
数据采集与融合技术第四次作业
数据采集与融合技术第四次作业
• 作业①:
o 要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
▪ 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。
o 候选网站:东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
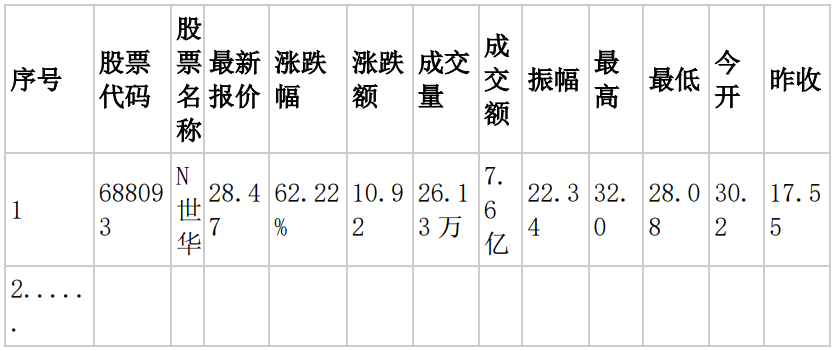
o 输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号
id,股票代码:bStockNo……,由同学们自行定义设计表头:
代码部分
爬取网站:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
step1:配置edge浏览器selenium
点击查看代码
edge_options = Options()
edge_options.add_argument("--start-maximized") # 启动时最大化窗口(避免元素遮挡)
edge_options.add_argument("--ignore-certificate-errors") # 忽略证书错误
edge_options.add_experimental_option("excludeSwitches", ["enable-automation"]) # 隐藏自动化提示(部分网站会屏蔽自动化工具)
# 配置 Edge 驱动服务(确保路径正确,新版 Edge 驱动名为 msedgedriver.exe)
edge_service = Service(executable_path=r"H:/MicrosoftWebDriver.exe")
# 初始化 Edge 浏览器(传入选项)
browser = webdriver.Edge(service=edge_service, options=edge_options)
driver = browser # 使用 driver 作为别名,保持代码一致性
step3:定义mysql数据库类
点击查看代码
class StockDB:
# 打开数据库连接并创建表格
def openDB(self):
# 连接到MySQL数据库
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="你的密码", db="crawl",
charset="utf8")
# 创建一个游标,使用字典游标以便返回字典格式的数据
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 创建一个名为stocks2的表,包含多个字段
self.cursor.execute(
"create table stocks2(no int,code varchar(32),name varchar(32),zxj varchar(32),zdf varchar(32),zde varchar(32),"
"cjl varchar(32),zf varchar(32),zg varchar(32),zd varchar(32),jk varchar(32),zs varchar(32))")
except:
# 如果表已存在,则清空表中的所有数据
self.cursor.execute("delete from stocks2")
# 关闭数据库连接并提交更改
def closeDB(self):
# 提交当前事务
self.con.commit()
# 关闭数据库连接
self.con.close()
# 向数据库插入一条记录
def insert(self, no, code, name, zxj, zdf, zde, cjl, zf, zg, zd, jk, zs):
try:
# 插入数据到stocks2表
self.cursor.execute(
"insert into stocks2(no,code,name,zxj,zdf,zde,cjl,zf,zg,zd,jk,zs) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,"
"%s,%s,%s)",
(no, code, name, zxj, zdf, zde, cjl, zf, zg, zd, jk, zs))
