
爬虫-英文小说_分析
文章目录
研究背景
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
通俗来讲,假如你需要互联网上的信息,如商品价格,图片视频资源等,但你又不想或者不能自己一个一个自己去打开网页收集,这时候你便写了一个程序,让程序按照你指定好的规则去互联网上收集信息,这便是爬虫,我们熟知的百度,谷歌等搜索引擎背后其实也是一个巨大的爬虫。
爬虫合法吗?
一般来说只要不影响人家网站的正常运转,也不是出于商业目的,人家一般也就只会封下的IP,账号之类的,不至于法律风险。
文章的背景:(本文仅作学习交流)
爬取一篇英文文章,并对其进行分析。文章选择了简爱的小说,分析有词频分析,单词长度统计。附带中文的词云。
提示:以下是本篇文章正文内容,下面案例可供参考
一、相关原理
网络爬虫是一个自动提取网页的程序,它为
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1)对抓取目标的描述或定义;
(2)对网页或数据的分析与过滤;
(3)对
文章采用的环境:
python 3.9 + bs4 + jieba + matplotlib + wordcloud + PIL + numpy + urllib
还需要一些前端知识来解析html文本。
具体原理见后。
二、设计思想

![]()
寻找目标 -》 爬取 -》 保存 -》分析
二、实现过程
1.分析页面
1.爬虫目标
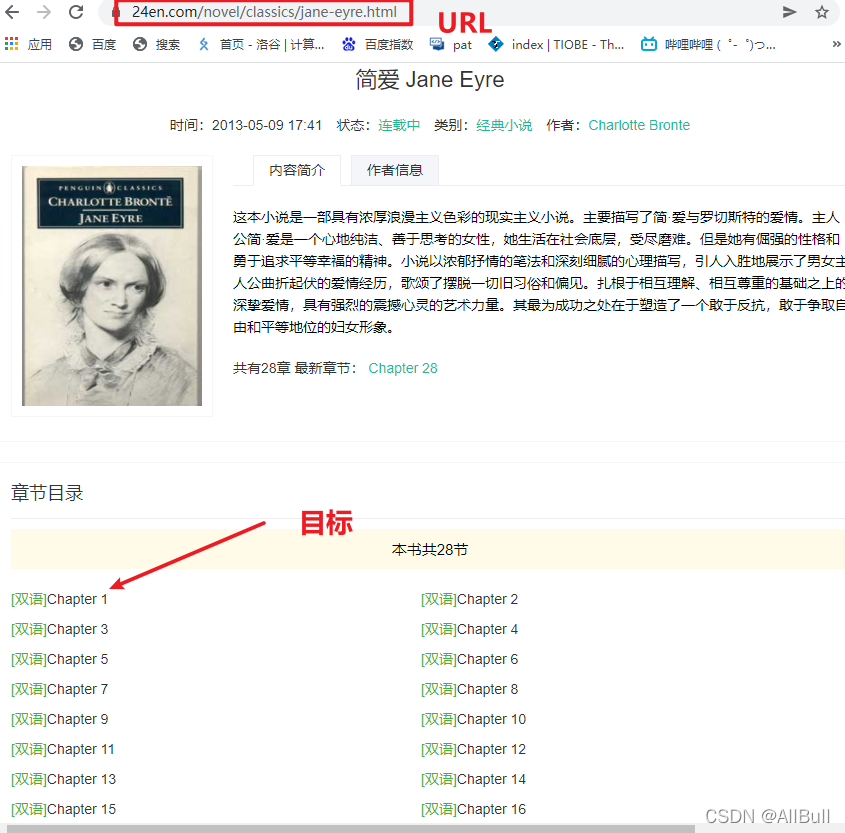
![]()
2.页面的分析
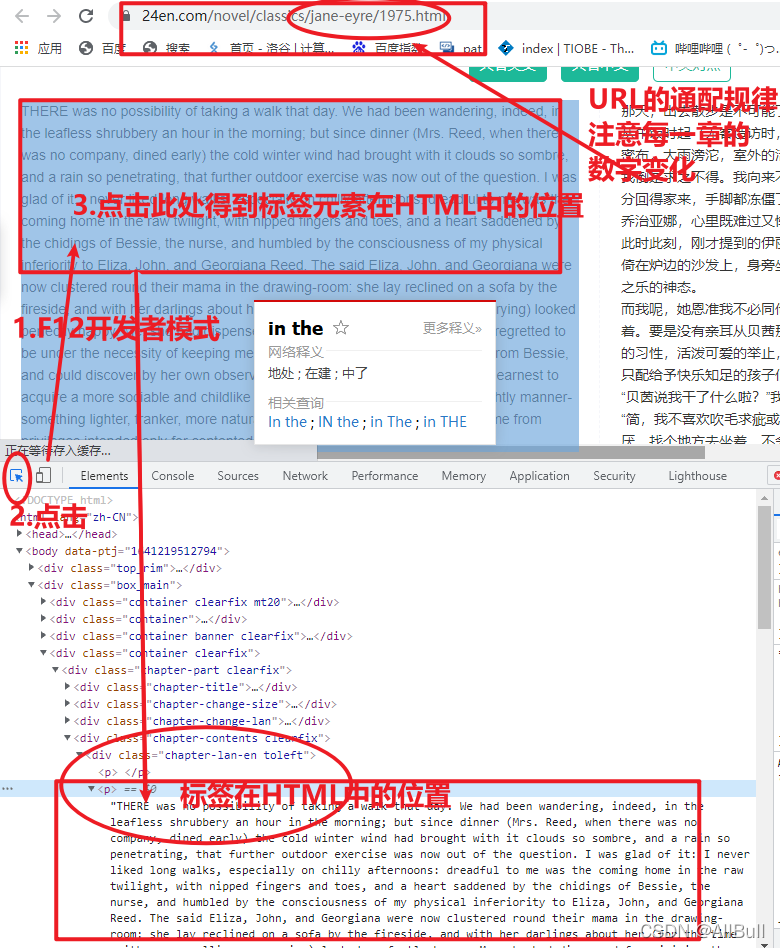
![]()
3.章节的URL
第一章:

![]()
第二章:

![]()
第三章:
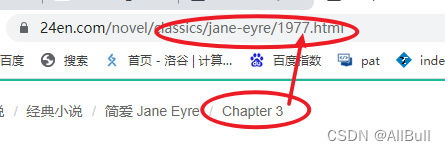
![]()
规律:
第i章的URL为:
由此可的,第28章的url为:
1975+28-1 = 2002
https://www.24en.com/novel/classics/jane-eyre/2002.html

![]()
2.引入模块
from bs4 import BeautifulSoup # 网页解析
import urllib.request, urllib.error # 指定URL
import jieba # 分词
from matplotlib import pyplot as plt # 绘图 数据可视化
from wordcloud import WordCloud # 词云
from PIL import Image # 图片处理
import numpy as np # 矩阵运算
import xlwt # EXCEL处理3.获取数据
使用库函数,拼接url,循环访问网址,对爬取到的html进行解析,循环保存到txt文档中。
