2021_BUAAOO_第三单元总结
一、设计策略
由于本单元的作业已经给出了JML,并且其整体上的架构已经比较完善了,因此总体上采用了JML的架构,只是在一些具体实现上进行了修改,例如将JML中的所有数组都改为使用容器(具体见“三、容器选择”模块)。而对不同类型的方法,采取了不同的实现方式,具体如下:
| 方法类型======= | 代表方法 | 实现策略 |
|---|---|---|
| 直接查询或修改类中非容器的属性 | Person中的getId,setMoney,Group中的getId,Message中的getType | 直接按照JML中的描述进行实现 |
| 简单的查询或修改一个容器属性的方法 | Peron中的quetyValue,isLinked | 这些方法的JML都是利用for循环对数组进行操作,因此直接套用JML会使得复杂度提高。解决方法是选用HashMap,这样可以直接利用HashMap自带的方法进行查询或修改 |
| 需要遍历单个容器进行计算的方法 | Group中的getValueSum,getAgeMean,getAgeVar,NetWork中的isCircle | JML中只有在调用对应方法时才会使用for循环进行求和,这样如果多次调用该方法会使得运行时间很长。分析可以知道,实际上每次调用对应方法时很多都是重复的计算,因此可以在类中设置缓存属性。具体例子是在Group中设置valueSum属性记录Group中所有关系的value的和,每当调用addPerson等方法改变容器的时候,就在其中维护valueSum的值。这样在调用getValueSum的时候就可以直接返回valueSum的值,从而降低了复杂度。再例如NetWork中的isCircle方法,这个方法用来求两个人之间是否有联系(通过有直接联系的人可以联系到一起)。通常情况下会采用深度优先或者广度优先算法,复杂度为O(n^2)。如果多次调用这个方法就会使得运行时间过长。分析可知只要确定两人是否在同一个连通分量就可以判断,因此可以设置属性表示连通分量,然后在addPerons和addRelation中维护连通分量,在isCircle中直接调用对应结果就可以了。 |
| 多个容器属性交互的方法 | NetWork中的sendIndirectMessage | 对于JML描述中复杂度为O(n)的实现,直接按照JML实现即可。对于一些极其复杂的操作则考虑进行改进,例子是NetWork中sendIndirectMessage方法求最短路径的操作。通常方式是直接使用迪杰斯特拉算法进行求解,但该方法复杂度为O(n^2),直接使用会导致复杂度较大,因而可以使用堆优化的迪杰斯特拉算法降低复杂度。考虑到使用迪杰斯特拉算法需要的数据管理比较复杂,因此专门设计了一个迪杰斯特拉类来处理相关问题。 |
二、测试方法与策略
-
使用Junit进行测试
-
针对每个类的JML中的不变式,编写检查不变式的方法,后续测试进行前或进行后都需要调用不变式检查
-
对每个方法的前置条件进行划分,针对各个划分构造相应的测试数据,然后给出相应的结果,写入Junit测试类进行测试
-
单元测试完成后构造常见的测试场景,调用多个方法进行测试
-
前述测试都只是针对方法的正确性,之后需要测试方法的性能。具体方法是重复多次调用某些方法,查看其是否可能超时。同时结合源代码,从理论上分析方法的复杂度。对于复杂度高且容易超时的方法需要寻找复杂度更低的方法。
三、容器选择
容器优劣分析
我在这次实验中主要使用了三种容器:HashMap,HashSet,ArrayList。这三种容器的特点如下:
-