except Exception as err:
# 捕捉并打印错误
print(err)
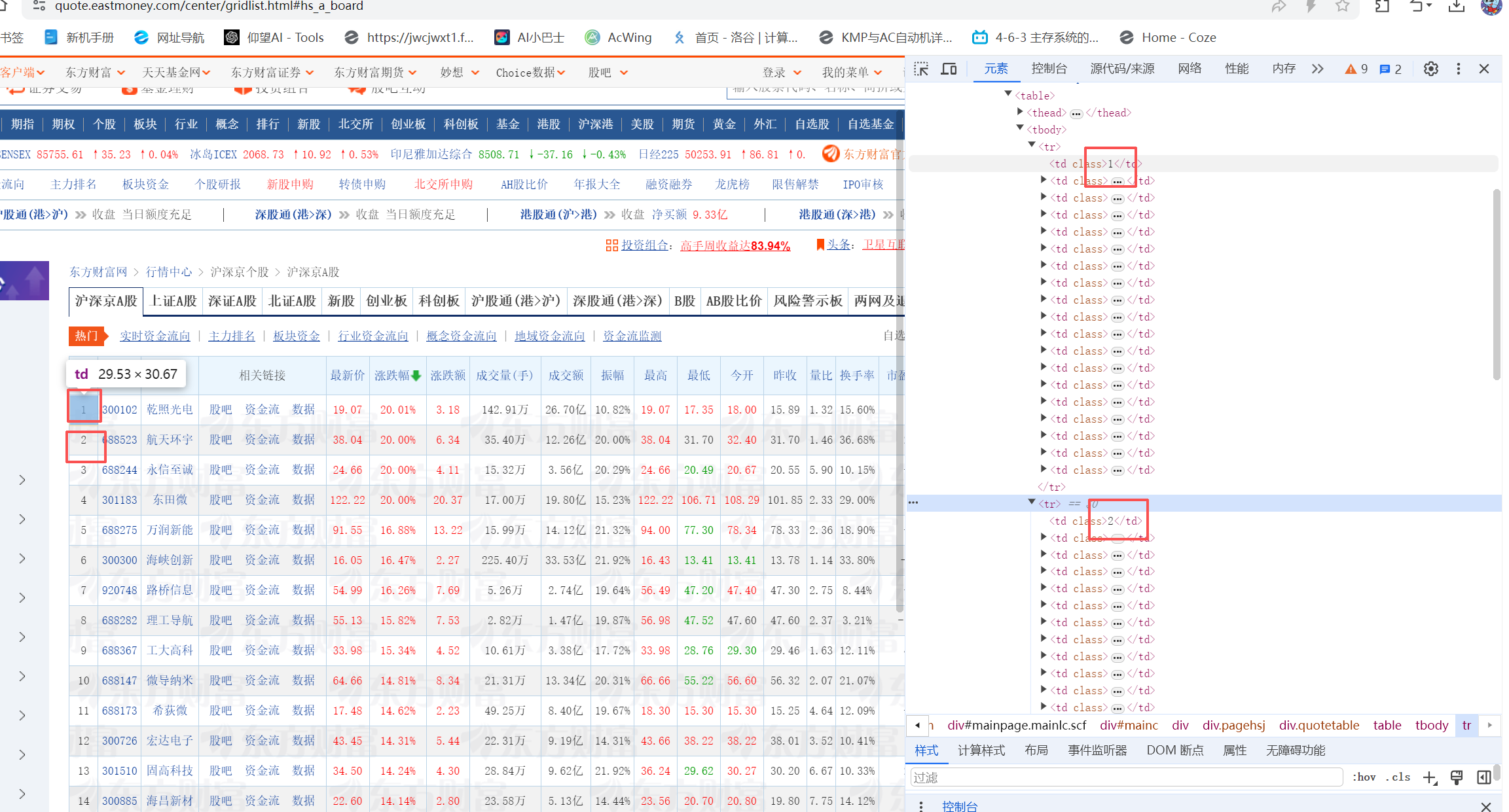
观察上图可知,每个股票信息存在tagname为td的块中,,所以我们可以先找寻td然后获取完所有td后根据实际列表提取对应数据
具体实现方式如下
点击查看代码
def stockinfo():
# 等待页面加载
print("等待页面加载...")
time.sleep(5)
# 尝试多种可能的表格选择器
try:
# 尝试原始选择器
items = driver.find_elements(By.XPATH, "//table[@id='table_wrapper-table']//tbody/tr")
if not items:
# 尝试其他可能的选择器
print("尝试备用选择器...")
items = driver.find_elements(By.XPATH, "//table//tbody/tr")
if not items:
# 如果还是找不到,打印页面源码的一部分用于调试
print("未找到表格元素,打印页面标题:")
print(driver.title)
# 尝试查找所有表格
tables = driver.find_elements(By.TAG_NAME, "table")
print(f"页面中找到 {len(tables)} 个表格元素")
if tables:
# 使用第一个表格
items = tables[0].find_elements(By.XPATH, ".//tbody/tr")
if not items:
raise Exception("无法找到股票数据表格")
except Exception as e:
print(f"查找表格时出错: {e}")
raise
print(f"找到 {len(items)} 条股票记录")
# 先检查第一行的结构
if items:
first_row = items[0]
tds = first_row.find_elements(By.TAG_NAME, "td")
print(f"每行有 {len(tds)} 个td元素")
if len(tds) > 0:
print("前几列的内容:")
点击查看代码
for i, td in enumerate(tds[:min(15, len(tds))], 1):
print(f" 列{i}: {td.text[:30] if td.text else '(空)'}")
for item in items:
try:
# 获取所有td元素
tds = item.find_elements(By.TAG_NAME, "td")
# 根据实际列数提取数据(需要根据上面的输出调整)
if len(tds) >= 14:
no = tds[0].text
code = tds[1].text
name = tds[2].text
zxj = tds[4].text # 最新价
zdf = tds[5].text # 涨跌幅
zde = tds[6].text # 涨跌额
cjl = tds[7].text # 成交量
zf = tds[9].text # 振幅
zg = tds[10].text # 最高
zd = tds[11].text # 最低
jk = tds[12].text # 今开
zs = tds[13].text # 昨收
print("{:<5}{:<10}{:<12}{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}{:<8}{:<8}{:<8}".format(
no, code, name, zxj, zdf, zde, cjl, zf, zg, zd, jk, zs))
# 将提取的股票信息插入数据库``
db.insert(no, code, name, zxj, zdf, zde, cjl, zf, zg, zd, jk, zs)
else:
print(f"跳过行(列数不足): {tds[0].text if tds else '未知'}")
except Exception as e:
print(f"处理行时出错: {e}")
continue
# 等待1.5秒
time.sleep(1.5)
step5:处理反爬取机制
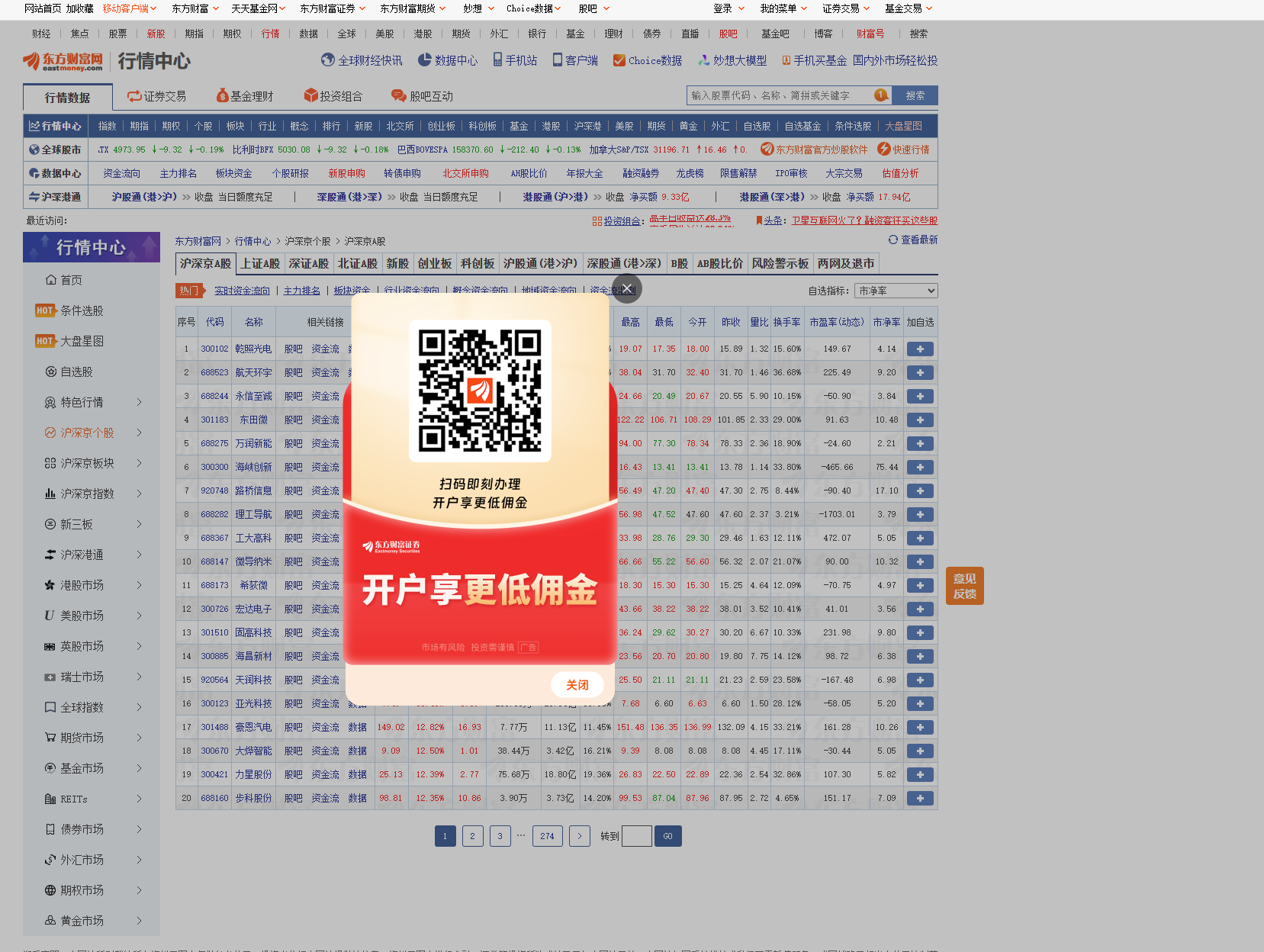