具体见源代码中的注释。
4.分析数据
具体见源代码中的注释。
5.词云
具体见源代码中的注释。
三、结果展示
1.英文文本
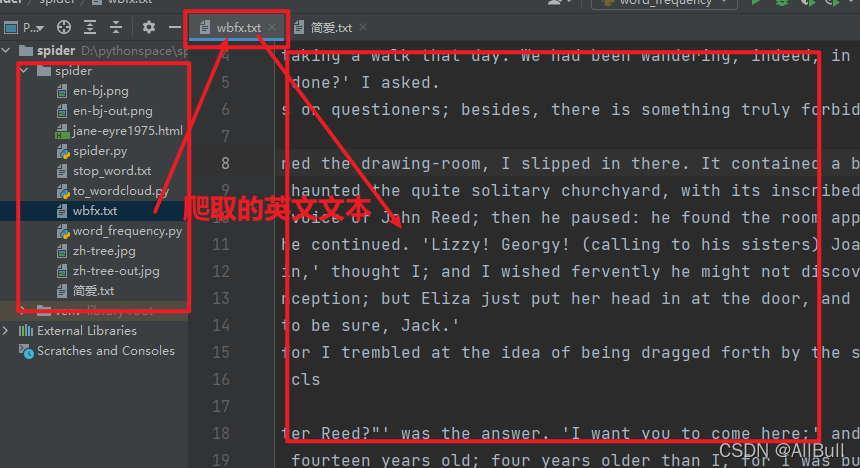
![]()
2.中文文本
![]()
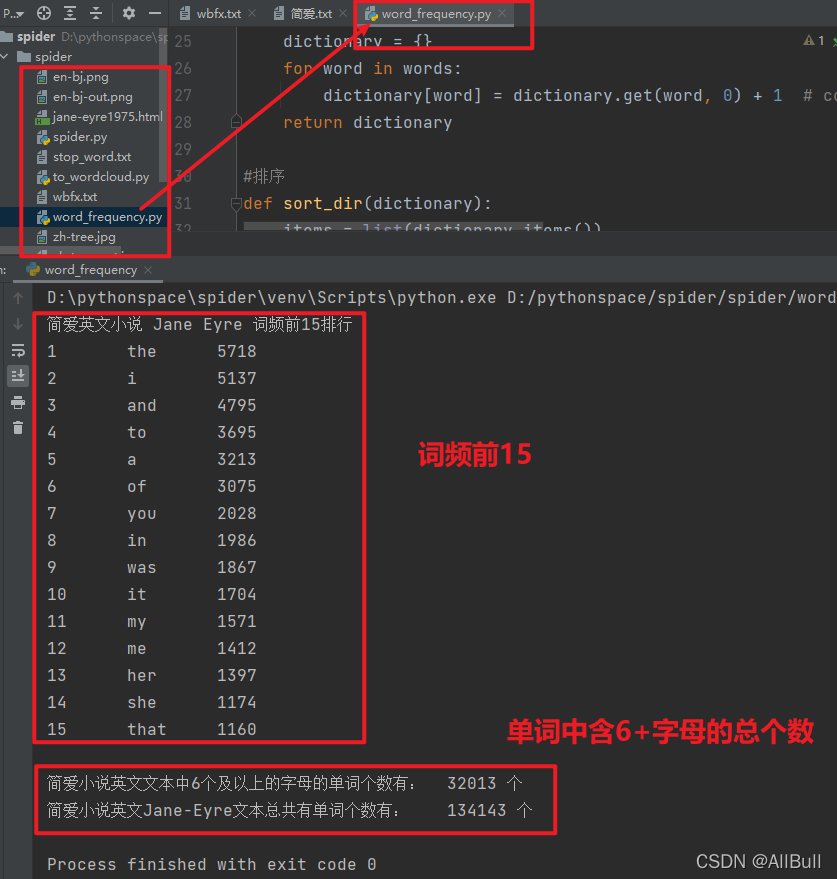
3.词频及字母数的分析
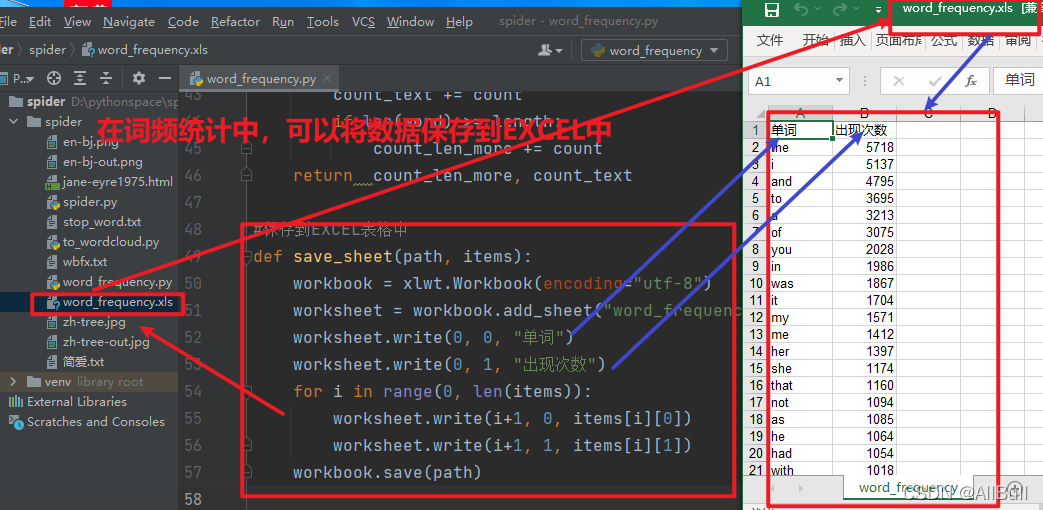
![]()
![]()
4.词云
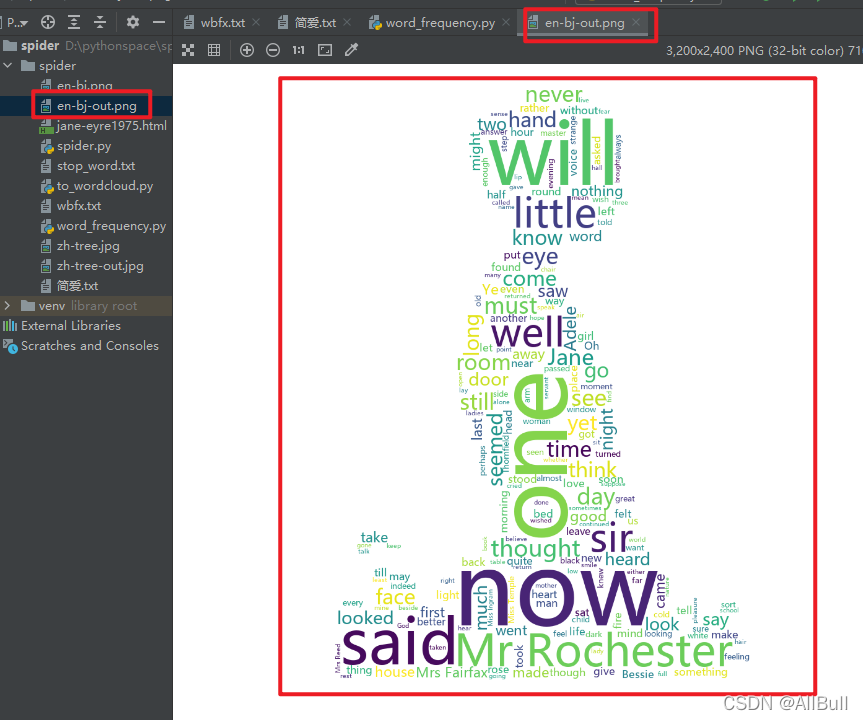
![]()
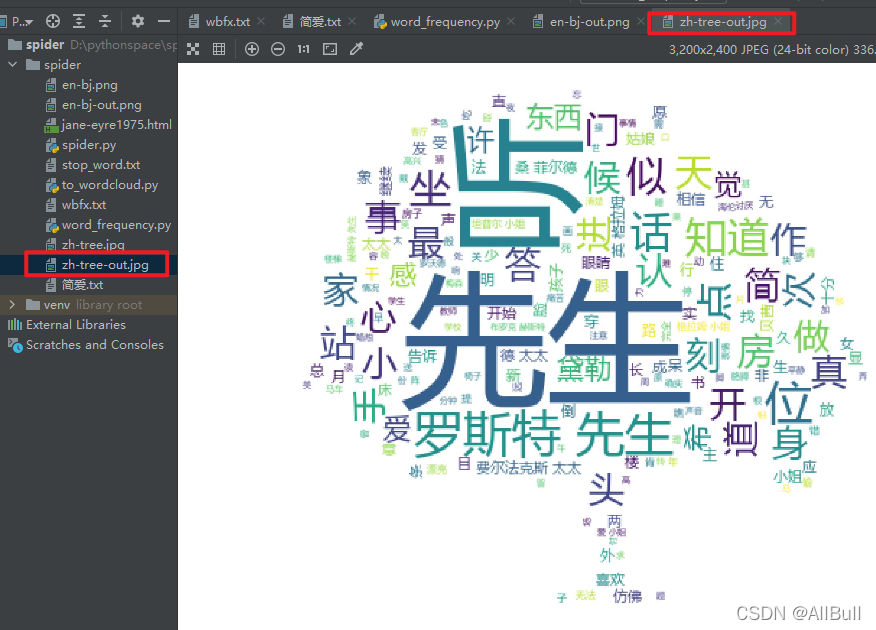
![]()
四、感想及此项目结构
项目中功能都完整实现,并进行了功能的封装,比如输出含有字母个数的单词数的函数(可以统计不是特定的数量的单词长度):
#得到 length个及以上的字母的单词个数
def get_count_len(items, length: int):
count_len_more = 0
count_text = 0 # 此单词数
for word, count in items:
count_text += count
if len(word) >= length:
count_len_more += count
return count_len_more, count_text项目结构:
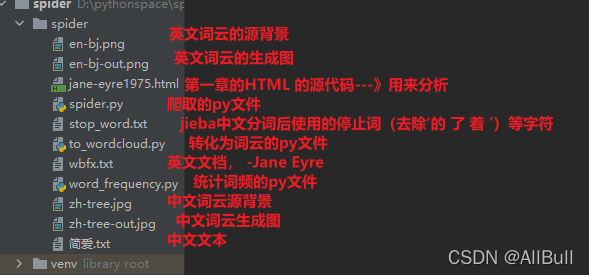
![]()
![]()
要注意的代码有:
1.# lambda x:x[0]给列表中元组 的(key)给sort排序,x:x[1]代表字典的值(values)给sort排序,reverse=true表示降序
def sort_dir(dictionary):
items = list(dictionary.items())
items.sort(key=lambda x: x[1],
reverse=True)
return items2.# counts.get (word,0)+ 1 是指有word时返回其值,默认是0,+1能够累计次数;没有word时则返回0。
def make_dictionary(text_en):
words = text_en.split()
dictionary = {}
for word in words:
dictionary[word] = dictionary.get(word, 0) + 1
return dictionary五、源代码
