
OO第一单元总结
2021 OO第一单元总结
1. 代码架构与度量分析
1.1第一次作业
1.1.1基本思路
第一次作业比较简单,因子只有常数项与幂函数两种,且表达式模式单一:因子通过“*”连接构成项,项通过“+/-”连接构成表达式。
先将表达式的字符串预处理,达到以“+”作为项的分隔符的效果,而对于每一个项,都可通过计算简化为 (常数项*x**指数) 的形式,之后只需将多个项交给表达式统一求导相加即可。
1.1.2代码分析
1)类图:
Expression:
属性:full:表示该表达式的字符串
Map:存放Term,key为项中x的指数
方法:analys:解析表达式,将表达式拆分为项存储
printanswer:将存储的项求导、优化、相加输出
Term:
属性:full:表示该项的字符串
term:常数项
exp:指数
方法:calculate:解析自身字符串,计算出常数项与指数
2)度量分析:
代码规模分析:

第一次由于要求较少,代码行数较少。
类复杂度分析:
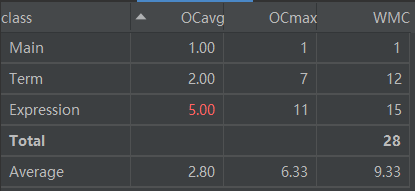
Expression类复杂度很高,原因是受面向过程编程习惯的影响,把类内有的方法写得过长,完全可以拆分。
方法复杂度分析:

可以看出Expression.prinanswer复杂度很高,原因是把求导、化简、输出全部放到了一起,通过大量条件语句判断各类情况
3)作业分析
优点:整体来说基本具备面向对象的思想,思路清晰。Expression类只负责解析,将字符串拆分成项后交给Term类,Term处理自身后交还给Expression类统一管理
缺点:个别方法处理上还是面向过程的习惯,导致方法冗长;
没有考虑增量开发,后续作业只能重写;
1.1.3bug分析
在优化输出时,众多情况中,对于x**2求导后只留下x这种情况,常数项与x之间忘记加“*”,导致所有出现x**2项的数据点全部爆炸
问题出在了圈复杂度较高的printanswer中
1.2第二次作业
1.2.1基本思路
本次作业加入了三角函数与表达式因子,也就是说存在嵌套的情况,不过sin和cos还只有最简单的sin(x),cos(x)情况。
每一项仍然可以化为统一形式:常数*x**(x指数)*sin(x)**(sin指数)*cos(x)**(cos指数)
将表达式和项和因子全部看成为Func类,用map管理多个上述统一形式,key为(x,s,c)分别表示三种指数,key对应值为常数
采用递归下降处理嵌套问题,由于当时对继承、接口等理解不够透彻,故没有采用清晰的架构处理,而是在递归解析字符串的过程中通过Func中定义的add、sub、mult方法直接计算,得到新map