可以看到,我们直接用selenium爬取时他会广告弹出,很显然我们就爬不到我们想要的数据,事实上在这里我们可以设计一个透明化该弹窗的设计,但是我这里为了是代码更简单易理解,使用了最简单的睡眠方式,也就是引入time,在页面加载时sleep5秒,然后我们手动关闭该弹窗
点击查看代码
driver.get("http://quote.eastmoney.com/center/gridlist.html#hs_a_board")
# 等待页面完全加载
time.sleep(5)
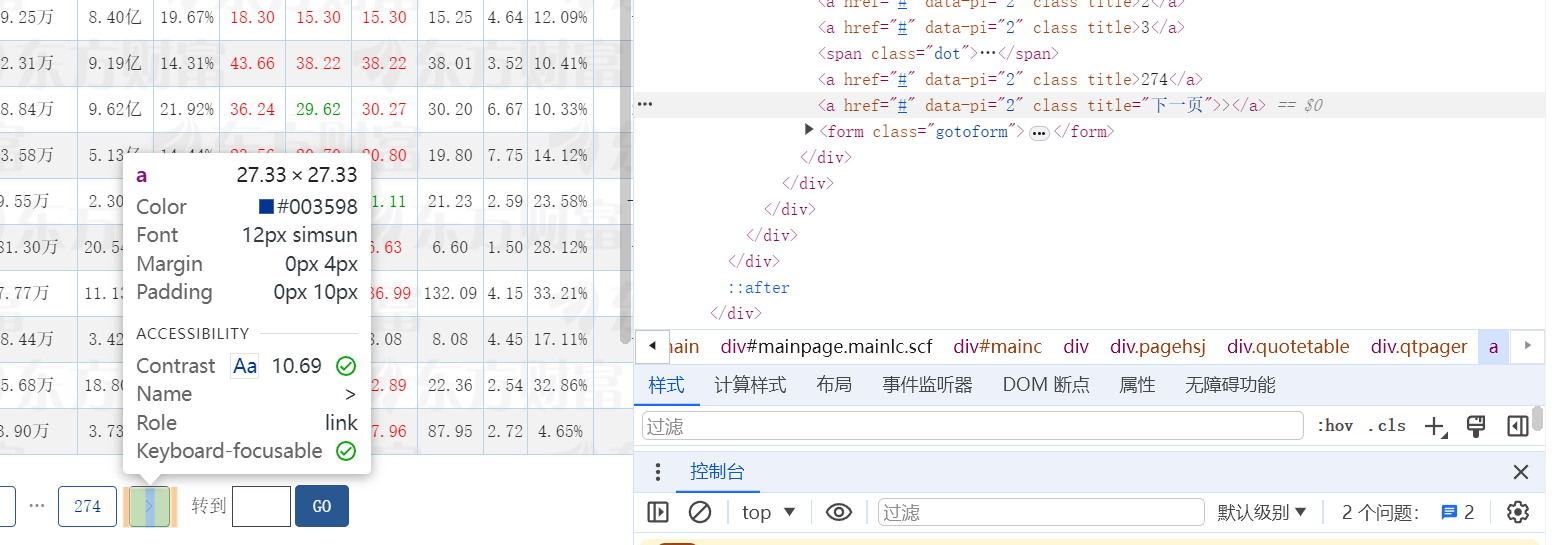
如图找到了下一页按钮位置,我们根据图中它的类型找到位置后,利用click原生点击函数定位点击即可实现跳转
点击查看代码
try:
# 等待下一页按钮出现
nextpage = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//a[@data-pi="2"]'))
)
# 滚动到按钮位置
driver.execute_script("arguments[0].scrollIntoView(true);", nextpage)
time.sleep(1)
# 点击按钮
driver.execute_script("arguments[0].click();", nextpage)
print("已点击下一页按钮")
# 等待页面加载
time.sleep(3)
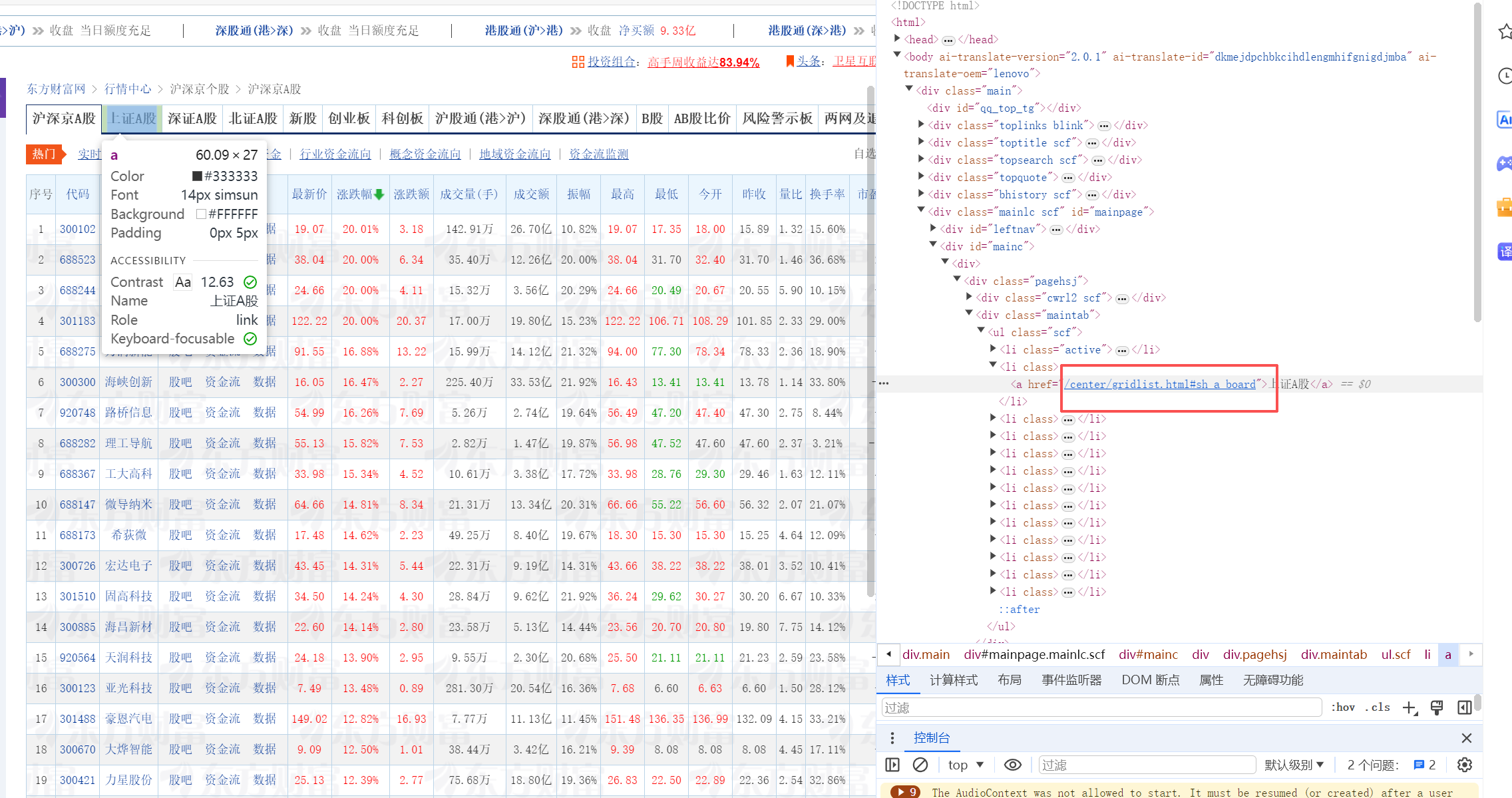
一开始我以为股票这个不是一个可以交互的按钮,所以我做这题的时候就采用了根据href爬取这个股票对应链接,爬取完后driver过去访问这个链接从而实现跳转,其实这里也可以设计成click的方式即根据类型定位点击,不过效果一样就没做修改,这里只做口头方式补充
点击查看代码
# 获取上证A股链接
try:
print("\n=== 开始抓取上证A股数据 ===")
shzag = driver.find_element(By.XPATH, "//a[@href='/center/gridlist.html#sh_a_board']").get_attribute("href")
print(f"上证A股链接: {shzag}")
# 访问上证A股链接
driver.get(shzag)
# 等待页面加载
time.sleep(5)
# 再次调用stock函数处理股票页面
stock()
except Exception as e:
print(f"抓取上证A股时出错: {e}")
# 获取深证A股链接
try:
print("\n=== 开始抓取深证A股数据 ===")
szag = driver.find_element(By.XPATH, "//a[@href='/center/gridlist.html#sz_a_board']").get_attribute("href")
print(f"深证A股链接: {szag}")
# 访问深证A股链接
driver.get(szag)
# 等待页面加载
time.sleep(5)
# 再次调用stock函数处理股票页面
stock()
运行结果
表头统一输出

终端部分展示
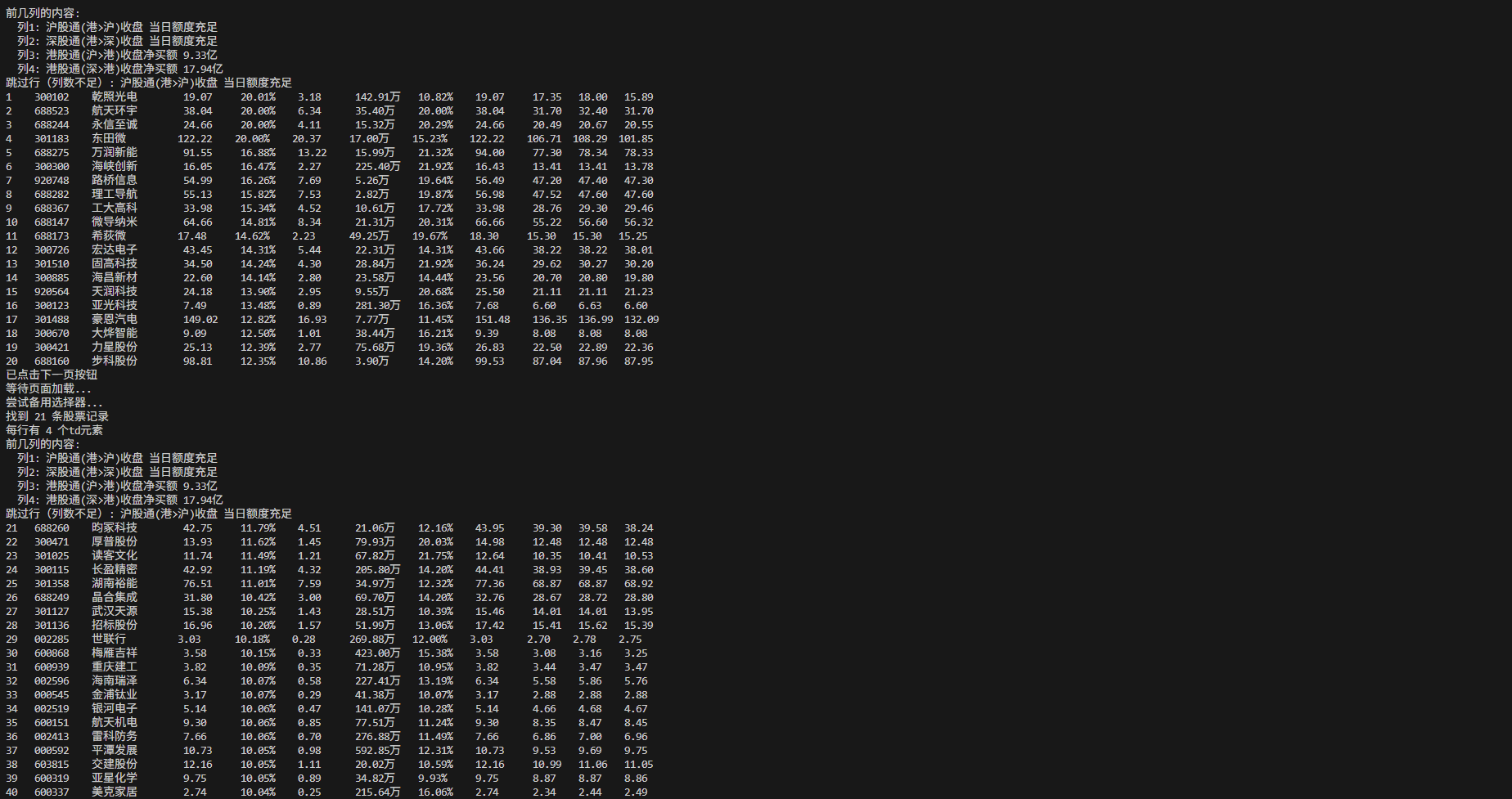
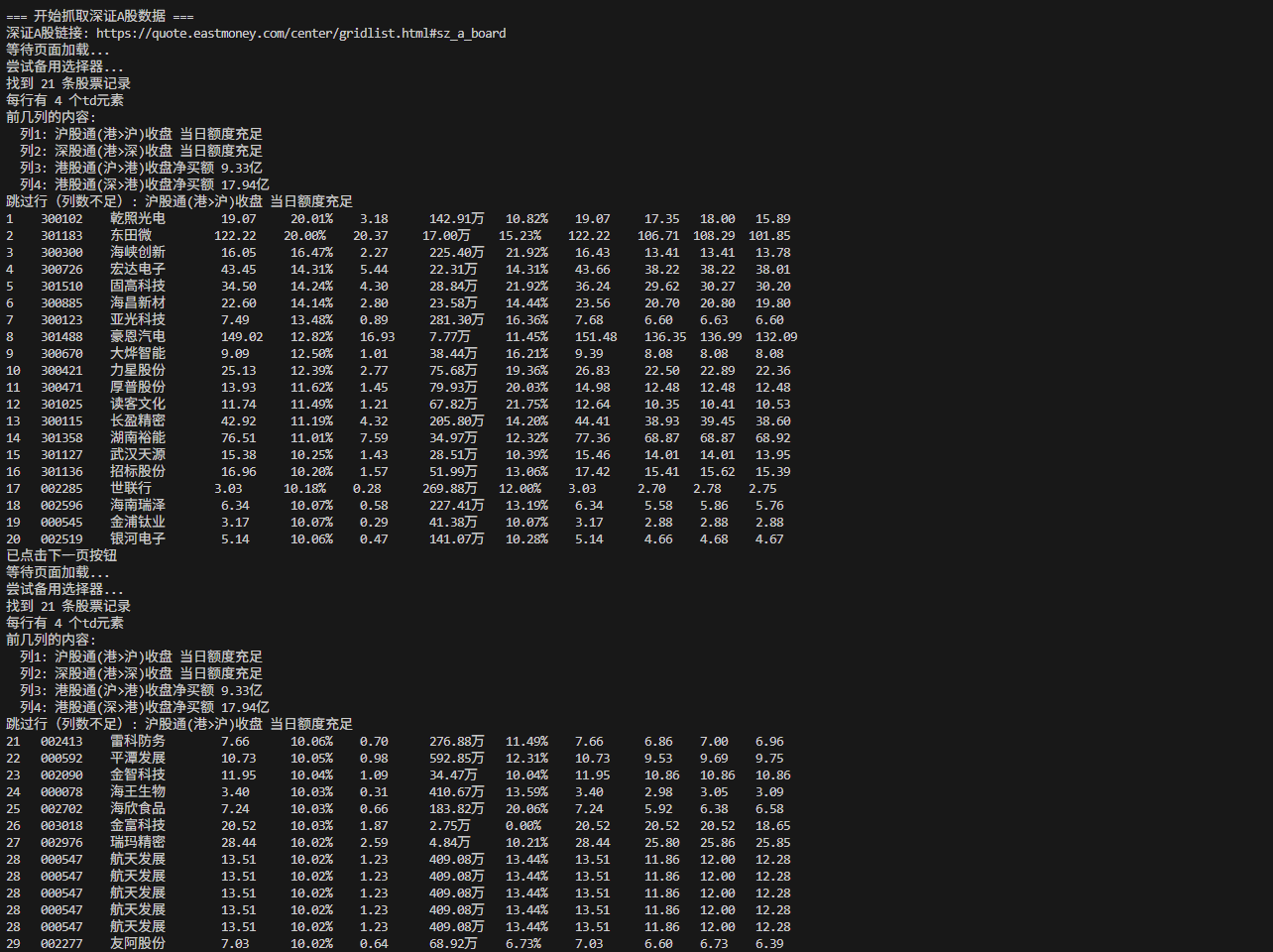
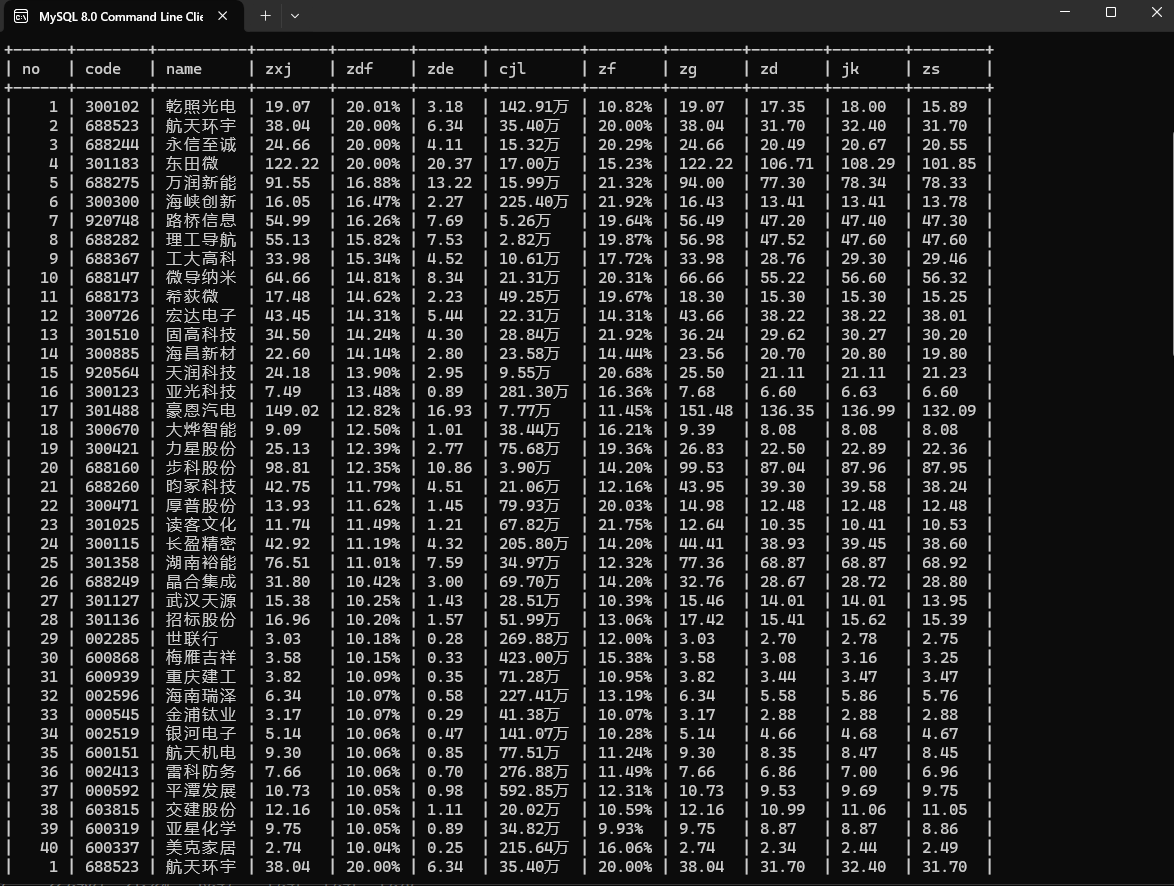
数据库结果部分展示
心得体会
本次基于Selenium和MySQL的股票信息爬取项目中,我掌握了动态网页数据抓取与数据库存储的核心流程。针对目标网页动态加载的特点,我采用隐式等待结合time.sleep()的方式确保页面数据完整加载(因网站无合适标识,未使用显式等待),通过XPath定位并提取股票代码、名称、价格、涨跌幅等字段,以字典形式规整数据。
数据爬取环节,我通过xpath定位然后点击或者跳转实现了自动翻页以及跳转股票板块功能
数据存储环节,我借助pymysql库实现MySQL交互,先创建对应数据表,再将抓取数据批量插入,同时添加异常处理机制,避免分页操作、元素定位或数据库交互出错导致程序崩溃。
项目仍有优化空间:time.sleep()强制等待效率有限,后续可探索更精准的加载控制方案;面对海量数据,可通过并发爬取、数据库连接池等技术提升速度与存储效率。