HashMap:存储在HashMap中的对象需要一个主键进行索引,具体到这次作业中就是每一个对象需要有一个唯一的id。同时HashMap中的对象是没有顺序的,也就是说无法记录被存储对象加入HahsMap的顺序,如果符合这些要求就推荐使用HashMap。尽管有着这些限制,但HashMap提供了很高的查询和修改速度。
-
HashSet:相对于HashMap不需要主键,因此无法根据对象的部分信息在HashSet中快速查找对象,只能遍历。HashSet的优势在于能够快速查找某一对象是否加入了集合。
-
ArrayList:虽然相对于前两者效率最低,查询和修改具体对象需要依靠遍历,但是不需要依托于主键,同时可以记录对象加入容器的顺序。
具体容器使用
下面具体分析我在这次作业中使用的容器。
为了提高效率,优先使用HashMap和HashSet。具体例子为:
-
Perosn中使用HashMap存储熟人列表以及相应的权值列表
-
NetWork中使用HashMap存储在NetWork中的Perosn,Message,Group等。
-
NetWork中使用HashSet存储属于一个连通块的Person
上述使用HashMap的情况都有一个共同点:存储在HashMasp中的对象都有一个唯一的id进行识别,因此可以使用HashMap存储。
使用HashMap可以显著提高查询和修改相应对象的速度,从而提高效率。同时由于HashMap中有着丰富的基本方法(例如containKey),这样在实现某些JML方法的时候可以直接调用,也降低了编程难度。
我在Person中使用了ArratList存储了Message,原因是Person里面的getReceivedMessages方法需要获得前四个被接受的信息,因此只能用ArrayList存储。
四、性能问题分析
第一次作业
性能问题主要出现在NetWork类中的isCircle方法和queryBlockSum方法。isCircle方法计算两个Person是否在同一个连通分量当中。而queryBlockSum计算连通分量的数目。我在isCircle中使用了广度优先算法来计算两个Person是否在同一个连通分量中。由于广度优先算法的复杂度是O(n^2),因而如果构造一个拥有很多Person的网络,并且选择合适的两个Person调用isCircle方法,就会使得运行时间过长。而在queryBlockSum中也使用了广度优先算法,同样会有上述问题。
事实上广度优先算法还会产生占用内存过大的问题,因为在该算法运行的过程中会不断递归产生调用栈,一旦递归层数过大,就会使得占用内存过大。
改进方法是使用并查集算法,建立特定属性记录连通分量。每当网络发生改变时(例如调用addPerson,addRelation),就对连通分量进行维护。当调用isCircle和queryBlockSum时,就可以使用该连通分量属性,大大节省了运行时间(最初超时的数据点从3s降低到了0.2s),也有效减低了占用的内存(从170M降低到了30M)。
第二次作业
性能问题主要出现在Group类中的getValueSum方法。该方法用于计算一个Group中所有Person之间的value值的和。如果直接使用for循环遍历,那么就需要两层,复杂度O(n^2),如果Group过大,也会使得运行时间过长。
改进方法是在Group中设置一个valueSum属性记录所有Person之间的value值的和。每当在Group中加入或删除了一个Perosn(调用addPerson或delPerson),就对valueSum进行维护。如果这些Person之间的关系发生了改变(NetWork中的addRelation),也需要进行维护。这样在调用getValueSum方法时候就直接返回valueSum值就可以了,而不需要重复进行二重遍历计算。