1 # -*- coding = utf-8 -*- 2 # @Time : 2022/1/3 11:35 3 # @Author : butupi 4 # @File : spider.py 5 # @Software : PyCharm 6 7 from bs4 import BeautifulSoup # 网页解析 8 import urllib.request, urllib.error # 指定URL 9 10 11 def main(): 12 # 爬取的url_base部分 13 baseurl = "https://www.24en.com/novel/classics/jane-eyre/" #1975-2002 14 # 爬取保存 15 getData(baseurl) 16 17 18 # 爬取网页 19 def getData(baseurl): 20 #简爱一共28章 21 for i in range(0, 28): 22 #完整的URL,url起始 的数字是1975,每章的url都是在此基础上加1 23 url = baseurl + str(1975+i)+".html" # 换页读取 24 #访问网页 25 html = askURL(url) # 保存获取到的源码 26 # 解析 保存 27 soup = BeautifulSoup(html, "html.parser") 28 with open("wbfx.txt", "a+", encoding="utf-8") as f: 29 f.writelines("\n Chapter"+str(i+1)+" \n") 30 for item in soup.find_all("div", class_="chapter-lan-en toleft"): # 查找符合要求的字符串 31 for p in item.p.children: 32 f.writelines(p.string.replace(u'\xa0', '')) 33 with open("简爱.txt", "a+", encoding="utf-8") as f: 34 f.writelines("\n 第" + str(i+1) + "章 \n") 35 for item in soup.find_all("div", class_="chapter-lan-zh toright"): # 查找符合要求的字符串 36 for p in item.p.children: 37 f.writelines(p.string.replace(u'\xa0', '')) 38 39 40 # 爬取指定URL网页信息 41 def askURL(url): 42 #包装request请求头 43 head = { 44 "User-Agent": "Mozilla / 5.0 AppleWebKit " #... 