面向对象程序设计第一单元总结
一、写在前面
”摸着石头过河“,这句话是我三次作业以来体会最深的思想,也是我在回顾三次作业时最真切的感受。OO要改变的是思维方式,这个过程是很漫长的,有很多方面都不适应,就像是要让你过河,却不让你像以往一样走桥,或者说根本没桥,那该怎么到达对岸呢?我认为就是要大胆探索、稳妥前进,浓缩起来就是那句老话”摸着石头过河“。
二、程序结构
本部分主要是对我三次作业的度量分析以及对其优缺点的自我评判。在给出UML图之前会配上一段文字简要说明每个类的设计考虑,而宏观的架构考量过程和实现细节在第五部分给出。
2.1HW1
2.1.1类构建思路描述
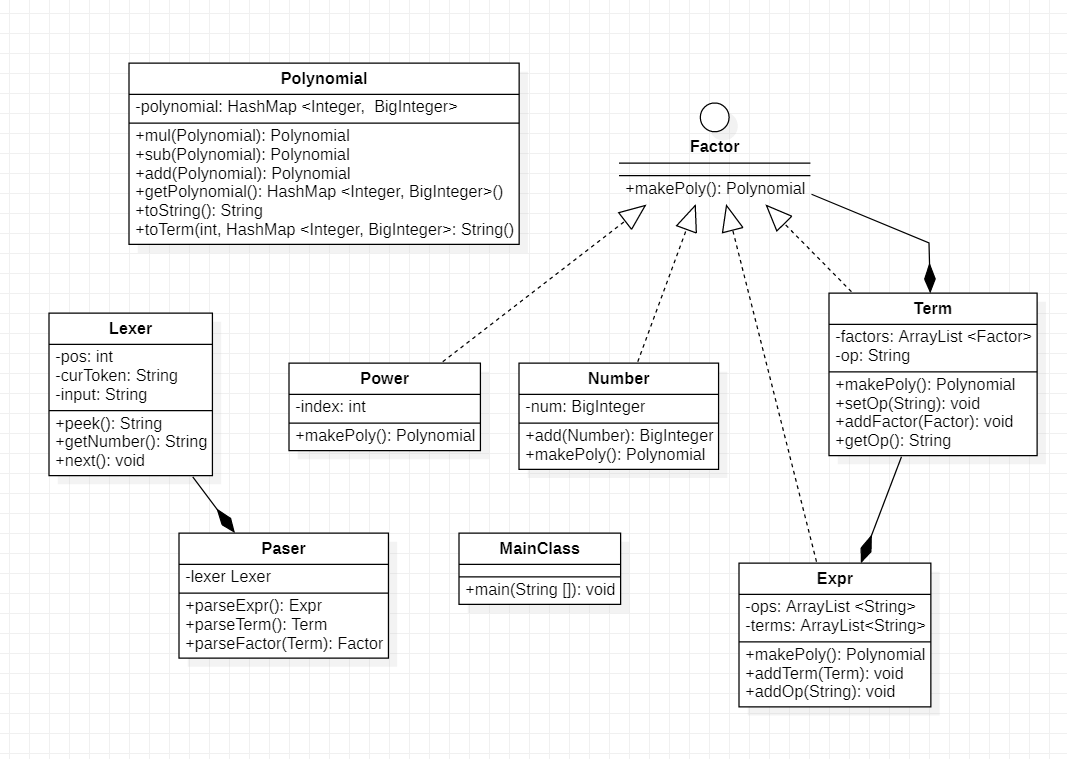
第一次作业我除MainClass类外实现了8个类,用两句话可以总结我的设计考虑:
-
采用梯度下降的解析方法(
Paser和Lexer)对表达式建模,整个表达式分为3层:Expr、Term、Factor,而Factor又包括Number、Power(幂函数)、Expr。 -
为了计算处理的方便,表达式内部的类都实现Factor接口,从而都可以视为一个统一的抽象类,进而统一构造成多项式类
Polynomial
以上两句话分别代表了笔者第一次作业思路的两个阶段,即解析和计算,这也是我后续迭代开发的基础。
2.1.2UML图
2.1.3类复杂度图
OCavg = Average opearation complexity(平均操作复杂度)
