论文阅读《Boosting the Generalization Capability in Cross-Domain Few-shot Learning via Noise-enhanced Supervised Autoencoder》
Abstract
我们通过提高模型的泛化能力来解决这个cross-domain few-shot learning(CDFSL)问题。具体来说,我们在模型用 noise-enhanced supervised autoencoder(NSAE)来捕获更广泛的特征分布的变化。
1. Methodology
1.1. Preliminaries
Problem formulation:源数据集有一个大规模的标记数据集Ds,而目标数据集只有有限的标记图像。我们的方法首先在源数据集上对模型进行预训练,然后对目标数据集进行fine-tunes。目标域中的每个“N-wayK-shot”分类任务都包含一个支持数据集Dts和一个查询数据集Dtq。支持集包含N个类,每个类中有K个标记图像,查询集包含来自相同N个类的图像,每个类中有Q个未标记图像。
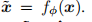 ,解码器
,解码器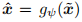 这是对输入x的重构。并将重构损失表示为:
这是对输入x的重构。并将重构损失表示为: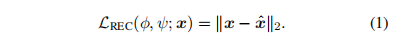
把预测类标签和重构输入联合起来的SAE[22]被证明可以得到很好的泛化能力。在SAE中,将表示˜x输入分类模块进行标签预测,损失函数为
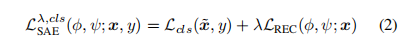
其中,Lcls是用于分类的损失函数,λ是控制重建权重的超参数。
1.2. Overview
在传统的基于迁移学习的方法中,首先通过最小化分类损失Lcls-P,在具有足够标记图像的Ds上进行预训练,然后通过最小化分类损失Lcls-F,对目标域支持集Dts进行预训练的特征提取器进行微调。请注意,训练前期间的损失函数Lcls-P和微调期间的Lcls-F可能会有所不同。考虑到传统迁移学习方法在CDFSL上的优越性能,我们在工作中使用了迁移学习管道。基于SAE的泛化能力和输入噪声输入的泛化增强,我们提出通过噪声增强SAE(NSAE)来提高模型的泛化能力。NSAE不仅预测输入的类标签,还预测“噪声”重构的标签。具体的细节如下图:
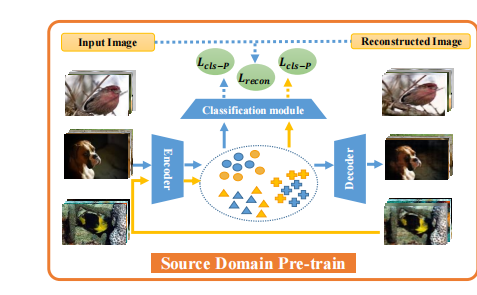
1.3. Pre-train on the source domain :
