] 94 action_size = env.action_space.n 95 96 # make A2C agent 97 agent = A2CAgent(state_size, action_size) 98 scores, episodes = [], [] 99 100 for e in range(EPISODES): 101 done = False 102 score = 0 103 state = env.reset() 104 state = np.reshape(state, [1, state_size]) 105 106 while not done: 107 if agent.render: 108 env.render() 109 110 action = agent.get_action(state) 111 next_state, reward, done, info = env.step(action) 112 next_state = np.reshape(next_state, [1, state_size]) 113 # if an action make the episode end, then gives penalty of -100 114 reward = reward if not done or score == 499 else -100 115 116 agent.train_model(state, action, reward, next_state, done)#每执行一次action训练一次 117 118 score += reward 119 state = next_state 120 121 if done: 122 # every episode, plot the play time 123 score = score if score == 500.0 else score + 100 124 scores.append(score) 125 episodes.append(e) 126 pylab.plot(episodes, scores, 'b') 127 pylab.savefig("./save_graph/cartpole_a2c.png") 128 print("episode:", e, " score:", score) 129 130 # if the mean of scores of last 10 episode is bigger than 490 131 # stop training 132 if np.mean(scores[-min(10, len(scores)):]) > 490: 133 sys.exit() 134 135 # save the model 136 if e % 50 == 0: 137 agent.actor.save_weights("./save_model/cartpole_actor.h5") 138 agent.critic.save_weights("./save_model/cartpole_critic.h5")
桔桔桔桔桔桔桔桔桔桔

 浙公网安备 33010602011771号
浙公网安备 33010602011771号