45 } 46 request = urllib.request.Request(url, headers=head) 47 #保存爬取到的网页 48 html = "" 49 try: 50 response = urllib.request.urlopen(request) 51 html = response.read().decode("utf-8") 52 #print(html) 53 #异常处理 54 except urllib.error.URLError as e: 55 if hasattr(e, "code"): 56 print(e.code) 57 if hasattr(e, "reason"): 58 print(e.reason) 59 return html 60 61 62 if __name__ == "__main__": 63 main() 64 print("爬取完毕")
1 # -*- coding = UTF-8 -*- 2 # @Time : 2022/01/03 13:39 3 # @Author : butupi 4 # @File : to_wordcloud.py 5 # @Software : PyCharm 6 7 import jieba # 分词 8 from matplotlib import pyplot as plt # 绘图 数据可视化 9 from wordcloud import WordCloud # 词云 10 from PIL import Image # 图片处理 11 import numpy as np # 矩阵运算 12 13 14 #--------------------------------- 15 #获取中英文文章 16 def get_text(path_en, path_zh): 17 text_en = "" 18 text_zh = "" 19 with open(path_en, "r", encoding="utf-8") as f: 20 for line in f.readlines(): 21 text_en += line.rstrip("\n") 22 # print(text_en) 23 with open(path_zh, "r", encoding="utf-8") as f: 24 for line in f.readlines(): 25 text_zh += line.rstrip("\n") 26 return text_en, text_zh 27 28 #--------------------------------- 29 30 #jieba分词 31 def cut_text(text): 32 cut = jieba.cut(text) 33 cut_words = ' '.join(cut) 34 # print(type(cut_words)) 35 # print(len(cut_words)) 36 return cut_words 37 38 #--------------------------------- 