第三次作业
性能问题体现在NetWork中的sendIndirectMessage方法,在这个方法中需要计算两个Perosn结点之间的最短路径。图论中一般使用迪杰斯特拉算法解决这个问题,复杂度O(n^2),可能超时。
改进后使用堆优化的迪杰斯特拉算法,具体就是使用小根堆存储各个Person到源结点Person的距离。这样每次按照迪杰斯特拉算法取距离源结点最短的结点时,就只需要花费O(logn)的时间,而优化前需要花费O(n)的时间。这样最终的复杂度为O(mlogm),m是网络中边的条数。事实上,这种方法当一个网络中的边十分稠密的时候,复杂度会达到n^2logn^2,反而增加了复杂度。但是考虑到测试数据给出了边的条数的限制(不超过10000条),这样就使得网络的规模要么很小,要么很稀疏。因此堆优化的迪杰斯特拉算法就能够拥有较好的效率。
五、架构设计
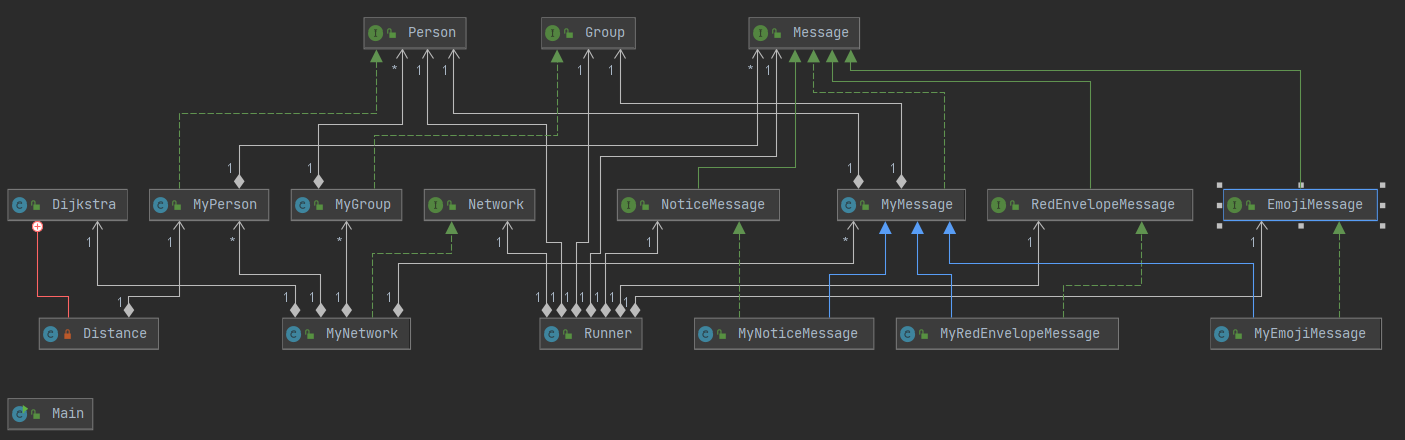
从总体架构上看,这次作业的架构比较清晰。NetWork作为一个容器和管理者,管理了Group,Message,Person三个类。Runner作为与外界交互的类,如果需要进行操作的话只能调用NetWork中的方法。然后由NetWork根据自身的方法调用其管理的Group,Message,Person对象进行相应计算,然后给出相应的结果。Group的作用是将NetWork中的Person进行划分形成子图。
图模型构建与维护
在本次作业中,Perosn就是图中的结点,而NetWork的作用是对图进行管理并且给这些Person结点提供了一个交互的平台。
从数据结构的角度看,作业中的关系网络图采用了邻接表的方式进行构造,每个Person结点存储了与其邻接的Person结点。
在上述过程中已经建立起了图最基本也是最重要的信息——结点和边,理论上已经能够求解所有有关图的问题了,但是在某些具体问题上只依靠这些信息,就会使得效率很低,因此需要在此基础上进行一些补充。
补充描述连通分量的数据结构

为了描述连通分量,我在NetWork中加入了numToBlocks属性进行存储,采用了HashMap。其中每个连通分量都有唯一确定的序号,而连通分量的具体实现就是一个包含了多个Person的HashSet。为了能够让每一个Person能够方便地查询自己所在的连通分量的序号,我又在Person中加入了blockNum属性进行记录。

每当图中的连通分量发生改变、也就是调用了addPerson和addRelation时,我就会对连通分量进行相应的维护,具体如下:
-
在addPerson中:每当新加入一个Person节点,由于其本身是一个孤立节点,因此单独成一个连通分量,给其编上不会重复的序号之后加入numToBlocks进行管理。
-
在addRelation中:如果新加了关系的两个节点之前不在一个连通分量,则将两个连通分量合并,然后更新其中的Person的blockNum。
有了上述操作,就建立起了一个便于使用并查集算法的数据结构,使得isCirlce和queryBlockSum的实现变得很容易。
在Group中补充了记录其中所有关系的value值之和的属性
Group实际上是NetWork的一个子图,其中的getValueSum需要计算其所有的value值之和。每次都进行遍历不是一个很好的方法。因此设置下列属性进行记录:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号