这样在递归完成后,即可得到一个已经拆完括号并合并后的表达式,该表达式由多个“常数*x**(x指数)*sin(x)**(sin指数)*cos(x)**(cos指数)”项组成,通过map管理,只需逐个求导相加输出即可
1.2.2代码分析
1)类图:
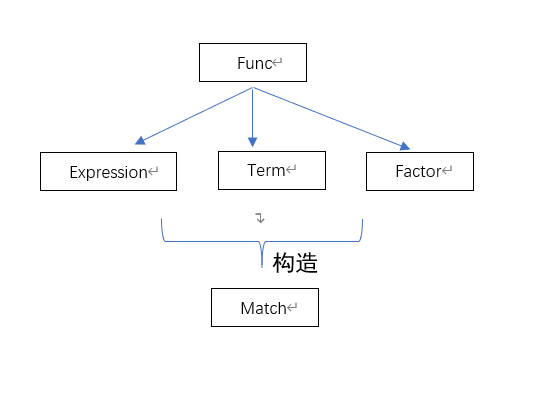
Func类:
属性:map:存储化为统一式 常数*x**(x指数)*sin(x)**(sin指数)*cos(x)**(cos指数) 的多个式子
实现了加、减、乘法,支持任意Func间的计算,可以生成新map
Expression、Term类均视为Func类,无特殊功能
Factor类:
继承自Func类,当匹配到最简单因子时可以调用其构造方法
Match类:
文法分析器,用于按照文法递归下降匹配表达式、项、因子
2)度量分析
代码规模分析:

由于把Factor,Term,Expression全部统一为Func,由Func实现所有功能,可以看到Funcl类代码规模较大。
类复杂度分析:
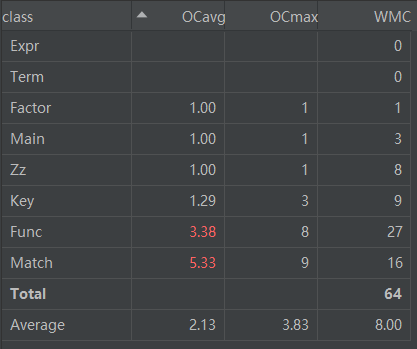
可以看到Func,Match两个类复杂度较高,因为表达式、项、因子的全部功能均由Func实现,全部分析构造均由Match实现
方法复杂度分析:
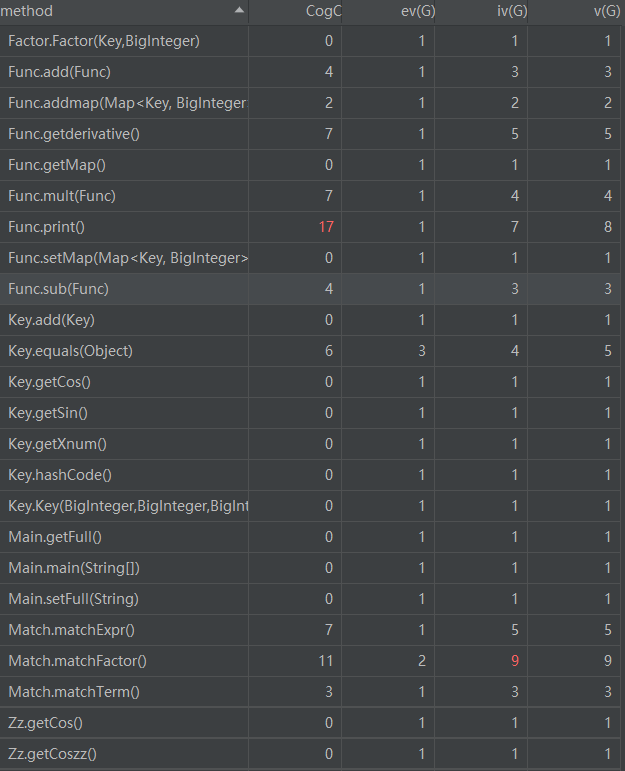
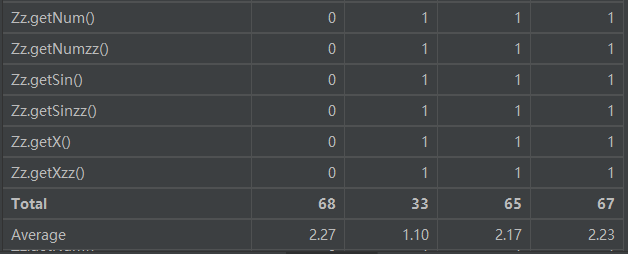
可以看到Func.print和Match.matchFactor两个方法复杂度较高,主要是这两个方法的实现较为面向过程,存在大量if语句枚举,没有进行划分
3)作业分析
优点:就本次作业而言,我认为我的方法是比较好的,很好的将所有项、表达式、因子化为统一形式,用map管理并实现map间的运算,在递归下降的过程中直接计算,直接得到去括号并合并的表达式
性能上比较好,从的得分来看大部分数据能得到很高的分数。
缺点:具体方法仍旧有面向对象的习惯,且这次虽然可以将所有类统一化,但没有考虑增量开发,下次仍旧要重写。
1.2.3bug分析
为了优化,直接将常数项为0的项从map中删去,导致结果为零的数据没有输出。
这个bug感觉不是某个方法的问题,是确实忘了有输出为了0的情况
1.3第三次作业
1.3.1基本思路
本次作业作为表达式求导的最终版,要求支持三角函数嵌套、三角函数乘方,仍旧采用递归下降,按照类型层层构建,实现每个类的求导。