39 #得到停用词列表 40 def get_stop_words(filepath): 41 stop_words = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()] 42 return stop_words 43 44 #去除停用词 45 def move_stop_words(text, path): 46 stop_words = get_stop_words(path) 47 out_str = '' 48 for word in text: 49 if word not in stop_words: 50 if word != '\t' and '\n': 51 out_str += word 52 return out_str 53 #----------------------------------- 54 55 #生成词云 56 def get_word_cloud(source_path, dest_path, out_str): 57 #得到背景图片 58 img = Image.open(source_path) 59 #将图片转换为数组 60 img_array = np.array(img) 61 #词云属性 62 wc = WordCloud( 63 background_color='white', 64 mask=img_array, 65 font_path="msyh.ttc" # font 66 ).generate_from_text(out_str) 67 68 #绘制图片 69 fig = plt.figure(1) 70 plt.imshow(wc) # 以词云的方式显示 71 plt.axis('off') # 不显示坐标 72 #plt.show() # 显示生成的词云图片 73 #输出为文件 74 plt.savefig(dest_path, dpi=500) 75 76 #------------------------------- 77 def main(): 78 #get_text 79 text_en, text_zh = get_text("wbfx.txt", "简爱.txt") 80 81 #jieba 82 cut_words = cut_text(text_zh) 83 84 #move_stop_words 85 out_str = move_stop_words(cut_words, 'stop_word.txt') 86 87 #wordcloud 88 get_word_cloud('zh-tree.jpg', 'zh-tree-out.jpg', out_str) 89 get_word_cloud('en-bj.png', 'en-bj-out.png', text_en) 90 91 92 #--------------------------------- 93 if __name__ == '__main__': 94 main()