OCmax = Maximum operation complexity(最大操作复杂度)
WMC = Weighted method complexity(加权方法复杂度)
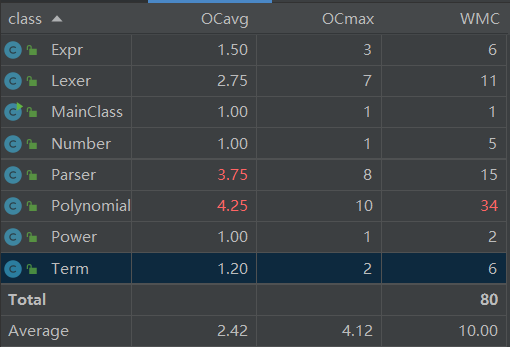
从图中可以看出Paser和Polynomial的复杂度较高,这与我的思路有很大关系:解析部分主要由Paser实现,计算部分主要由Polynomial实现。承担大部分工作而造成的复杂度增加似乎像是一种成功的”代价“,我会在未来继续探索对这一问题的改进方式。
2.1.4方法复杂度图
CogC = Cognitive complexity(认知复杂度)
ev(G) = Essential cyclomatic complexity(基本圈复杂度)
iv(G) = Design complexity(设计复杂度)
v(G) = cyclonmatic complexity(圈复杂度)
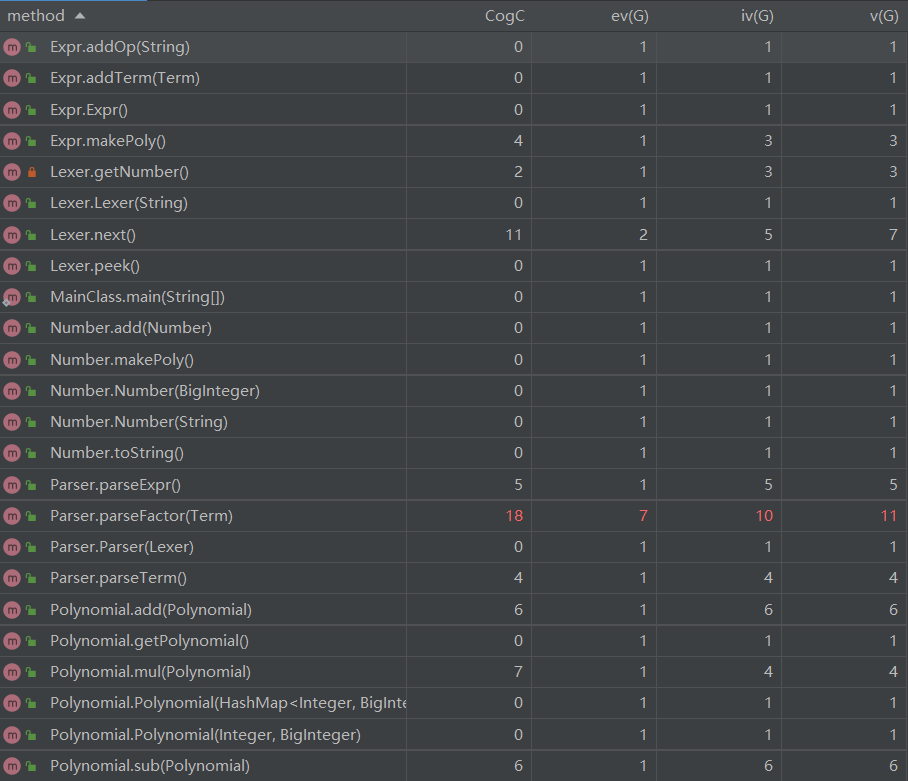

分析图可以看出,paserFactor和Polynomial.toTerm复杂度较高,前者的客观原因是因子本身种类较多,但也有我写法的主观因素(部分代码耦合度太高),而后者则是我定义的关于输出的优化方法,当时并没有考虑复杂度,在之后的迭代开发中对此段代码有所优化。
2.2HW2
2.2.1类构建思路描述
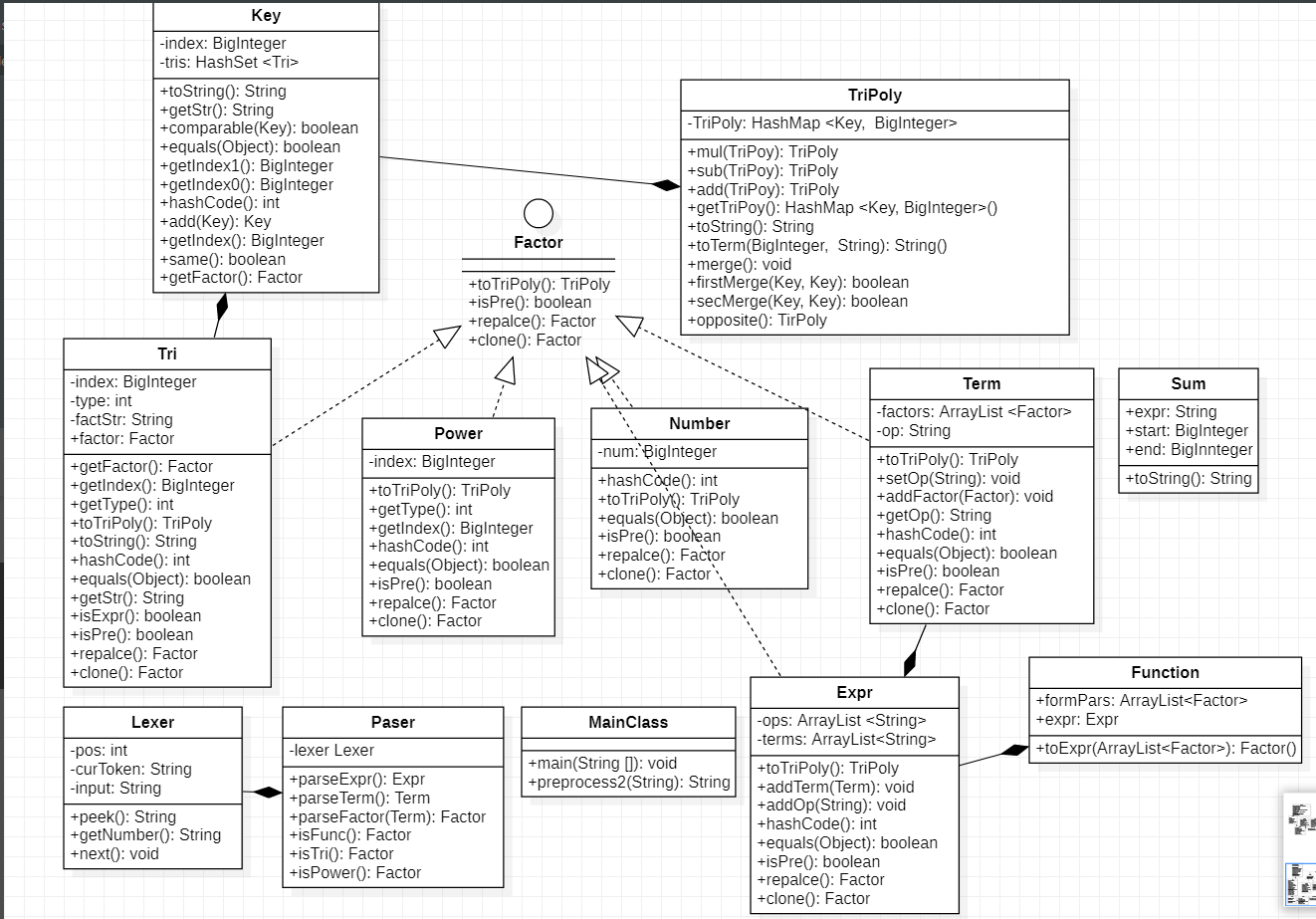