此次实践让我深入掌握了Selenium和MySQL的应用,深刻体会到动态加载、反爬虫应对等爬虫开发中的关键挑战,积累了实用的排错与数据处理经验,为后续优化爬虫性能打下了基础。
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
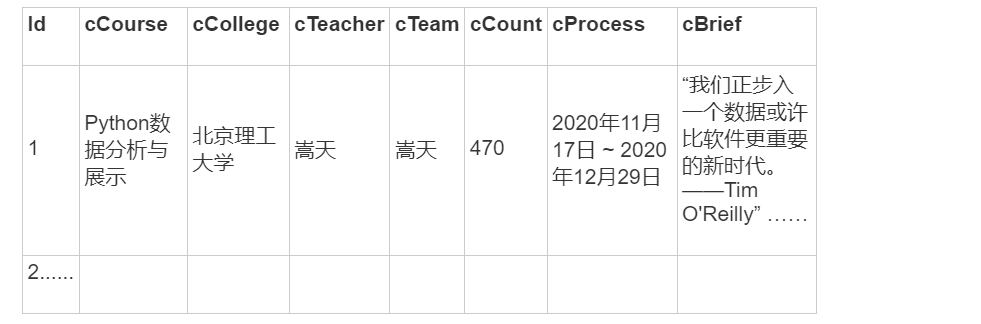
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
输出格式:
代码部分
step1:设计整体思路,我们进入网页自动登录,然后自动搜索关键词爬取相关课程信息,同时设计自动翻页功能实现爬取多页数 据
step2:处理反爬取机制
这个是页面刚进入时就会出现,但是任意点击空白处就会消失,所以实际后面发现因为我需要点击搜索框他有没有阻挡我需要交互的位置,所以无伤大雅不用管就能爬取,我一开始设想的也是进入该页面时先sleep几秒然后用原生点击click功能实现解决这个反爬取
这个是在用户登录结束后会出现的弹窗我设计如下代码进行处理根据xpath定位同意按钮即可
点击查看代码
WebDriverWait(self.driver, 10, 0.5).until(
EC.element_to_be_clickable((By.XPATH, '//button[@id="privacy-ok"]'))
)
self.driver.find_element(By.XPATH, '//button[@id="privacy-ok"]').click()
点击查看代码
def __init__(self):
# 设置目标网址
self.url = "https://www.icourse163.org"
# 配置 Edge 选项(添加最大化、忽略证书错误等)
edge_options = Options()
edge_options.add_argument("--start-maximized") # 启动时最大化窗口(避免元素遮挡)
edge_options.add_argument("--ignore-certificate-errors") # 忽略证书错误
edge_options.add_experimental_option("excludeSwitches", ["enable-automation"]) # 隐藏自动化提示
# 配置 Edge 驱动服务
edge_service = Service(executable_path=r"H:/MicrosoftWebDriver.exe")
# 初始化 Edge 浏览器
self.driver = webdriver.Edge(service=edge_service, options=edge_options)
# 用于存储抓取的数据
self.data = {
"cousrseID": [], # 课程ID
"courseName": [], # 课程名称
"courseCollege": [], # 所属学院
"teacherMain": [], # 主讲老师
"teacherS": [], # 其他讲师
"number": [], # 学生人数
"progress": [], # 学习进度
"brief": [] # 课程简介
}
step4:自动登录功能
进入网站之后要找到登录按钮并模拟点击
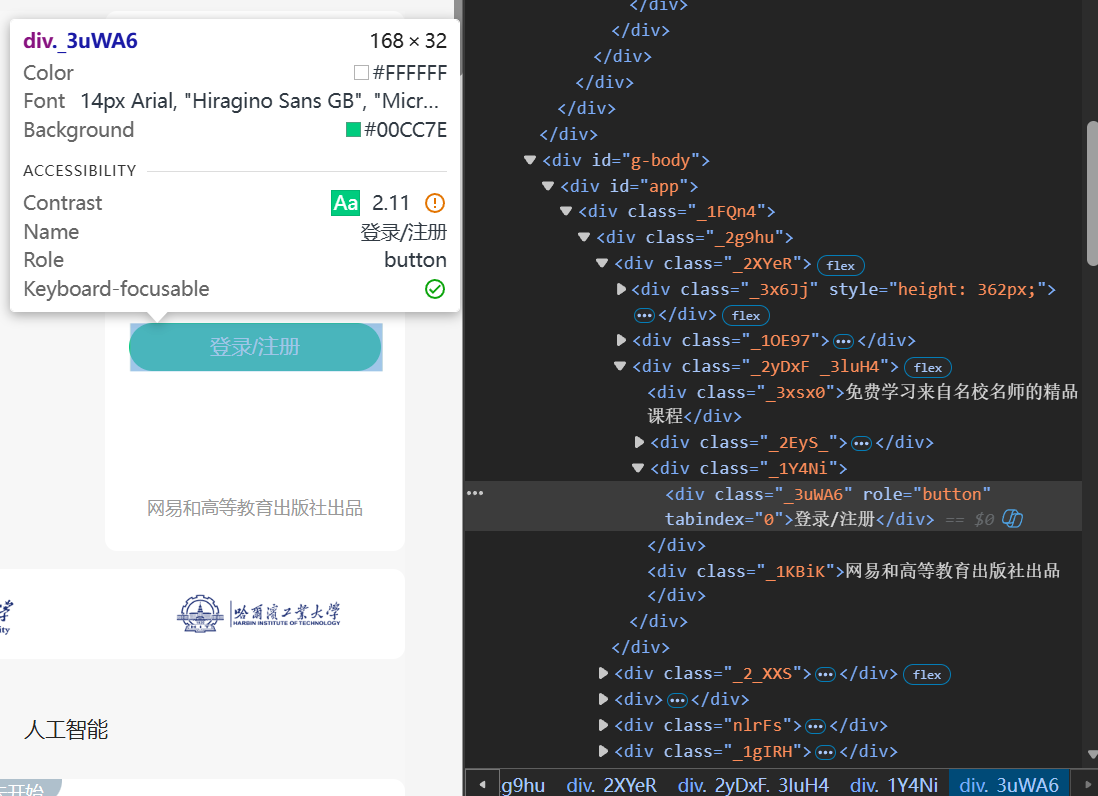
点击之后会跳出登录框,想要让selenium模拟用户输入手机号和密码自动登录,就要让selenium找到手机号和密码框,但是登录框不是在原来的页面上,需要使用driver.switch_to.frame(iframe),将焦点切换到登录框iframe中,就可以在里面输入和点击,使用.send_keys("")输入文本,登录成功之后还需要景焦点切换到原来的界面
设计如下代码
点击查看代码
def login(self):
login = self.driver.find_element(By.XPATH, "//*[@id='app']/div/div/div[1]/div[3]/div[3]/div")
login.click()
# 切换到登录框iframe
log = self.driver.find_element(By.TAG_NAME, "iframe")
self.driver.switch_to.frame(log)
# 等待登录框加载
WebDriverWait(self.driver, 15, 0.5).until(