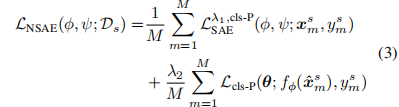
其中,Lcls-P为一些分类损失,LSAE用(2)给出。第二项是重建图像的分类损失。原始输入图像和重建图像的分类损失函数相同。λ1和λ2是控制损失权重的两个超参数
1.4. Fine-tune on the target domain:
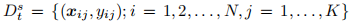 作为目标域上的支持集。在第一步中,旨在最小化重建损失
作为目标域上的支持集。在第一步中,旨在最小化重建损失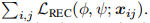 在的第二步中,只有编码器用于对分类损失Lcls-F的Dts进行微调。我们在消融研究中表明,这种两步程序比纯粹微调在目标支持集上使用Lcls-F的编码器更好。下面我们分别将它们称为一步微调或两步微调。
在的第二步中,只有编码器用于对分类损失Lcls-F的Dts进行微调。我们在消融研究中表明,这种两步程序比纯粹微调在目标支持集上使用Lcls-F的编码器更好。下面我们分别将它们称为一步微调或两步微调。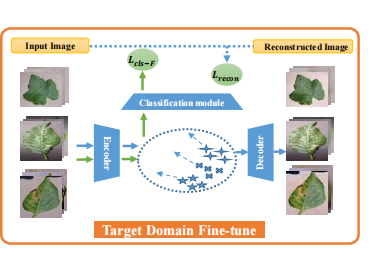
1.5. Choices of loss functions:
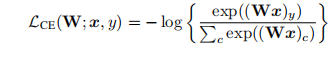
第二种是使用batch spectral regularization(BSR)[27]的CE损失。这种分类损失被称为BSR失。
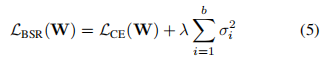
其中,σ1,σ2,……,σb是批处理特征矩阵的奇异值。
下图显示如何求解矩阵的奇异值:

在微调阶段的第二步中,我们将一半的图像随机分成一半伪支持集,剩下的一半是伪查询集
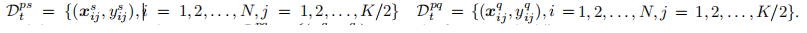
首先得到了基于特征提取器fφ的伪支持集和伪查询集的特征嵌入情况。然后是同一类中伪支持图像的平均特征嵌入:
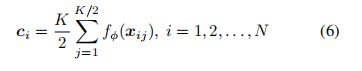
用于表示类,并被称为类原型。给定一个距离函数d(·,·)和一个伪查询图像x,分类模块在类上产生一个分布。x属于k类的概率为:
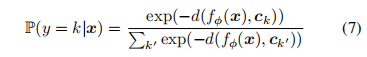
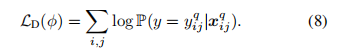
具体实现情况如下图:
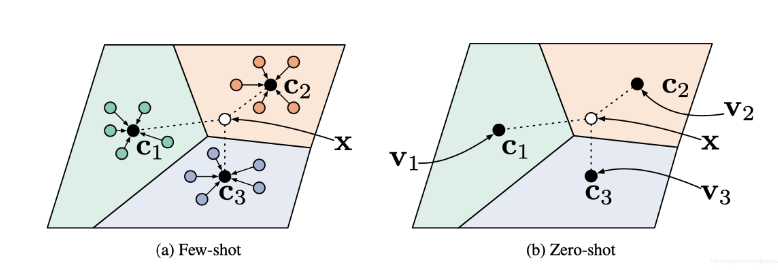