第二次作业加入了三角函数和自定义函数及求和函数,我在code1的基础上进行了迭代开发。类新增了4个,包括Function、sum、Tri,分别处理新加入的自定义函数、求和函数、三角函数,而对于key类,内部存储了x的指数以及含有三角函数的HashSet,这是我第一次作业到第二次作业过渡的重要实现,在此基础上升级Polynomial类为TriPoly类,进而可以支持三角函数的相关计算。
2.2.2UML图
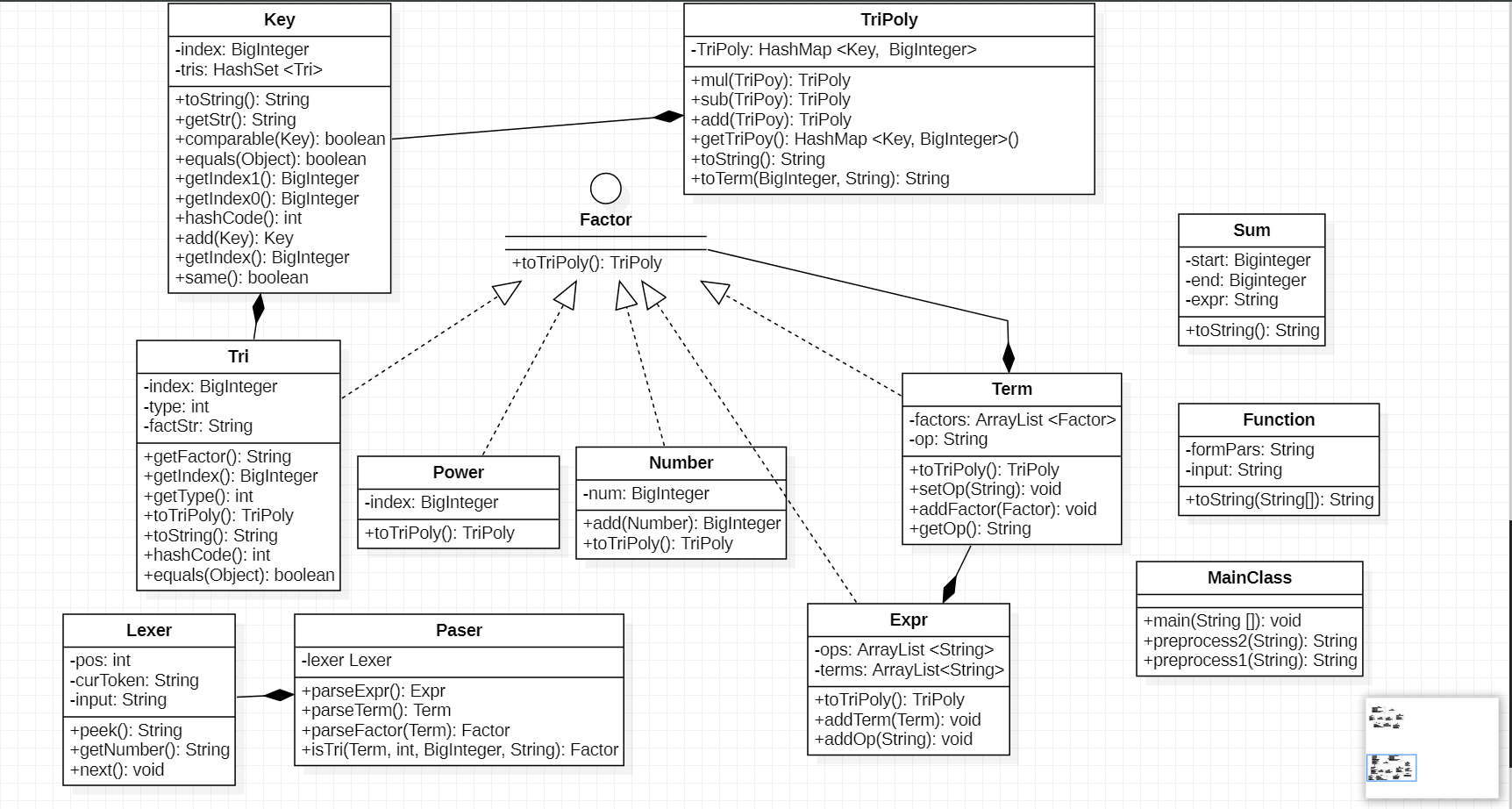
2.2.3类复杂度图
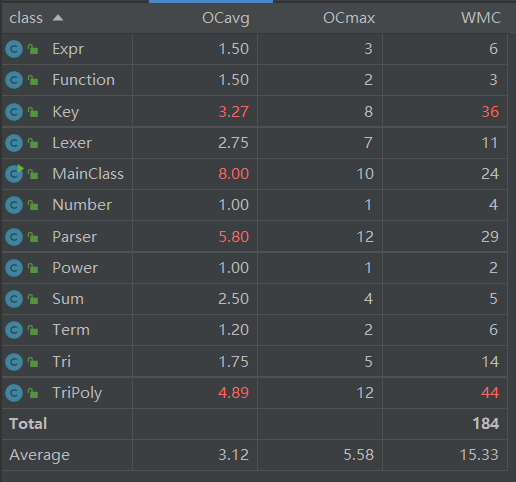
从图中可以看出,TriPoly和Paser的复杂度依然较高,这与第一次作业的原因相同。而MainClass类复杂度较高的原因是本次作业我针对自定义函数和求和函数采用的策略是字符串替换(而且写在了MainClass中,有些欠考虑,在第三次作业中已经改为深克隆基础上的因子替换)。key类的复杂则主要是因为三角函数的合并以及化简(在第二次中我初步尝试并实现了平方和优化)都与该类有密切关系。
2.2.4方法复杂度图

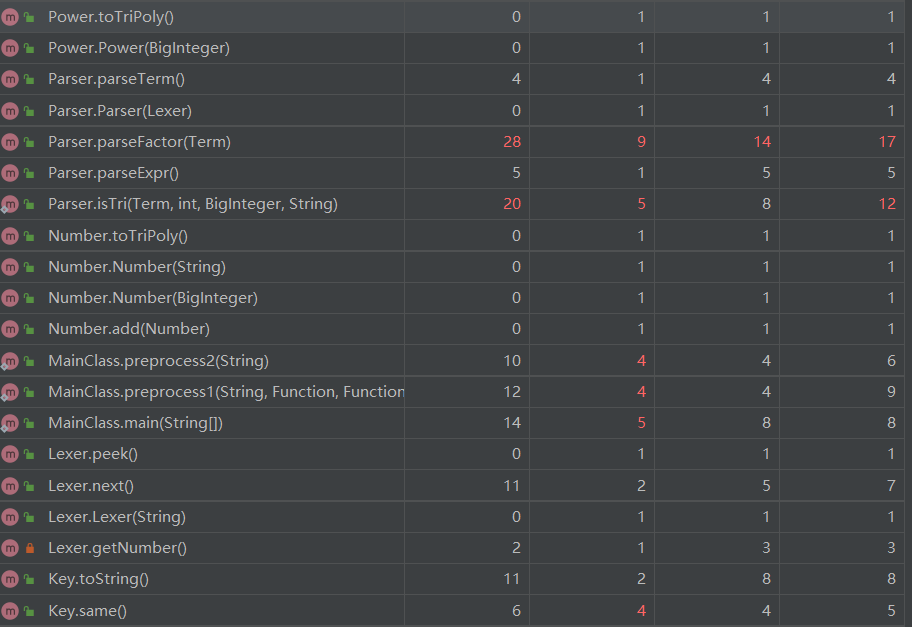
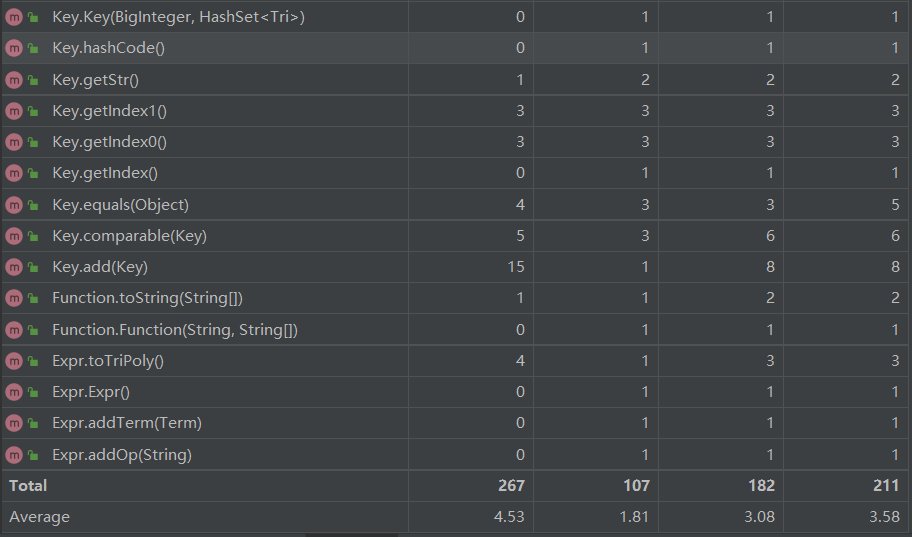
经过分析,TriPoly.merge方法复杂是因为在这里用比较粗糙的方法实现了平方和优化,公式如下(借鉴于学长的博客):https://www.cnblogs.com/tqnwhz/p/10559893.html