EC.presence_of_element_located((By.XPATH, "//*[@id='login-form']/div")))
# 输入用户名和密码
username = self.driver.find_element(By.XPATH, "//input[@id='phoneipt']")
username.send_keys("19516662898")
time.sleep(1.5)
password = self.driver.find_element(By.XPATH, "//div[4]/div[2]/input[2]")
password.send_keys("你的密码")
time.sleep(1.5)
# 点击登录按钮
button = self.driver.find_element(By.XPATH, "//*[@id='submitBtn']")
button.click()
time.sleep(1.5)
# 切换回主页面
self.driver.switch_to.default_content()
time.sleep(5)
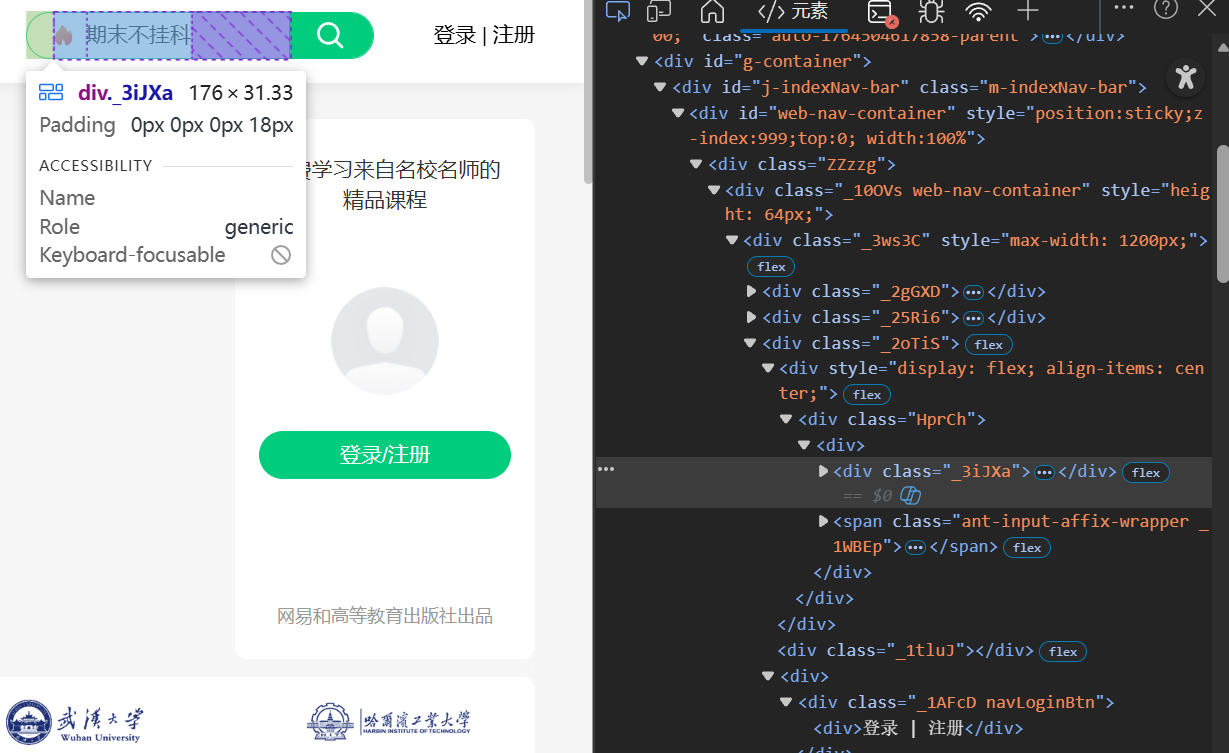
根据span class找寻搜索框,然后输入关键词后最方便的方式就是直接回车就能跳转,当然也可以同样方式定位搜索按钮交互
代码如下
点击查看代码
def search(self, course):
# 等待搜索框加载
WebDriverWait(self.driver, 10, 0.5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "input.ant-input"))
)
# 向搜索框输入课程名称(使用CSS选择器定位)
input_box = self.driver.find_element(By.CSS_SELECTOR, "input.ant-input")
input_box.clear() # 清空搜索框
input_box.send_keys(course)
time.sleep(1)
# 直接按回车键触发搜索(最稳定的方式)
input_box.send_keys(Keys.ENTER)
time.sleep(3) # 等待搜索结果加载
点击搜索按钮之后跳转到搜索到的课程页面,分析页面可得到对应课程的课程名称、学习、老师、参加人数,但是得不到完整的介绍和开课时间,所以需要再点击进去每一个课程进一步爬取
所以这里需要设计一个自动跳转每一个课程的功能
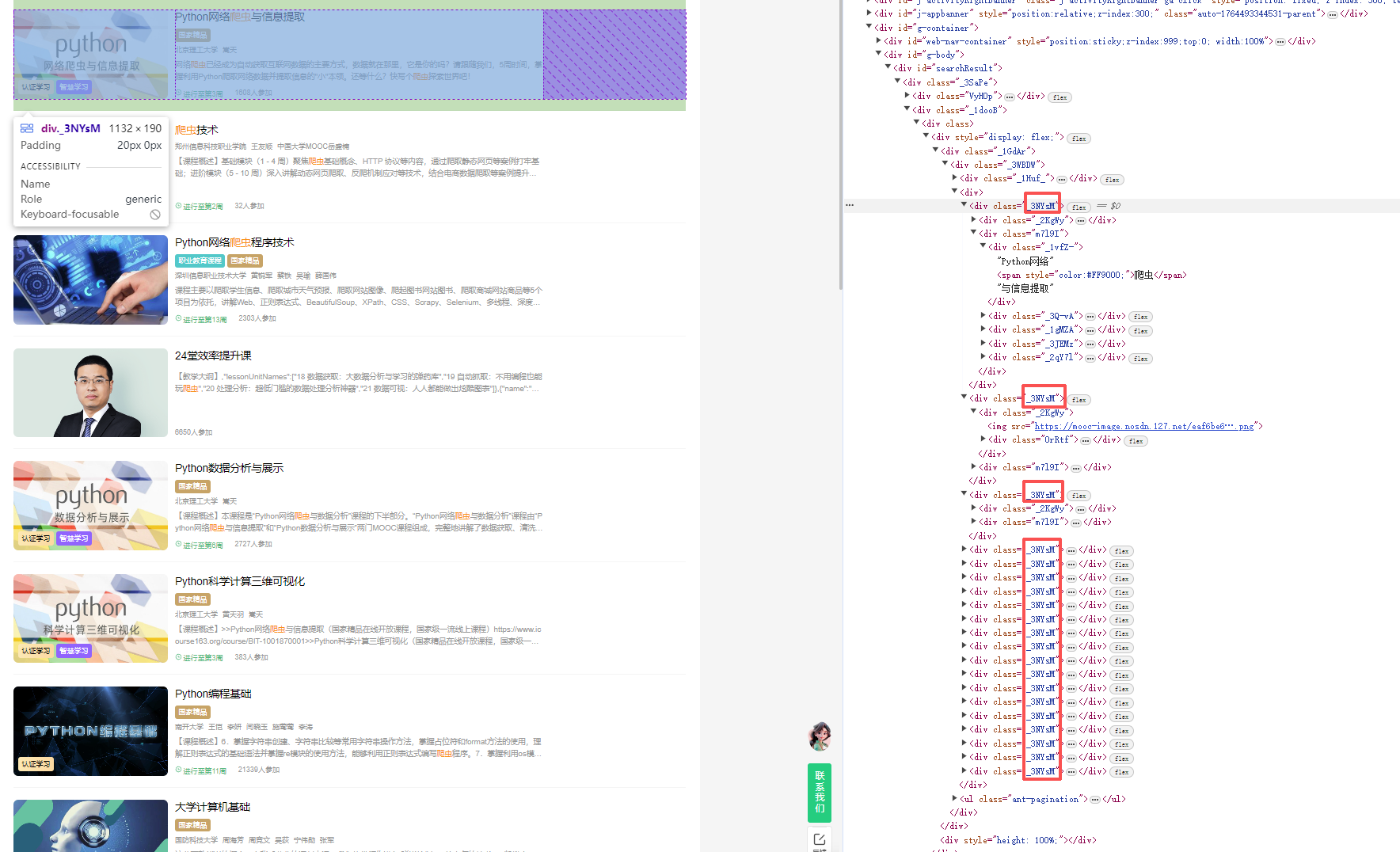
有上图可以发现共同点div._3NYsM, 找到每个后点击进入搜索完后返回
点击查看代码
# 等待课程列表加载
WebDriverWait(self.driver, 10, 0.5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "div._3NYsM"))
)
# 获取所有课程元素(每个课程都在class为_3NYsM的div中)
items = self.driver.find_elements(By.CSS_SELECTOR, "div._3NYsM")
print(f"找到 {len(items)} 个课程")
i = 1
for item in items:
try:
print(f"\n正在处理第 {i} 个课程...")
# 使用JavaScript点击当前课程元素
self.driver.execute_script("arguments[0].click();", item)
print(f" 已点击第 {i} 个课程")
time.sleep(3)
# 切换到新打开的窗口
if len(self.driver.window_handles) > 1:
self.driver.switch_to.window(self.driver.window_handles[-1])
print(f" 已切换到课程详情页")
# 等待详情页加载
WebDriverWait(self.driver, 10, 0.5).until(
EC.presence_of_element_located((By.TAG_NAME, "body"))
)
time.sleep(2)
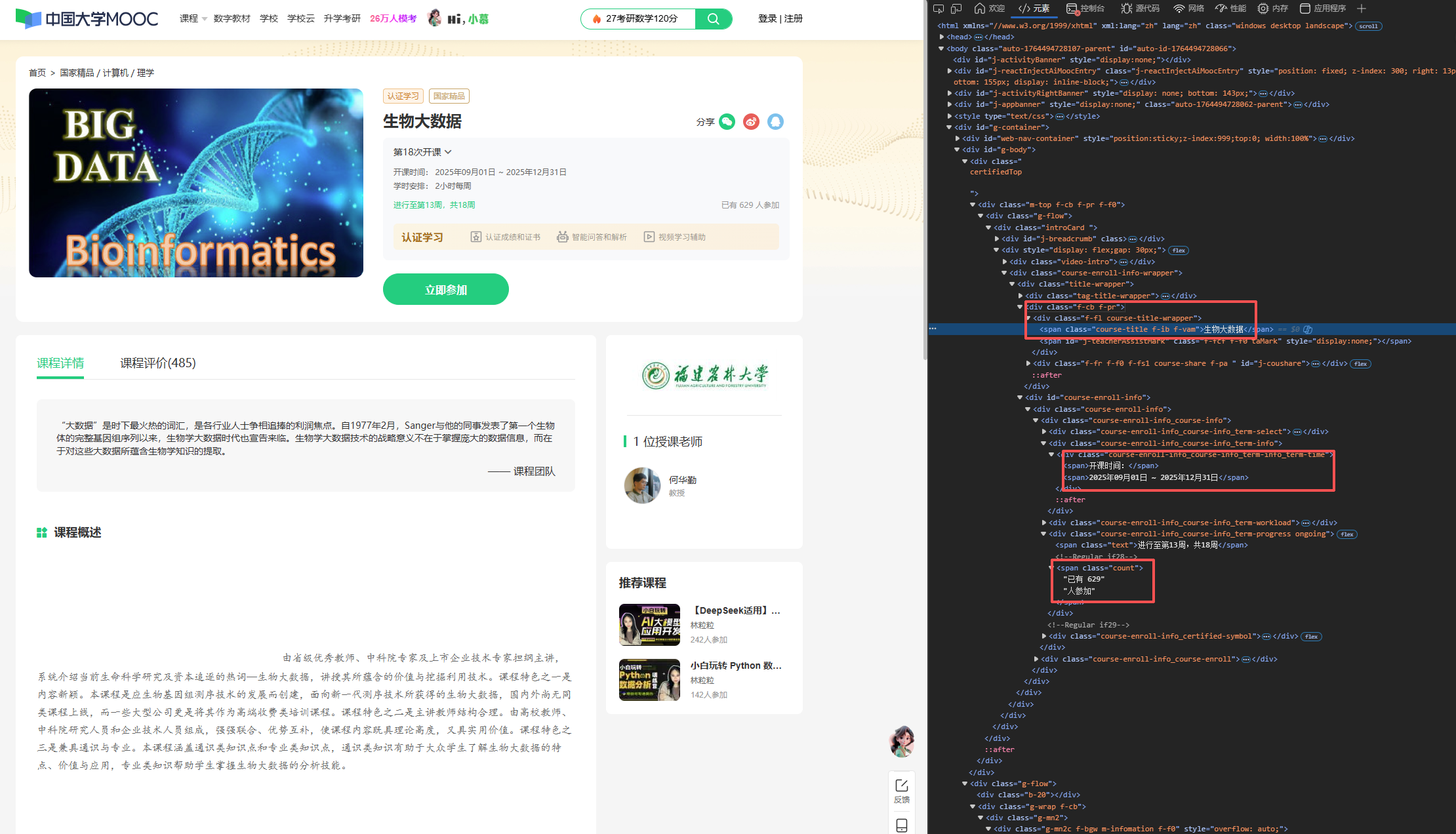
教师+课程简介+学校名称
