SPP-Net、Atrous Convolution以及ASPP
一、简介
- SPP-Net是出自2015年发表在IEEE上的论文-《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》。在此之前,所有的神经网络都是需要输入固定尺寸的图片,比如224×224(ImageNet)、32×32(LenNet)、96×96等。这样对于我们希望检测各种大小的图片的时候,需要经过crop,或者warp等一系列操作,这都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。而且,从生理学角度出发,人眼看到一个图片时,大脑会首先认为这是一个整体,而不会进行crop和warp,所以更有可能的是,我们的大脑通过搜集一些浅层的信息,在更深层才识别出这些任意形状的目标。
- ASPP是出自2016年发表在IEEE上的论文-《DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》。ASPP(Atrous Spatial Pyramid Pooling)是DeepLab中用于语义分割的一个模块。由于被检测物体具有不同的尺度,给分割增加了难度。一种方法是通过rescale图片,分别经过DCNN(Deep Convolutional Neural Network)检测,然后融合,但这种方法计算量大。DeepLab就设计了一个ASPP的模块,既能得到多尺度信息,计算量又比较小,其中还使用了空洞卷积(Atrous Convolution)的方法
二、参考文献
-
Chen L C , Papandreou G , Kokkinos I , et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 40(4):834-848.
-
Chen L C , Papandreou G , Kokkinos I , et al. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 40(4):834-848.
博客:
- SPP-Net论文详解https://blog.csdn.net/v1_vivian/article/details/73275259
- 空洞卷积和感受野https://www.cnblogs.com/houjun/p/10275215.html
- 空洞卷积理解https://www.jianshu.com/p/f743bd9041b3
- 转置卷积https://blog.csdn.net/LoseInVain/article/details/81098502
三、模块详解
1.SPP-Net
主要内容
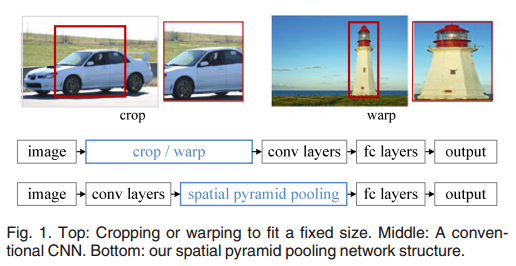
为了固定尺寸的输入,裁剪和拉伸都会对物体造成或多多少的失真。
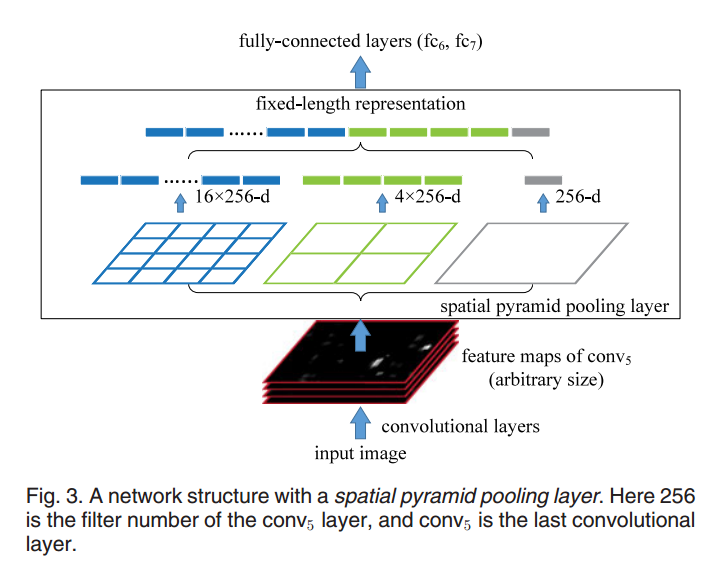