Lcls-P的两种损失函数和Lcls-F的两种损失函数结合,得到4种不同的损失函数,分别命名为CE+CE、BSR+CE、CE+D和BSR+D。
2. Experiments
2.1. Experiment setting
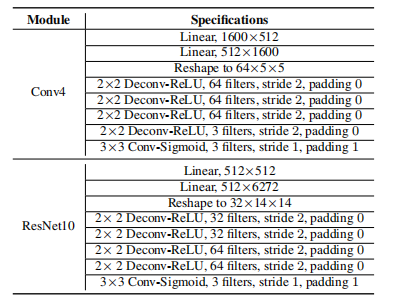
2.2. Ablation study
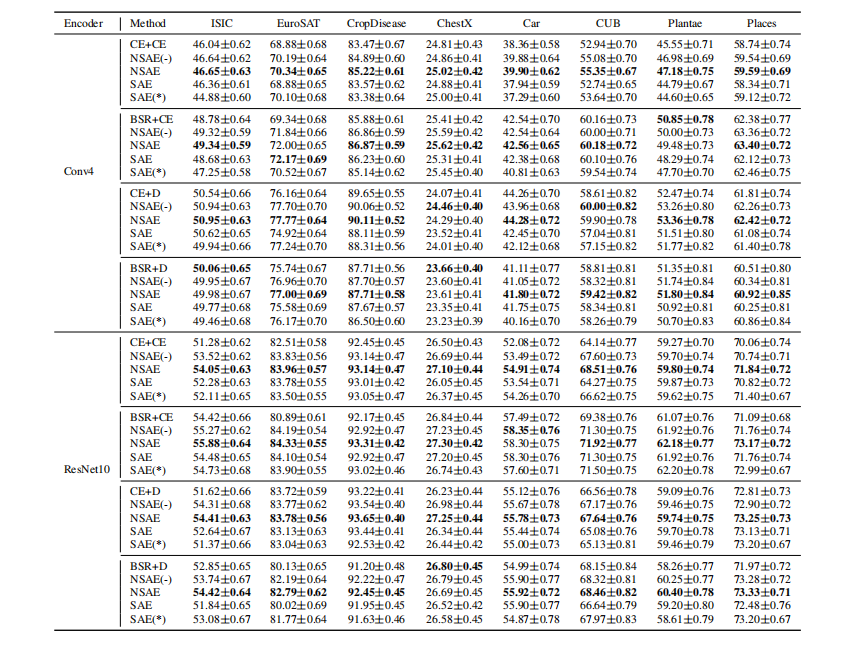
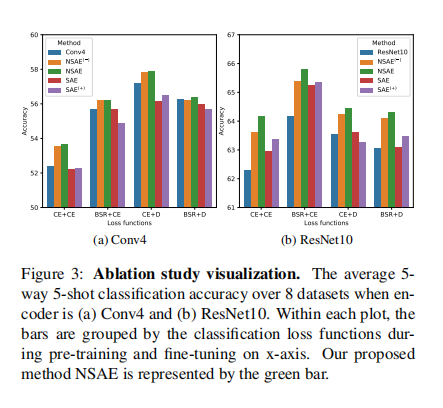
从消融研究中,我们可以看到,当在训练前和微调过程中的损失函数相同时,更复杂的编码器ResNet10比Conv4具有更高的分类精度。当训练前的分类损失为CE时,在微调过程中使用基于距离的损失函数比使用CE损失具有更高的分类精度。然而,当在训练前使用分类损失BSR时,我们得到了相反的结论。总的来说,训练前中使用BSR作为分类损失,微调中使用CE作为分类损失,准确率最高。
在训练前阶段的重建图像可以视为噪声输入,以提高模型的泛化能力。如果我们使用手工噪声的图像代替重建的图像,能提高模型的泛化能力吗?在我们的实验中,我们考虑了以下四种手工噪声:Gaussian, salt-pepper, Poisson, and speckle。的超参数值与主论文第4.1节中给出的超参数值相同。8个数据集的平均结果如图6所示。
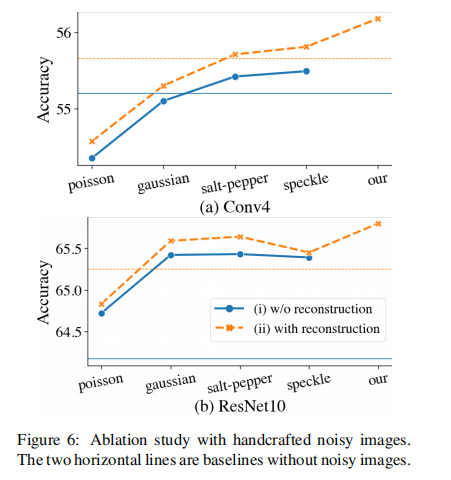
我们得出以下两点结论(1)无论噪声类型如何,使用具有重构损失的自动编码器方案有助于提高泛化能力(2)添加手工噪声可能不会提高精度,但我们的设计始终提高了精度,超过了手工噪声的所有结果。
2.3. Generalization capability analysis:

如图4中第一行所示,由于在源域上有足够的训练示例,所有模型都表现出判别功能。基于BSR的损失比CE损失更集中。此外,基于NSAE损失的特征嵌入具有较大的类内变化和较小的类边缘。如图4中第二行所示,我们观察到相反的情况。在第一列和第三列中,不同种类的特征相混淆。当使用NSAE损失时,目标域上的类将变得更加可分离。类内变化较小,类间距离较大。这表明该方法具有较好的泛化能力。
Statistical analysis of discriminability:
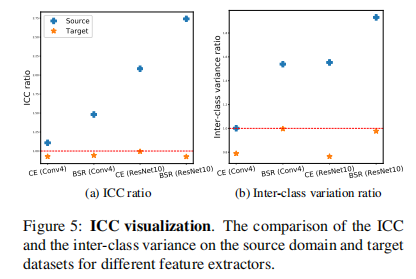