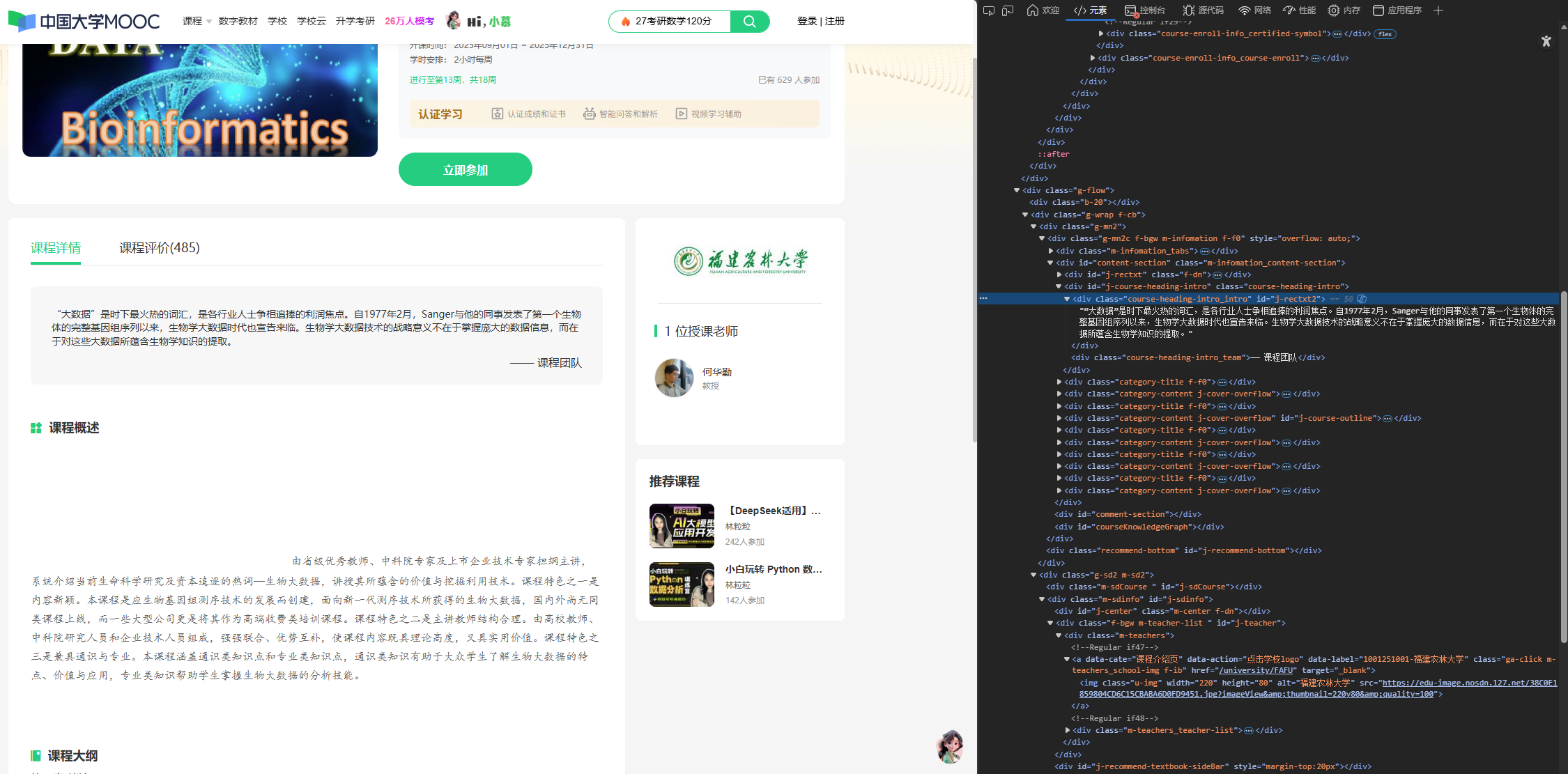
同时呢我们print发现每个课程的课程id放在了url中,所以用正则表达式对其进行提取即可

根据以上图设计下面xpath代码
点击查看代码
# 1. 爬取课程名称(使用contains匹配包含course-title的class)
course_name = self.driver.find_element(By.XPATH, "//span[contains(@class, 'course-title')]").text
print(f" 课程名称: {course_name}")
# 2. 爬取开课时间
start_time = self.driver.find_element(By.XPATH, "//div[@class='course-enroll-info_course-info_term-info_term-time']/span[2]").text
print(f" 开课时间: {start_time}")
# 3. 爬取参与人数
participant_count = self.driver.find_element(By.XPATH, "//span[@class='count']").text
print(f" 参与人数: {participant_count}")
# 4. 爬取开课学校(从img标签的alt属性获取)
school_name = self.driver.find_element(By.XPATH, "//div[@class='m-teachers']//img[@class='u-img']").get_attribute("alt")
print(f" 开课学校: {school_name}")
# 5. 爬取教师信息
# 获取所有教师名字(h3标签)
teachers = self.driver.find_elements(By.XPATH, "//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']")
teacher_names = [teacher.text for teacher in teachers if teacher.text]
if teacher_names:
# 第一个教师作为主讲教师
teacher_main = teacher_names[0]
print(f" 主讲教师: {teacher_main}")
# 所有教师作为教学团队
teacher_team = ", ".join(teacher_names)
print(f" 教学团队: {teacher_team}")
else:
teacher_main = "未找到"
teacher_team = "未找到"
print(f" 教师信息: 未找到")
# 6. 爬取课程简介
brief = self.driver.find_element(By.XPATH, "//div[@class='course-heading-intro_intro']").text
print(f" 课程简介: {brief[:]}...") # 只打印前50个字符
# 7. 从URL中提取课程号
current_url = self.driver.current_url
# 使用正则表达式提取课程号(格式:XXX-数字)
import re
match = re.search(r'/course/([A-Z]+-\d+)', current_url)
if match:
course_id = match.group(1)
print(f" 课程号: {course_id}")
else:
course_id = "未找到"
print(f" 课程号: 未找到")
print(f"\n课程详情页URL: {self.driver.current_url}")
其实原理还是定位点击,如下图
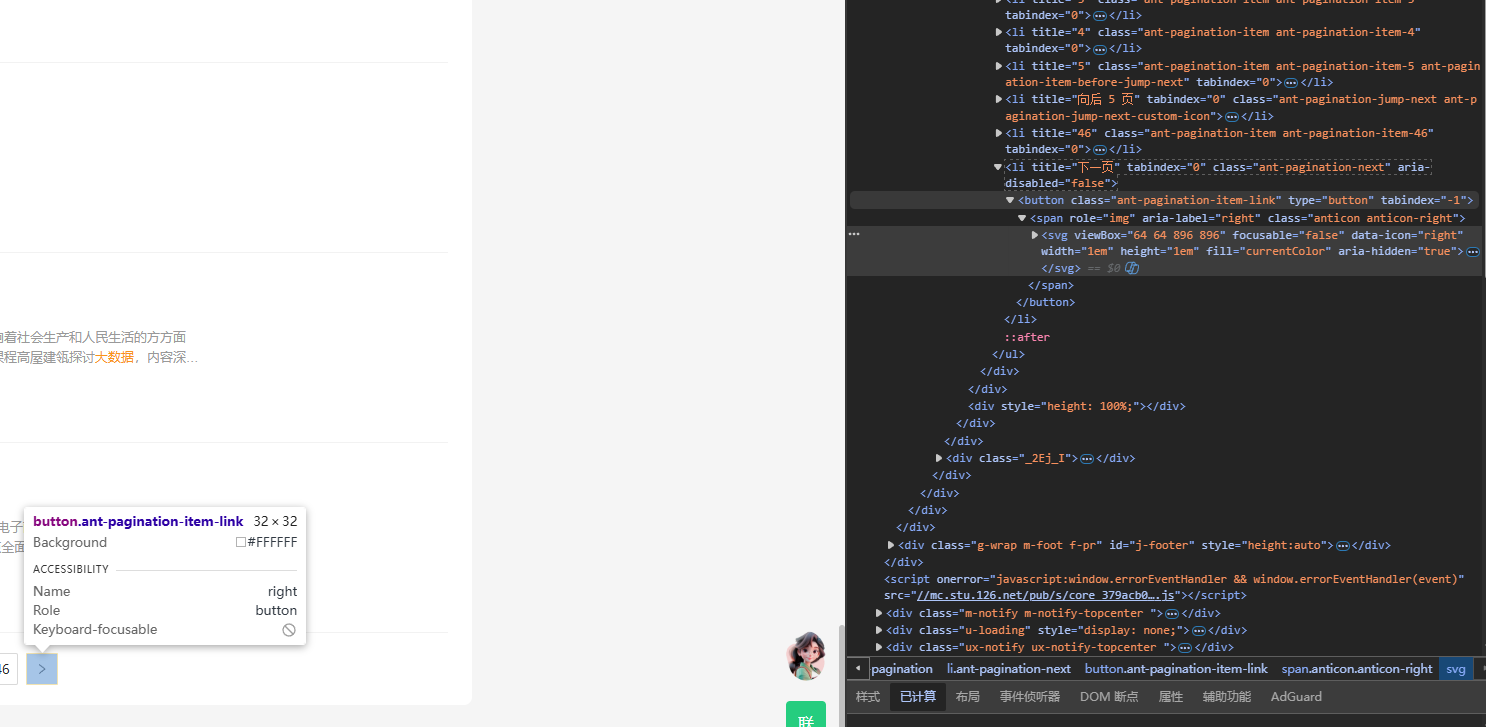
代码如下
点击查看代码
def process(self, course, page=1):
self.driver.get(self.url)
time.sleep(2)
self.login()
time.sleep(2)
self.search(course)
time.sleep(2)
for i in range(1, page + 1):
print(f"正在抓取第 {i} 页...")