黑色图片代表卷积之后的特征图,接着我们以不同大小的块来提取特征,分别是4×4,2×2,1×1,将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的块(Spatial bins),我们从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。这种以不同的大小格子的组合方式来池化的过程就是空间金字塔池化(SPP)。比如,要进行空间金字塔最大池化,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出单元,最终得到一个21维特征的输出。这样对于不同的输入总能得到需要的特征数量,而不用固定卷积层的输入尺寸。
测试结果

2.ASPP
Atrous/Dilated Convolution
在介绍ASPP之前,首先要介绍Atrous Convolution(空洞卷积)。和之前的non-local一样,都是为了增加感受野的方法。空洞卷积是是为了解决基于FCN思想的语义分割中,输出图像的size要求和输入图像的size一致而需要upsample,但由于FCN中使用pooling操作来增大感受野同时降低分辨率,导致upsample无法还原由于pooling导致的一些细节信息的损失的问题而提出的。为了减小这种损失,自然需要移除pooling层,因此空洞卷积应运而生。
先看标准卷积,stride=2,padding=1,得到7×7的感受野
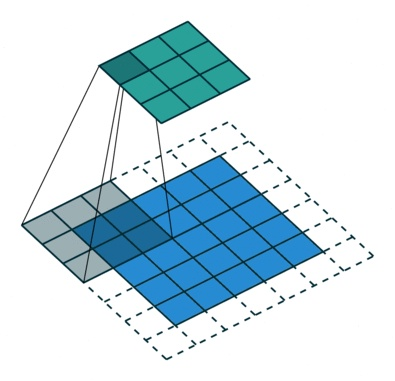
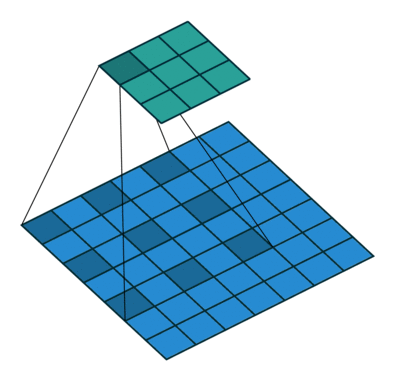
再看空洞卷积,stride=1,padding=0,得到7×7的感受野
空洞卷积核
(a) 普通卷积,1-dilated convolution,卷积核的感受野为3x3
(b) 扩张卷积,2-dilated convolution,卷积核的感受野为7x7
(c) 扩张卷积,4-dilated convolution,卷积核的感受野为15x15
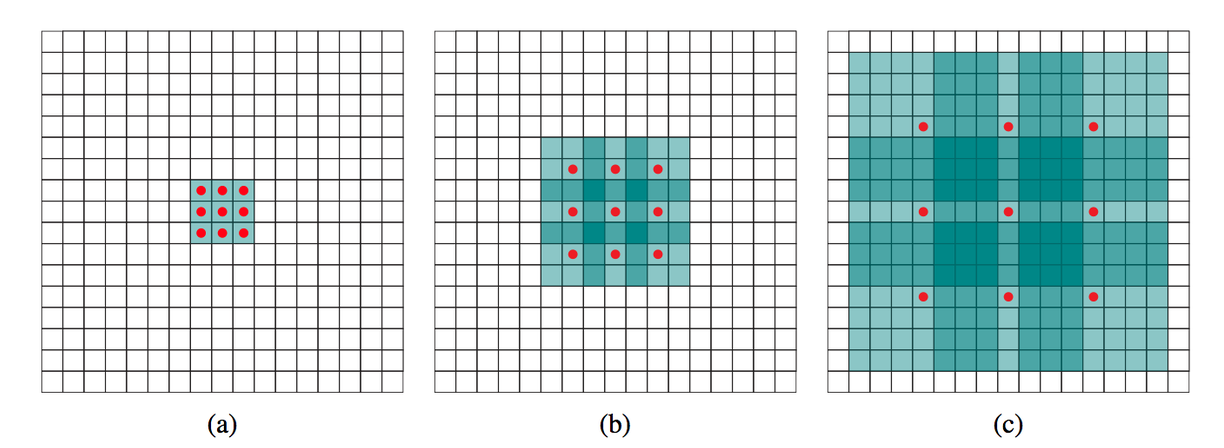
计算公式(空洞卷积dilated rate = n)
而对于标准卷积,需要级联三个3×3的卷积核(计算公式为:(ksize-1)*layers + 1)
空洞卷积的问题
- The Gridding Effect
多次叠加dilation rate=2的3×3kernel,则会出现这个问题:
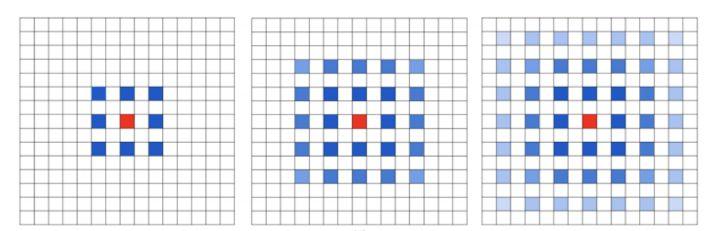
并不是所有的pixel都用来计算,这对 pixel-level dense prediction的任务来说是致命的。
- Long-ranged information might be not relevant
光采用大 dilation rate 的信息或许只对一些大物体分割有效果,而对小物体来说可能则有弊无利了。
解决办法参见Hybrid Dilated Convolution (HDC) .
