

编译原理实验 —— 四则运算的词法、语法、语义分析实现
实验目的与意义
本次实验的核心目标,是构建一个能对简单程序设计语言子集进行词法、语法和语义分析的程序,聚焦于四则运算表达式。通过亲手实践,我期望能深入理解编译系统的底层运作机制,验证课堂上学到的理论知识,同时提升自己的编程、算法运用和问题解决能力。附完整文档下载。
实验设计与实现:搭建编译功能模块
整个实验我采用模块化设计理念,将编译流程清晰地划分为词法分析、语法分析和语义分析三个关键模块,它们相互协作,共同完成从源程序到中间代码的转换。
词法分析
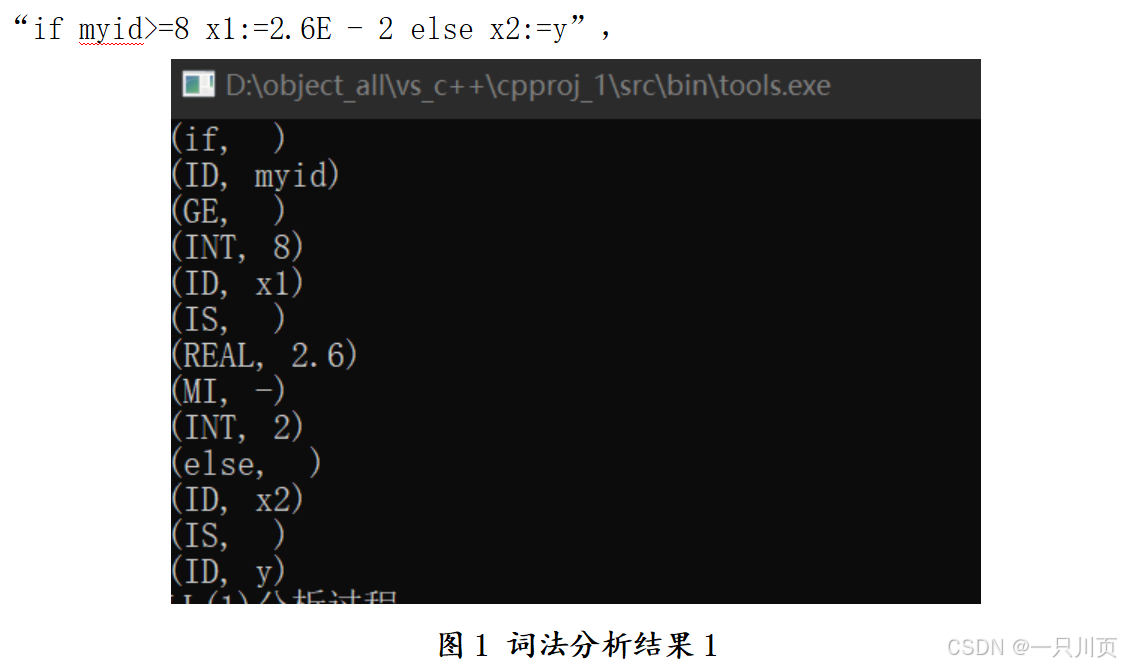
词法分析模块就像程序的 “眼睛”,负责从源程序中精准识别各类单词。我依据有限自动机理论,手工绘制状态转换图来实现这一功能。先为每类单词,像关键字、标识符、整型与实型常数、各类运算符等,分别构建状态转换图,再合并成统一的状态图,并进行确定化和最小化处理,最后添加语义动作,成功打造出词法分析程序。
包含 20 类单词的分类码表,为单词识别提供了明确依据。例如,当扫描到字母开头的字符序列时,程序会进入标识符识别状态,持续拼接后续的字母或数字字符,直到遇到非字母数字字符,然后通过查询保留字表,判断它究竟是关键字还是普通标识符。
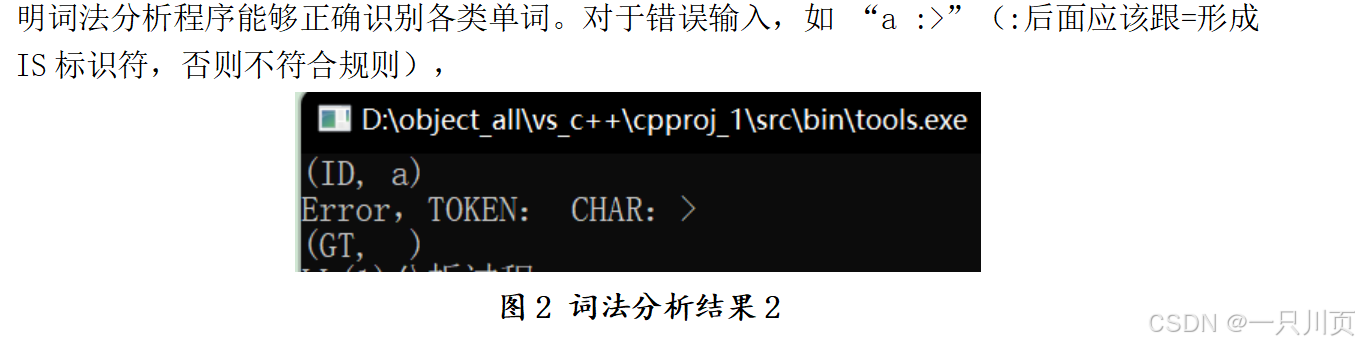
在代码实现上,词法分析程序由主函数和多个辅助函数组成。主函数统筹协调,负责读取源程序文件并调用其他函数进行单词识别。scanner 函数是识别单词的核心,它借助 isalpha、isalnum、isdigit 等库函数判断字符类型,进而进入相应的识别逻辑。digit_scanner 函数则专注于处理数字,无论是整数、小数还是科学计数法表示的数字,都能准确识别并转换为对应字符串输出。lookup 函数用于查找关键字,out 函数负责输出单词的二元式,report_error 函数在遇到不符合规则的字符串时,输出详细的错误提示信息,包括错误字符和所在行号。在数据结构选择上,字符数组 TOKEN 临时存储单词词文,结构体 WORD 表示单词二元式。