1 # -*- coding = utf-8 -*- 2 # @Time : 2022/01/03 20:45 3 # @Author : butupi 4 # @File : word_frequency.py 5 # @Software : PyCharm 6 7 import xlwt # EXCEL处理 8 9 #获取英文文章(替换特殊字符) 10 def get_text(path_en): 11 text_en = "" 12 with open(path_en, "r", encoding="utf-8") as f: 13 for line in f.readlines(): 14 text_en += line.rstrip("\n") 15 #小写 16 text_en = text_en.lower() 17 #替换特殊字符 18 for ch in '!"#$&()*+,-./:;<=>?@[\\]^_{|}·~\'‘’': 19 text_en = text_en.replace(ch, " ") 20 return text_en 21 22 23 #处理文本存入字典 24 def make_dictionary(text_en): 25 words = text_en.split() 26 dictionary = {} 27 for word in words: 28 dictionary[word] = dictionary.get(word, 0) + 1 # counts.get (word,0)+ 1 是指有word时返回其值,默认是0,+1能够累计次数;没有word时则返回0。 29 return dictionary 30 31 #排序 32 def sort_dir(dictionary): 33 items = list(dictionary.items()) 34 items.sort(key=lambda x: x[1], 35 reverse=True) # lambda x:x[0]给列表中元组 的(key)给sort排序,x:x[1]代表字典的值(values)给sort排序,reverse=true表示降序 36 return items 37 38 #得到 length个及以上的字母的单词个数 39 def get_count_len(items, length: int): 40 count_len_more = 0 41 count_text = 0 # 此单词数 42 for word, count in items: 43 count_text += count 44 if len(word) >= length: 45 