ASPP
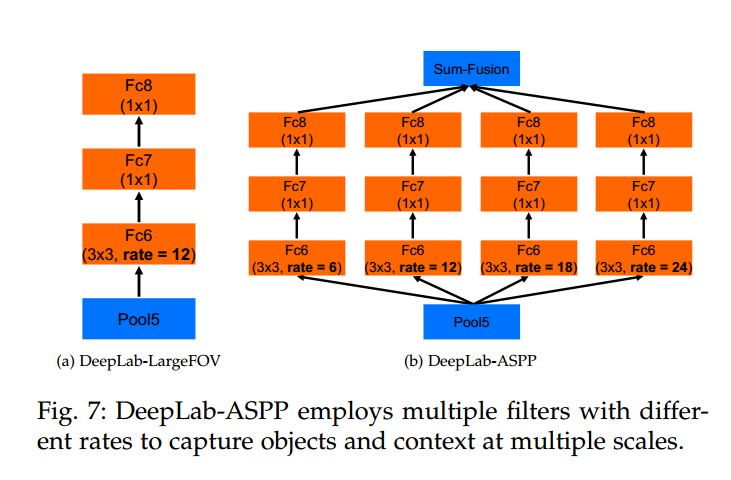
论文中说:这种方法受到了R-CNN空间金字塔池方法的成功启发,该方法表明,通过对单个尺度提取的卷积特征进行重采样,可以对任意尺度的区域进行准确有效的分类。我们已经实现了他们的方案的一个变种,该方案使用具有不同采样率的多个并行atrous convolutional layers。为每个采样率提取的特征在单独的分支中进一步处理,并融合以生成最终结果。提出的“atrous spatial pyramid pooling池”(DeepLab-ASPP)方法概括了我们的DeepLab-LargeFov变量,如下图所示。
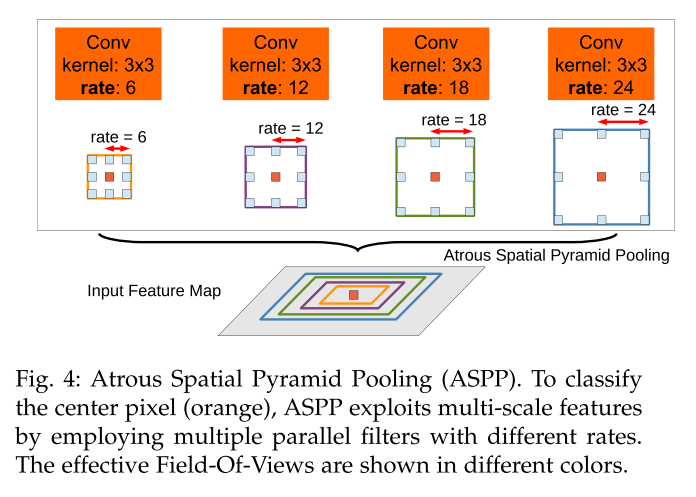
部分网络结构图:
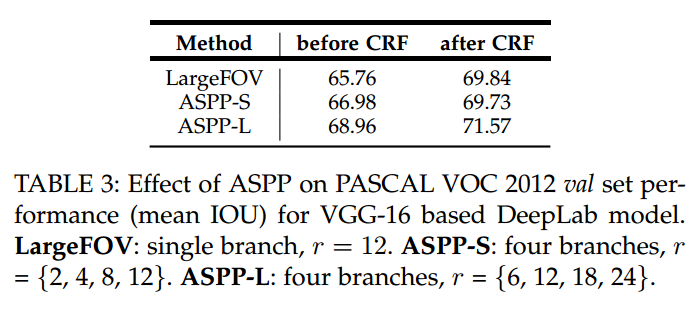
使用和不使用ASPP以及使用不同dilated rates的ASPP的结果:
3.atrous/dilated convolution和deconvolution/transposed convolution
deconvolution(反卷积)为避免和数字信号处理的反卷积混淆,所以用tranposed convolution(转置卷积)来代替。
使用场景:
- 在DCGAN中的生成器将会用随机值转变为一个全尺寸(full-size)的图片,这个时候就需要用到转置卷积。
- 在语义分割中,会使用卷积层在编码器中进行特征提取,然后在解码层中进行恢复为原先的尺寸,这样才可以对原来图像的每个像素都进行分类。这个过程同样需要用到转置卷积
具体原理为将卷积操作转化为一个矩阵,要恢复更上一级的feature map就用当前的feature map乘以这个矩阵的转置。需要注意的是:这里的转置卷积矩阵的参数,不一定从原始的卷积矩阵中简单转置得到的,转置这个操作只是提供了转置卷积矩阵的形状而已。具体内容参见博客。
四、待改进
- ASPP是并行结构,如果将空洞卷积串行起来?
- 空洞卷积的rate需要特别设置,如果将non-local方法运用进来会怎样?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号