self.parse()
if i == page:
break
else:
try:
# 点击下一页
next_button = self.driver.find_element(By.XPATH, '//li[@class="ant-pagination-next"]')
next_button.click()
time.sleep(2)
点击查看代码
def mySQL(self):
try:
# 连接到 MySQL 数据库
con = pymysql.connect(
host="localhost",
user="root",
password="629528",
database="DataAcquisition",
charset='utf8mb4'
)
cursor = con.cursor()
# 删除旧表(如果存在)
cursor.execute("DROP TABLE IF EXISTS mooc")
# 创建表结构
sql = """
CREATE TABLE mooc (
cousrseID VARCHAR(64) PRIMARY KEY,
courseName VARCHAR(128),
courseCollege VARCHAR(128),
teacherMain VARCHAR(64),
teacherS VARCHAR(256),
number_ VARCHAR(32),
progress VARCHAR(32),
brief TEXT
)
"""
cursor.execute(sql)
print("表创建成功")
# 准备插入数据
sql = """
INSERT INTO mooc (cousrseID, courseName, courseCollege, teacherMain, teacherS, number_, progress, brief)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
"""
点击查看代码
# 插入数据
for i in range(len(self.data["cousrseID"])):
try:
cursor.execute(sql, (
self.data["cousrseID"][i],
self.data["courseName"][i],
self.data["courseCollege"][i],
self.data["teacherMain"][i],
self.data["teacherS"][i],
self.data["number"][i],
self.data["progress"][i],
self.data["brief"][i]
))
except Exception as err:
print(f"插入第 {i+1} 条数据失败: {err}")
# 提交事务
con.commit()
print(f"成功插入 {len(self.data['cousrseID'])} 条数据")
# 关闭连接
cursor.close()
con.close()
运行结果
终端部分展示
⚠️注意:运行中会出现找不到课程,是因为搜索到的课程过期了,插入数据库时我设计了跳过该课程如下图
数据库运行部分
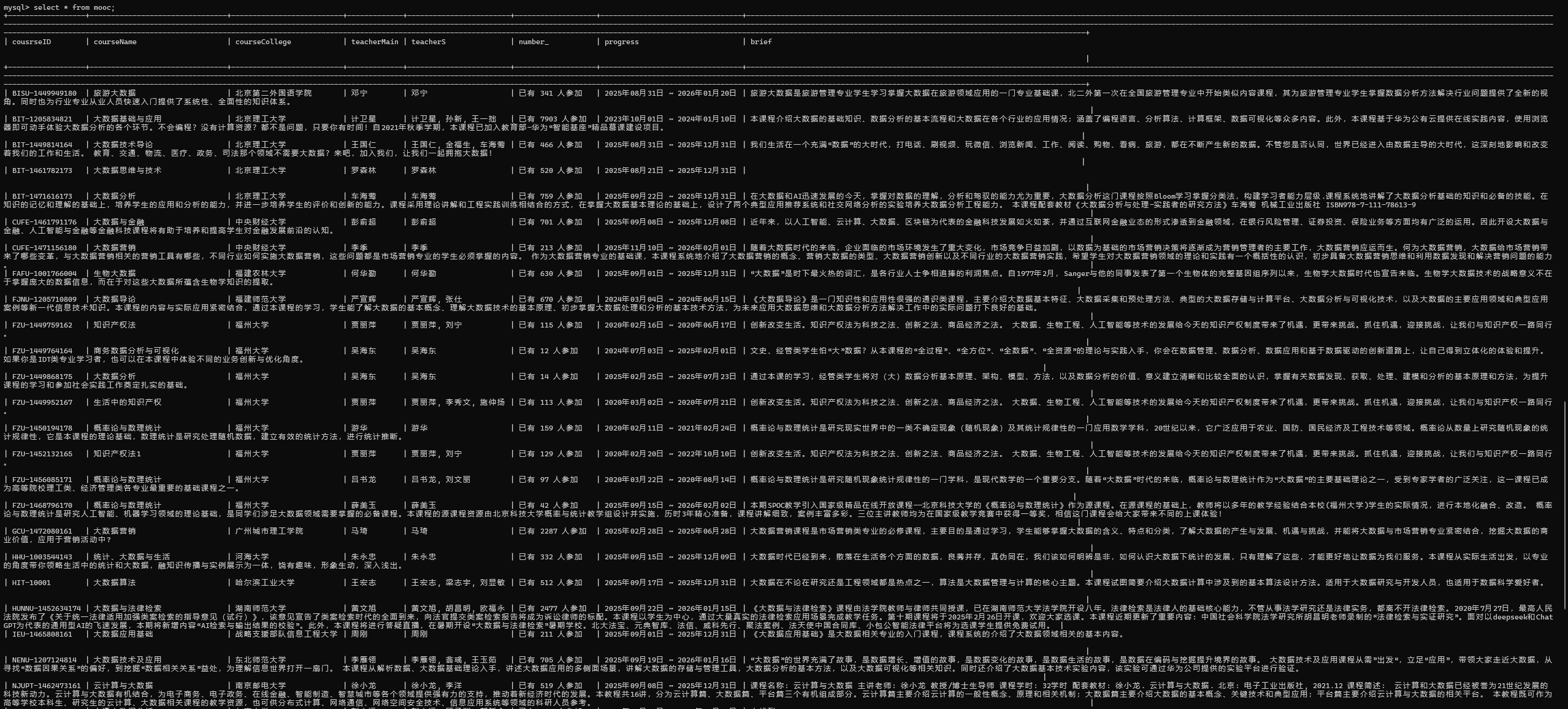
心得体会
首先,Selenium作为一个强大的自动化测试工具,在网页爬取过程中发挥了至关重要的作用。在爬取MOOC网站的数据时,初步遇到的问题是如何正确模拟用户登录。由于MOOC网站有复杂的登录框架和iframe结构,我需要通过XPath准确定位登录按钮及输入框。尤其是在使用iframe时,必须先切换到相应的iframe内,进行操作后再切换回主页面,这一过程需要较为细致的调试。
项目采用 Selenium+Edge 驱动,成功攻克了动态页面加载、登录验证、窗口切换等核心难点,实现了课程搜索、详情解析与 MySQL 存储的完整流程。
实践中,我深刻意识到元素定位准确性、等待机制合理性对爬虫稳定性的关键作用,也通过异常处理机制规避了页面加载失败、数据缺失等问题。同时,从驱动配置、反爬规避到数据库表设计与数据插入,每一步都让我对 “爬取 - 解析 - 存储” 的爬虫逻辑有了更清晰的认知
作业③:
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
实时分析开发实战:
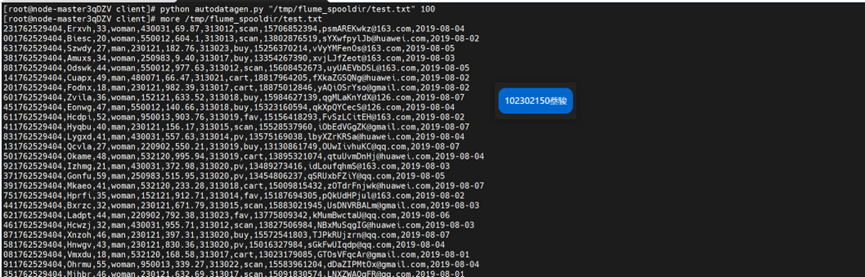
任务一:Python脚本生成测试数据
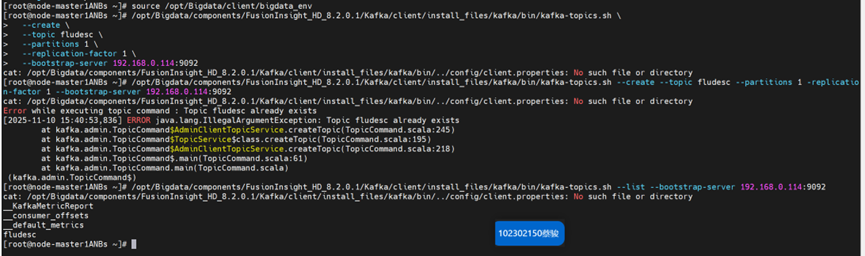
任务二:配置Kafka
任务三: 安装Flume客户端
任务四:配置Flume采集数据
实验步骤
任务一:开通MapReduce服务
购买ECS服务器
购买RDS数据库

配置相关规则(安全组,弹性公网,委托设置)
开通DLI服务
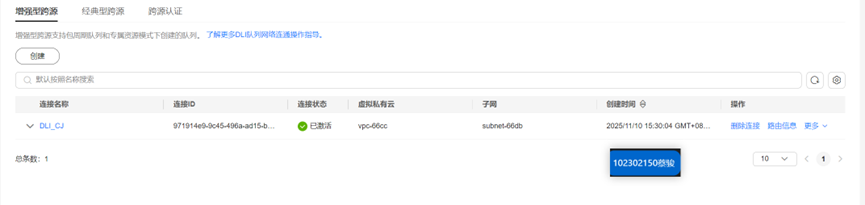
实时分析开发实战:
任务一:Python脚本生成测试数据
任务二:配置kafka
任务三:安装Flume客户端
校验客户端文件包;

安装环境;
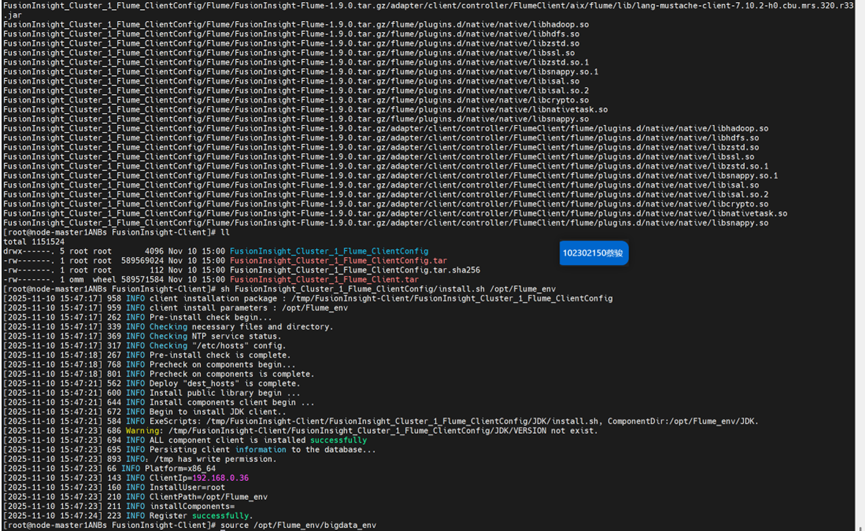
安装客户端:

重启flume服务

任务四:配置Flume采集数据
修改配置文件


查看结果
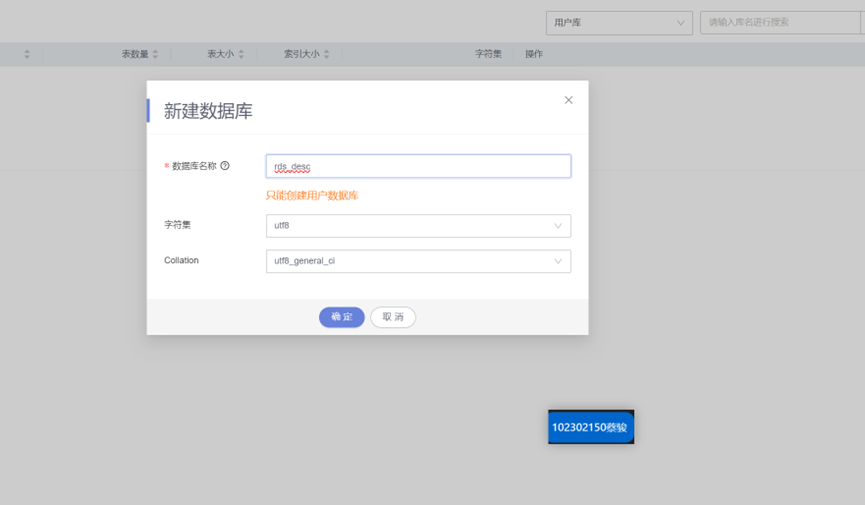
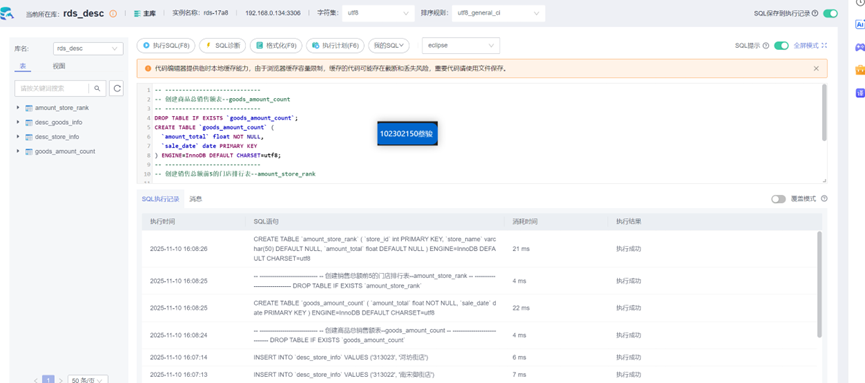
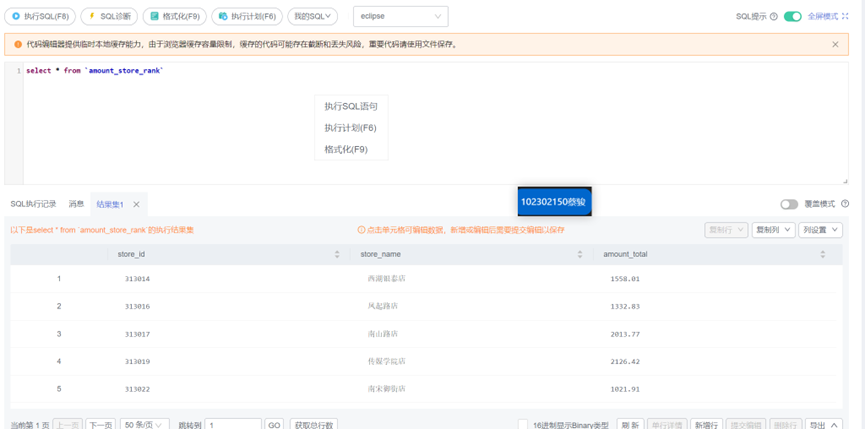
任务五:MySQL中准备结果表与维度表数据
创建数据库
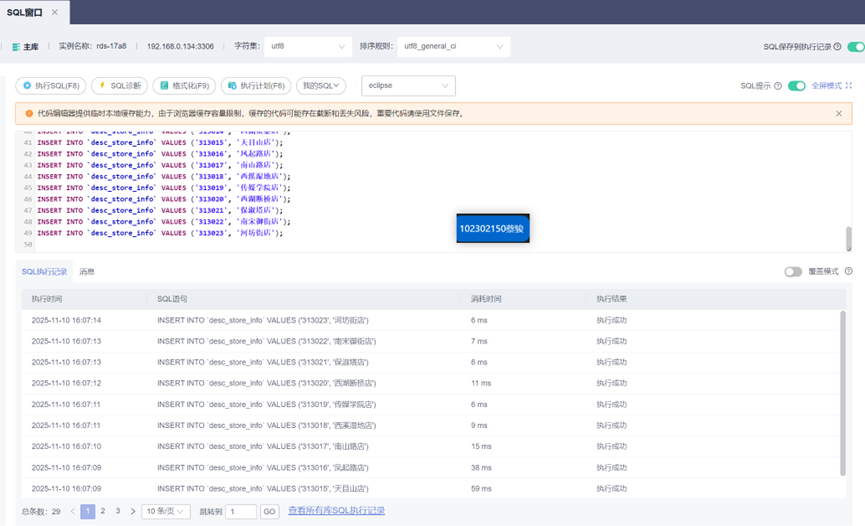
创建维度查询
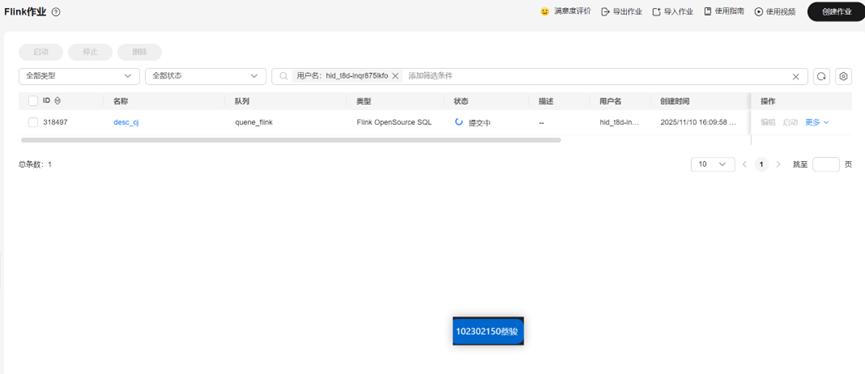
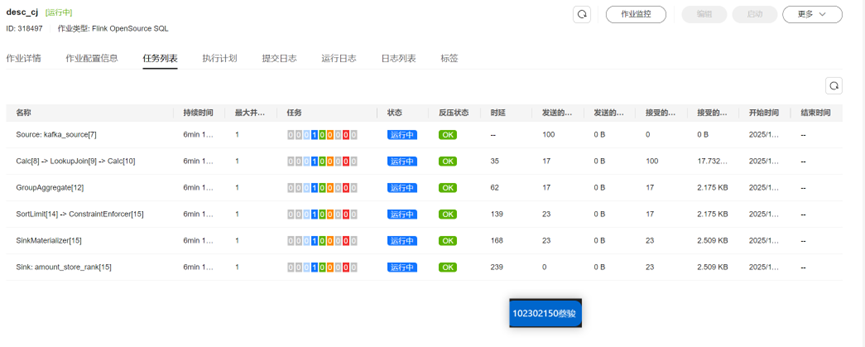
查看作业运行
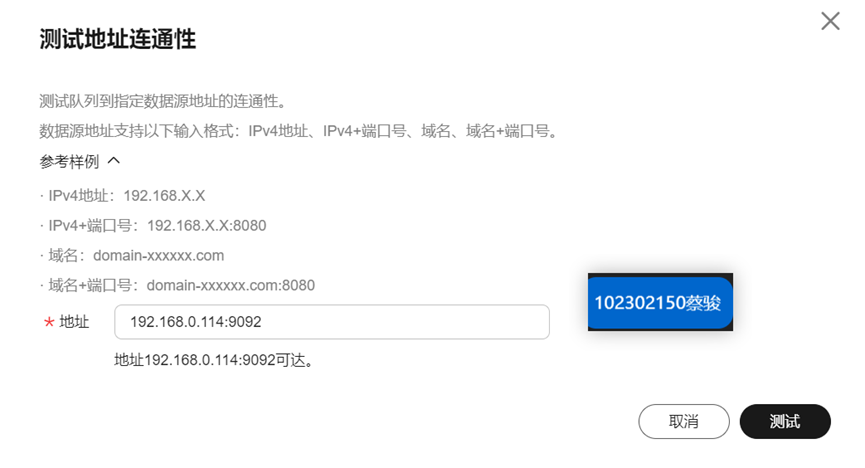
测试连通性:
验证数据分析
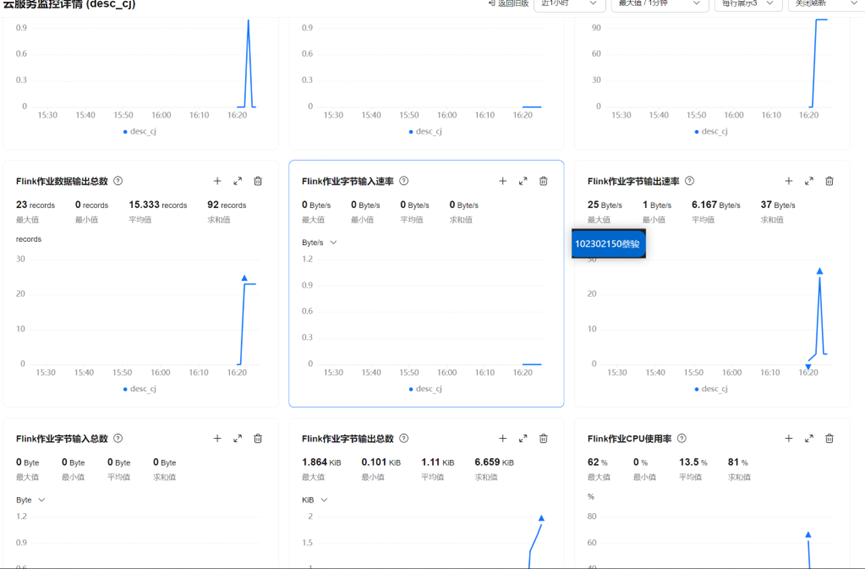
Flink作业监控:
MySQL验证
任务六:DLV数据可视化

新建数据连接
创建大屏
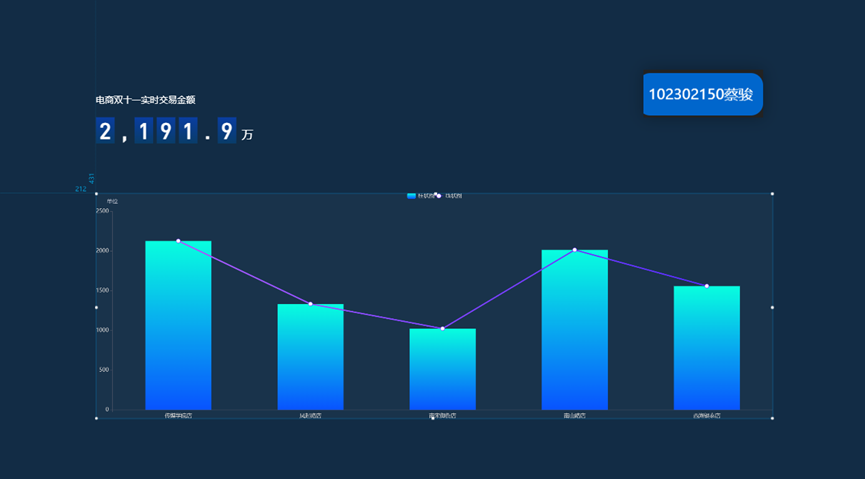
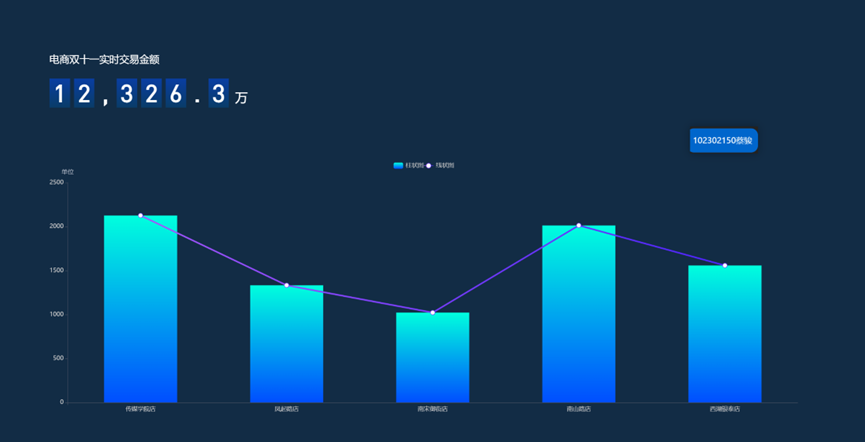
展示实时交易金额
展示销售额排行前5的门店信息
定时执行数据生成脚本

心得体会
实践二围绕 MRS 集群、Kafka、Flume、Flink 构建实时数据处理链路,聚焦电商场景下的实时交易分析与可视化,让我掌握了实时大数据处理的核心流程。
核心收获
- 分布式组件协同需注重网络连通性,Kafka 的 bootstrap-server 地址、Flume 的数据源配置、Flink 与 MySQL 的连接均需提前测试连通性,避免链路中断。
- 数据采集与传输的稳定性关键在配置优化,Flume 的 spooldir 源需合理设置文件滚动策略,Kafka 主题的分区与副本数需根据数据量调整。
- Flink SQL 作业的编写需结合业务场景,通过 LookupJoin 关联维度表(门店信息)实现数据 enrichment,体会到实时计算中 “流批结合” 的灵活性。
- DLV 可视化工具将抽象数据转化为直观图表,实时交易金额、门店销售额排行等大屏展示,让我理解了数据可视化对业务决策的支撑价值。
问题与反思
• 初期启动 Flume 服务时提示配置文件错误,发现是 properties 文件中数据源路径与实际目录不一致,后续养成配置后校验路径、权限的习惯。
• Kafka 消费者无法接收数据,排查后发现是 Flume 的 sink 配置中 bootstrap-server 地址写错,凸显了分布式系统中 “配置一致性” 的重要性。
• 执行第一个python文件之前需要创建文件夹,文档中文件夹一开始没有
• 第一次做实践2的时候,发现flume服务用不了,后面发现是下载客户端下载到另一个节点上,与我登录的公网ip不同,所以我重新做该实践的时候,我先看他会下载到哪个节点,然后根据下载的地址绑定公网ip,这样就解决了地址不对应的问题
• Kafka配置的时候,教程给的路径与真实路径不同,所以我们需要改成正确路径如下图所圈

 浙公网安备 33010602011771号
浙公网安备 33010602011771号