通过hashmap管理来实现合并,重写所有类的hashcode,equals方法
在之前作业原有类基础上,对于每一种因子(常数、幂函数、三角函数、表达式因子),建立类,全部继承自Factor,覆写求导方法。
至于格式问题则只需在两处判断,一个是递归下降到最底层时若没有成功匹配则WF,另一个是匹配完成后若字符串还为匹配完全,则WF
1.3.2代码分析
1)类图:
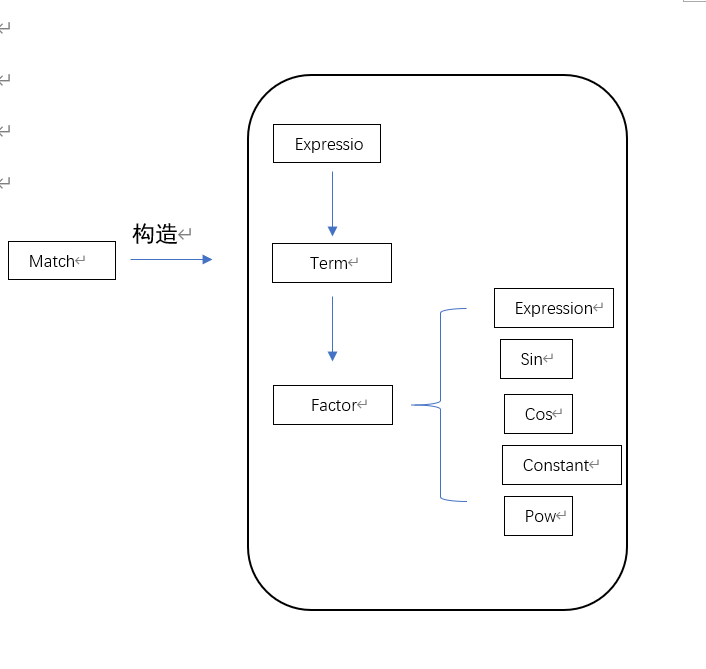
Factor类:
属性:指数exp
是众多因子所继承的父类,类中定义求导函数,供子类覆写。
Expr类:继承自Factor
属性:hashmap 管理 Term
表达式类作为项的上一级需要通过hashmap管理项,同时作为因子需要实现求导(多项求导相加)、输出等方法
Term类:
属性:hashmap管理Factor
constant单独存储该项的常数部分,同时也方便项之前的符号决定加减,若为减号,常数部分乘-1即可
Term类通过hashimap管理Factor,项的求导为乘号相连的因子求导
Sin,Cos,Pow,Constant类:继承自Factor
这些类除了个别属性不同基本相似,作为各种因子实现求导方法,其中Sin,Cos的求导为嵌套求导
Match类:
文法分析器,用于按照文法递归下降匹配表达式、项、因子
2)度量分析
代码规模分析:

还是Match的老问题,把所有的匹配方法全部放在了Match中
类复杂度分析:
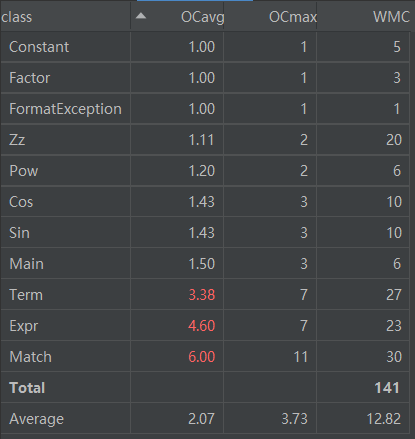
可以看到Term,Expr,Match复杂度较高,Term,Expr输出与简化没有分开,求导也因为格式问题存在条件判断的情况。
Match则由于文法变得更加复杂,需要更多的判断。
方法复杂度分析:
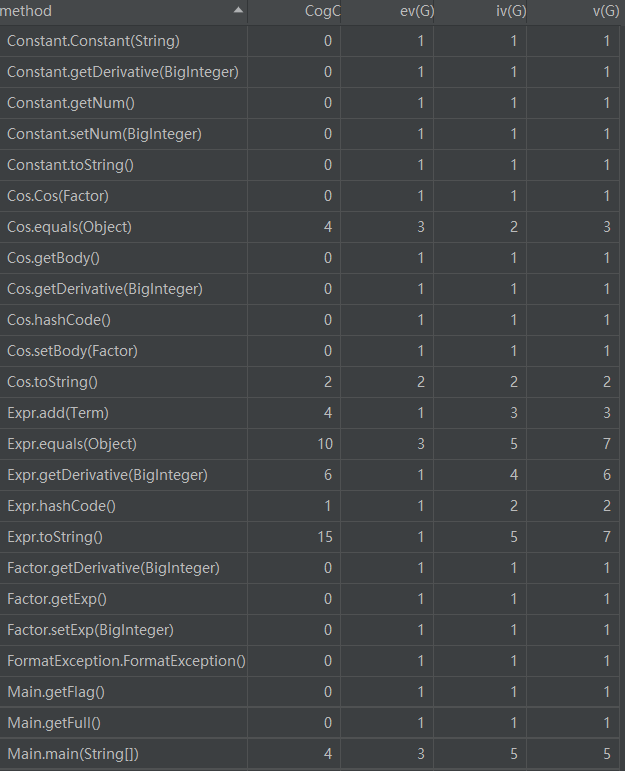
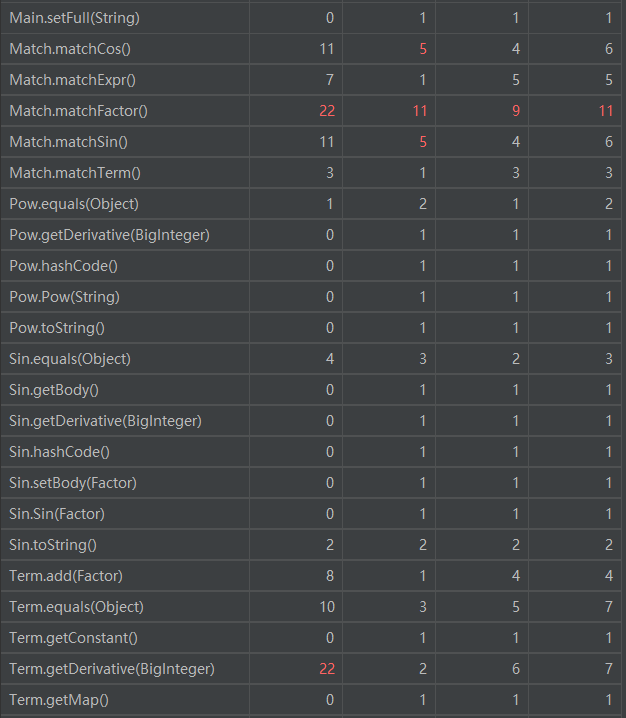

可以看到,Match.matchFactor,Term.getDerivative复杂度较高。
matchFactor匹配因子时涉及到所有种类因子的判断与匹配。
Term的求导函数则因为是多个因子相乘求导且直接转换为字符串,所以涉及多种条件判断。
3)作业分析
优点:对于表达式的解析采取了较稳清晰的架构,同过hashmap实现化简,解析的同时化简,求导则直接转换为字符串,最后再对求导后的字符串解析化简并输出,不需要其他化简方法