count_len_more += count 46 return count_len_more, count_text 47 48 #保存到EXCEL表格中 49 def save_sheet(path, items): 50 workbook = xlwt.Workbook(encoding="utf-8") 51 worksheet = workbook.add_sheet("word_frequency") 52 worksheet.write(0, 0, "单词") 53 worksheet.write(0, 1, "出现次数") 54 for i in range(0, len(items)): 55 worksheet.write(i+1, 0, items[i][0]) 56 worksheet.write(i+1, 1, items[i][1]) 57 workbook.save(path) 58 59 #统计单词、词频 60 def main(): 61 text_en = get_text("wbfx.txt") 62 63 #对处理后的文本进行词频统计存入字典 64 dictionary = make_dictionary(text_en) 65 66 #将字典降序排列,得到列表,元素为(k-v)元组(单词,频次) 67 items = sort_dir(dictionary) 68 69 #统计结果存为列表类型,按词频由高到低进行排序,输出前15位 70 print("简爱英文小说 Jane Eyre 词频前15排行") 71 for i in range(15): 72 word, count = items[i] 73 print("{0}\t\t{1:<8}{2:>5}".format(i+1, word, count)) 74 75 #保存到Excel表格中 76 save_sheet("word_frequency.xls", items) 77 78 #6个字母长度及以上的单词个数 79 length_word = 6 80 count_six_more, count_text = get_count_len(items, length_word) 81 #print(word, count) # 6个字母+的单词及其频次 82 print() 83 print("简爱小说英文文本中"+str(length_word)+"个及以上的字母的单词个数有:\t"+str(count_six_more)+" 个") 84 print("简爱小说英文Jane-Eyre文本总共有单词个数有:\t"+str(count_text)+" 个") 85 86 87 if __name__ == '__main__': 88 main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号