paserFactor随着因子种类的增多进一步复杂是在意料之中,而isTri方法是我为优化三角函数的负号以及一些特殊情况写的方法,或许还有更好的实现方法。
2.3HW3
2.3.1类构建思路描述
在做第二次作业时就预感到第三次作业会出现递归嵌套以及三角函数内部将变为各种因子,因此在第二次时尝试了深度克隆基础上的因子替换以及三角函数内部支持各种因子。基于此,第三次代码的类与第二次类的设计完全一致,但内部实现有了很大区别。
2.3.2UML图
2.3.3类复杂度图
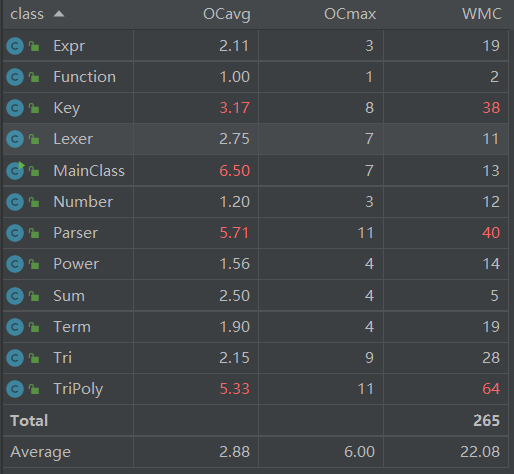
将字符串替换方法改进之后,发现MainClass类的复杂度明显降低(不过由于自定义函数建模和求和函数预处理我还是写在了MainClass中,导致它的复杂度依然很高,这点需要改进,或许可以新增加一个类来实现)。TriPoly类因为本次作业我加入了更多优化导致其负担更重略微增加了复杂度,其他两类的复杂度都有下降,但仍有提升空间。
2.3.4方法复杂度图
由于方法比较多不再展示完整复杂度图,仅展示部分复杂度较高的方法。
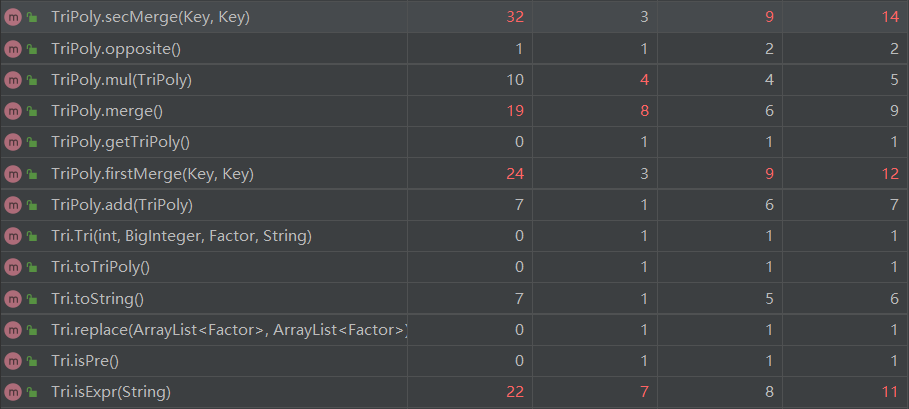

其中Merge、firstMerge、secMerge三个方法是三角优化的主体,Tri.isExpr是三角函数括号输出优化的方法,而虽然对于PaserFactor已经进行了优化,但依然像以往一样比较复杂。
三、bug分析
-
