
浅谈分布式锁的常用实现
序言
在单机系统里,如果有多个线程要同时访问某个共享资源的时候,我们可以采用线程间加锁的机制,即基于 mutex(互斥锁),当某个线程获取到这个资源后,就需要对这个资源进行加锁,当使用完资源之后,再解锁,其它线程就可以接着使用了。例如,在 Java 中 synchronized/Lock 等。
如今单机系统很少了。取而代之的是分布式系统,分布式系统通常是集群部署模式。在分布式系统中,线程之间的锁机制就不奏效了,系统可能会有多份并且部署在不同的机器上,这些资源已经不是在线程之间共享了,而是属于进程之间共享的资源。为了解决这个问题,「分布式锁」就出现了。
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。在分布式系统中,常常需要协调他们的动作。如果不同的系统或是同一个系统的不同主机节点之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁。
分布式锁特性

常用实现方案

基于数据库实现
基于数据库实现-乐观锁
乐观锁的特点先进行业务操作,不到万不得已不去拿锁。“乐观”地认为拿锁多半是会成功的,因此在进行完业务操作需要实际更新数据的最后一步再去拿一下锁就好。
乐观锁机制是在数据库表中引入一个版本号(version)字段来实现
talk is cheap, show you the codes. 让我们用代码示意表示一下:
var entity = inventoryRepository.getById(productId); ...执行业务操作 //持久化更新数据 UPDATE inventory SET stock = stock - 1, version = version + 1 WHERE product_id = 1 AND version = @version;
也就是说,当我们要从数据库中读取数据的时候,同时把这个 version 字段也读出来,如果要对读出来的数据进行更新后写回数据库,则需要将 version 加 1,同时将新的数据与新的 version 更新到数据表中,且必须在更新的同时检查目前数据库里 version 值是不是之前的那个 version ,如果是,则正常更新。如果不是,则更新失败,说明在这个过程中有其它的进程去更新过数据了。
乐观锁遵循的两点法则:
-
锁服务要有递增的版本号 version
-
每次更新数据的时候都必须先核对版本号,然后再写入新的版本号
基于数据库实现-悲观锁
悲观锁的特点是先获取锁,再进行业务操作,即*“悲观”*地认为获取锁是非常有可能失败的,因此要先确保获取锁成功再进行业务操作
通常所说的“一锁二查三更新”即指的是使用悲观锁。
当数据库执行 select for update 时会获取被 select 中的数据行的行锁
并发执行的 select for update 命中同一行记录则会发生排斥(需要等待行锁被释放),以此达到锁的效果select for update 获取的行锁会在当前事务结束时自动释放,因此必须在事务中使用
基于数据库实现-总结

基于redis实现
基于 Redis 实现的锁机制,主要是依赖 Redis 自身的原子操作
redisDistributedLock.lock
实现思想
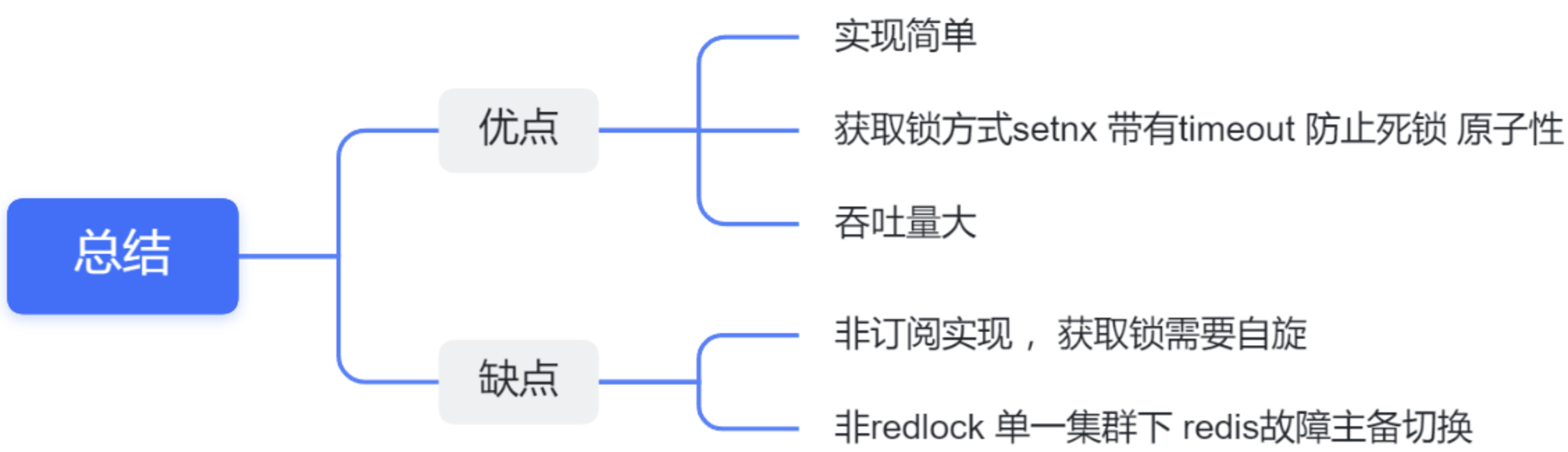
基于redis实现-总结
基于 ZooKeeper 实现
基于 ZooKeeper ,就是使用它的临时有序节点来实现的分布式锁。
实现思想:
(1)创建一个目录 mylock;
(2)线程A想获取锁就在 mylock 目录下创建临时顺序节点;
(3)获取 mylock 目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
(4)线程 B 获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
(5)线程 A 处理完,删除自己的节点,线程 B 监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
基于 ZooKeeper 实现-原理

基于ZooKeeper实现-总结

总结
分布式锁有很多种,”相对主流的有三种”只是个人愚见。
分布式锁千变万化,具体的实现方案按照自己的场景及条件实现。
分布式锁解决的本质问题是针对同步资源的合理占用。当然,最理想的方式是不用加锁就可以避免并发操作。
当看到一些不好的代码时,会发现我还算优秀;当看到优秀的代码时,也才意识到持续学习的重要!--buguge
本文来自博客园,转载请注明原文链接:https://www.cnblogs.com/buguge/p/18636457

 浙公网安备 33010602011771号
浙公网安备 33010602011771号