语法分析
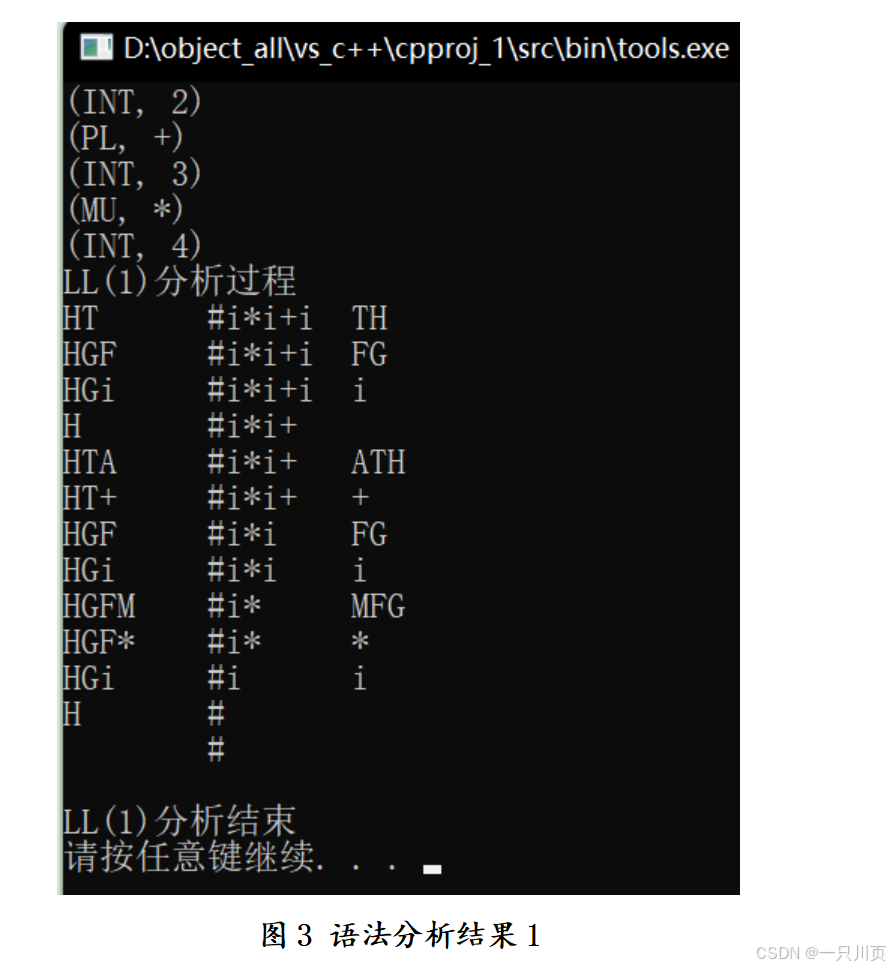
语法分析模块运用 LL (1) 分析法,对输入的单词序列进行语法结构检查。LL (1) 分析法基于预测分析技术,关键在于构造预测分析表。首先,我用 BNF 形式定义了算术表达式的文法,像 < 算术表达式 > → < 项 > | < 算术表达式 >+< 项 > | < 算术表达式 >-< 项 > 等规则。接着,消除文法中的左递归,计算各个非终结符的 FIRST 集和 FOLLOW 集,只有当文法满足 LL (1) 条件时,才构建预测分析表。在分析过程中,程序会根据当前输入单词和栈顶符号,查询预测分析表来决定是移进、归约还是接受操作。
语法分析程序包含多个功能各异的函数。LL_run 函数作为主控制函数,负责从输入串读取单词,依据栈顶符号和输入单词查询预测分析表,执行相应动作,在归约时还会调用 GEN 函数生成四元式。transfer_int 函数将字符形式的符号转换为整数编码,方便在分析表中查询。wait_temp 函数根据不同语法情况处理括号匹配、生成四元式等任务。getwords 函数从词法分析的输出文件读取单词序列,填充到输入串堆栈,为语法分析做好准备。程序借助多个数组和栈结构,如终结符栈 S_stack、非终结符栈 E_stack、存放运算符的 op 数组、存储操作数的 arg 数组、生成临时变量名的 tp 数组以及存储输入单词序列的 Input 数组,协同完成语法结构分析和四元式生成工作。对于符合文法规则的输入,程序会输出 “RIGHT” 并展示详细的分析过程,包括每一步的推导步骤和栈的变化;若输入存在语法错误,程序则输出 “ERROR”,同时显示中间结果、错误位置和性质。
语义分析
语义分析基于语法制导翻译原理,在语法分析的过程中巧妙嵌入语义动作。我对算术表达式文法进行扩展,为每个产生式配备对应的语义子程序。在语法分析执行表达式求值的归约操作时,根据预先设定的语义规则,插入生成四元式的动作。例如,对于加法运算,会生成(“+”,操作数 1,操作数 2,结果)形式的四元式,其中操作数从语法分析识别的表达式子部分获取,结果则是通过 temp_get 函数生成的临时变量。