己方bug分析:笔者在三次作业的强测和互测均未出现bug。但是在自己调试时,出现过深度克隆问题(复现方式为自定义函数多次调用)、
HashSet容器边遍历边删除造成空指针、字符串替换考虑不周、优化过度导致连锁bug、对象类型理解不清晰等一系列问题,这些bug显示出我在做题时对题意的把握以及java语言本身的部分特性理解并不是十分透彻,希望未来能有精进。 -
对方bug分析:笔者在三次hack中共发现了对方四个bug,分别是:
-
sin(0)/cos(0)未输出,原因是处理sin中0时欠考虑。
-
11*x被输出为x,原因是使用正则表达式搜索1x并替换为x。 -
sum(i,1,2,i**2)计算错误,原因是处理sum函数的i时欠考虑。 -
sin(x)**2+cos(x)**2+x输出错误为x,原因是过度优化平方和。
四、hack策略
笔者在第一次hack中采用了阅读他人代码并分析其中漏洞的方法,虽然从中学到了不少优秀的架构,但是这样的方法hack效率略低,导致我第一次并没有找到对方的bug(也有可能是第一次作业比较难出bug)。到了第二次hack,我在原方法的基础上附加了自动生成数据以及自动评测机的方式hack,不过最终是依赖阅读他人代码迅速定位的bug,评测机只是辅助作用。第三次hack,我还尝试了讨论区同学分享的单个数据同时测试房间所有同学bug的评测机http://oo.buaa.edu.cn/assignment/329/discussion/1140,并找到了部分bug。结合三次hack的经历,我认为比较好的策略是:
-
尽量在自己设计的过程中记录可能出现的bug,并构造数据。
-
阅读他人代码,寻找薄弱处hack,例如高密度的正则表达式、字符串替换。
-
设计数据生成器及自动评测机,提高效率,但是应保证数据的覆盖性。
五、架构设计体验
本部分主要是笔者对三次作业架构的宏观思考和实现细节,集中了一些作业过程中的困惑与对应的解决方法。
5.1HW1思考过程
5.1.1关键点
-
递归下降解析法:主要参考的是训练栏目的实现方式,训练部分的思路帮到了我很多。
-
多项式统一处理计算:开始时我一直想不通(1+x)*(1+x)该如何计算,直到有了多项式统一处理的思路才豁然开朗,这一部分也是我应对整个第一单元的基础。
-
HashMap存储:有了多项式统一处理的抽象思路,具体到如何合并同类项则又考虑到使用hashmap这一容器,利用key存储x的指数,value存储对应的系数,这样就轻松地实现了多项式乘法、加法和减法。
5.1.2其他细节
1.对符号的处理:
表达式开头会有一个可能出现的符号,而每两个项之间也会有正负连接符,因此在表达式内可定义存储符号的Arraylist,并默认表达式前符号缺省为正,这样保证符号数组和项的数组长度一致。
项的开头同样会有一个可能出现的符号,但每两个因子之间只会有乘号,因此可以只记项的开头的符号作为项本身的符号,同样默认缺省为正。
如果构造是递归到因子层面仍有符号,那一定是因子本身的符号,例如:---1
按照上述处理,第一个负号作为表达式层的符号,第二个负号作为项的符号,第三个则对应1