此外,我们还通过类内相关性(ICC)定量地测量了特征嵌入的可别性。ICC被定义为类间变异与类内变异的比值。因此,ICC越大,不同类中的特征就越分离,或者同一类中的特征就越集中。国际商会的定义详见补充文件A节。我们比较了从传统的预训练编码器中提取的特征的ICC和基于我们提出的没有进行微调的NSAE的特征的ICC。我们在训练前使用了两种编码器,即Conv4和ResNet10,以及两种分类损失,即CE和BSR。这导致了四种组合,分别表示为CE(Conv4)、BSR(Conv4)、CE(ResNet10)和BSR(ResNet10)。我们取传统训练方法的ICCs的比率和基于我们提出的方法的比率。结果见图5.(a).如图所示,在所有4种情况下,ICC比率在源域(蓝色十字)大于1,在目标域(黄色星)小于1。这表明在源域上,来自我们的r的特征提取器与传统的方法并没有什么区别。然而,这些特征提取器在目标域上泛化得更好。我们同样在图5(b).中显示了类间的变化我们提出的方法在目标域上显示出较大的类间变化,表明类的可分离性。具体图像如下图:
2.4. Main results
TABLE(1)
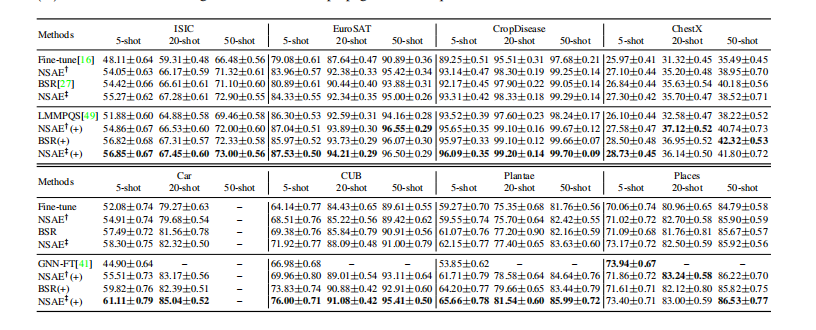
数据集的处理:作者使用miniImageNet作为源数据集并为了评估我们的方法的泛化能力,我们使用了8个不同的数据集作为目标域。前四个数据集是在[16]中提出的基准数据集。下面我们将这四个数据集称为作CropDisease、EuroSAT、ISIC、ChestX,这些数据集与minImageNet的相似性从左到右下降。我们还包括另外四个自然图像数据集,Car,CUB,Plantae和Places 进行评价。每个目标域数据集上模拟600个独立的5-way CDFSL分类任务来评估分类器的性能。对于每个任务,我们随机抽取5个类,在每个类中,我们随机选择K(5,20,50)个图像作为支持集,15个图像作为查询集。
主要结果:使用传统的迁移学习,CE+CE在[16]中简化为“Fine-tune”方法,而BSR+CE在[27]中简化为“BSR”方法。.以ResNet10为骨干的8个数据集上的5-way K-shot分类精度。我们提出的具有CE+CE和BSR+CE损失的方法分别记为“NASE†”和“NASE‡”。(+)表示使用了数据增强和标签传播技术。
3.conclusion
本文提出了一种提高基于迁移学习的跨域少镜头学习(CDFSL)方法泛化能力的新方法。我们建议在源域上训练一个噪声增强的监督自动编码器,而不是一个简单的特征提取器。理论分析表明,NSAE可以极大地提高特征提取器的泛化能力。我们还利用了自动编码器的性质,并提出了一个两步微调过程,其性能优于过去的一步微调过程。大量的实验和分析证明了我们的方法的有效性和推广。此外,NSAE的公式使得我们提出的方法很容易应用于现有的基于迁移学习的CDFSL方法,以进一步提高其性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号