缺点:虽然不需要独立的化简方法,但就是由于把太多的工作放在了一个类或者方法中,导致个别类或方法过于复杂,容易出错,分工不够独立化、不够清晰。
1.3.3bug分析
没有考虑到括号不匹配的问题
化简和解析同时进行导致代码复杂,出现细节问题
2. 发现别人Bug采用的策略
限于个人水平,不会用自搭评测机,采取的手测的方式。
首先,测试自己在作业过程中重点考虑过的bug可能数据
然后随机读代码判bug,根据代码的架构,以及看起来较乱的部分重点测试(虽然结果来看并没有收获)
3.重构经历总结
与其说重构经历,不如说重写经历,虽然有意的熟悉、尝试了面向对象编程,尽量将工作分工给各个类,但由于缺少对后续拓展的考虑,导致每次都是重写。
第一次作业不存在表达式因子,整个表达式只有表达式、项、因子的单项结构,直接使用正则表达式便可做到解析。
第二次作业使用了递归下降解析表达式,想出自认为比较巧妙的统一形式,并通过map管理与计算,性能分较高,但是没有考虑后续sin,cos的嵌套情况,使得程序没有可扩展性。
第三次才算正式构建表达式的层次架构,层层管理,在基本理解了继承、覆写等的基础上勉强解决了问题,基本算踏入了面向对象的大门,但是对于分工仍旧不明确。
整体来看,对于类的建立已初步具备面向对象思想,但是对于方法的定义还是受面向过程的影响,总想着把多个工作同时在一个方法中完成,导致代码复杂。
重构时应着重注意方法间的独立性。
4.单元心得体会
由于假期没有充分预习,第一单元一路走来可谓是充满艰辛,对于难度增长较快的第一单元(尤其是第一到第二次),在思考作业如何完成的同时,还要努力地习惯Java
这个新语言,学习list,map的用法,hashcoed等方法的重写,继承、接口概念的理解,来不及为后续考虑,导致每周都要重写,工作量挺大的。
但在一顿摸爬滚打中还是度过了第一单元,学到了许多东西,在压力下快速熟悉了Java,基本掌握了各类集合的用法,对接口、继承、覆写等有了实践基础上的理解,理解并掌握
了递归下降的算法,找到了点面向对象编程的感觉,可以说收获满满。
对于第一次和第三次作业,性能其实都还行,但由于细节问题导致强侧有些数据点没过,最终得分并不高,挺可惜的,之后的作业需要更加的细致,不能只满足于不靠谱的中测, 自己多进行测试。
与同学讨论是个很棒的学习方式,大家各自分享自己的思路,互相参考可以借鉴的思路,对完成作业很有帮助。特别是对于我这种没有充分预习,还在摸索阶段的同学,在研讨课
这种大佬分享经验的场合基本插不上话,课下与水平相似的同学互相讨论一起学习真的很有帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号