2.对幂次的处理:
对于幂函数,类似常数构造了一个类Power来存储,在Lexer()函数中可针对x进行特殊处理
对于表达式带幂次的情况,在读完右括号后,立刻读取其后是否可能存在指数,如果存在指数,则直接将该表达式因子重复加入对应的项中。也就是把(1+x)**2直接展开成了(1+x)*(1+x)。
3.多项式构造细节:
-
如前所述,将表达式构造为多项式可以转换为将表达式的所有项合并,由于项与项之间由正负号连接,而且每一个项也构造成了多项式,所以这一层实际只是多项式的加减法。
-
将项构造成多项式可以转换为将项的所有因子合并,由于因子与因子之间由乘号连接,而且每一个因子也构成了多项式,所以这一层实际只是多项式的乘法。
-
将因子构造成多项式就是几个基本因子(常数、幂函数)的转化,如果是表达式因子则回到第一步。
5.2HW2思考过程
5.2.1关键点
-
多项式拓展:这一点是专门为了处理三角函数而实现的,保证了我能在hw1的基础上继续进行迭代开发而不是大规模重构,主要是创建Key类,Key中存储x项指数及三角函数的集合。
-
字符串替换:这一点是最初对于处理自定义函数和求和函数的思路,因为成型较早,故选择在hw2中保留,但在hw3中修改弃用。
-
三角优化:在解析阶段做了
sin(0)->0、sin(-1)变为-sin(1)、sin(x)**4*cos(x)**2+sin(x)**2*cos(x)**4 = sin(x)**2*cos(x)**2等优化。
5.2.2其他细节
1.关于三角多项式的乘法实现:
-