语义分析功能集成在语法分析程序中,主要通过 GEN 函数实现四元式的生成。结构体 Qtne 用来表示四元式,包含操作符、操作数和结果等字段。程序运行时,四元式表(通过结构体数组实现)会依次存储生成的四元式序列。例如,输入 “2 + 3 * 4”,语义分析程序会生成(“*”,“3”,“4”,“T1”),(“+”,“2”,“T1”,“T2”)这样符合计算逻辑的四元式序列。对于存在语义错误的情况,虽然本实验简化处理,但预留了扩展接口,能与语法分析协同工作,在检测到语法错误时一并给出错误提示,确保中间代码语义正确。
程序代码剖析
代码按照功能模块进行组织,清晰划分词法分析、语法分析和语义分析相关部分。在文件结构上,LE.h 声明词法分析的函数和数据结构,LE.txt 实现词法分析功能,LL.h 则承担语法分析和语义分析功能。每个文件内函数的定义和实现逻辑紧密围绕功能展开,并且添加了丰富的注释,涵盖函数功能、算法原理、变量含义等内容,方便理解。
词法分析代码里,scanner 函数利用库函数判断字符类型,引导单词识别流程;digit_scanner 函数凭借复杂的状态机逻辑处理各种数字格式。语法分析代码中,LL_run 函数依据预测分析表驱动分析过程,GEN 函数负责生成四元式结构体并存储。语义分析代码主要体现在 GEN 函数和语义动作触发点上,wait_temp 函数的部分逻辑也为生成正确四元式提供支持。
实验结果与分析
实验结果令人满意。词法分析程序能精准识别正确输入中的各类单词,输出对应的二元式;遇到错误输入时,也能准确指出错误。语法分析程序对正确语法结构的表达式能顺利分析并展示过程,对错误表达式能精准定位错误。语义分析程序则能将算术表达式正确转换为四元式序列,实现了语义的正确处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号