系数相乘:不变。
-
指数相加:分为两部分,首先是x指数相加;其次是三角函数集合的合并(同类三角函数指数相加)。
由于需要比较键值key,故需覆写equals方法(hashcode方法)。
2.采用字符串替换的方法需要注意形参出现的顺序,特别地,形参中若有x则将x全部替换为w。
5.3HW3思考过程
5.3.1关键点
-
递归下降解析自定义函数:解析过程为因子层面的替换,将函数表达式逐级递归到因子层面,对比因子与形参,若相等则替换。
-
优化三角函数:实现了以下的优化:
//合并
sin((1)) + sin(1)
sin((sin(x)**2+cos(x)**2)) + sin(1)
//sin(x)**2 + cos(x)**2 = 1
sin(x)**4*cos(x)**2+cos(x)**4*sin(x)**2
cos(x)**2-1
cos(x)**3-cos(x)
//取反
sin((-x-1))+sin((x+1))5.3.2其他细节
1.深度克隆替换的四个细节:
-
形参只可能与幂函数因子相等,而幂函数因子只可能出现在表达式因子、幂函数和三角函数中,此处相等条件应为类型相等
-
由于形参只可能替换幂函数因子,故有可能会有指数,此时需将指数赋予实参,策略是按指数将实参加入项中多次。(此处虽然没有进行克隆,但是由于本身带指数的表达式因子就有相关性,似乎没有问题)。
-
实参应为表达式因子,目的是优化三角函数的符号时沿用之前的提到项一级的思路
-
最终替换得到的表达式因子是有很多问题的,比如多层嵌套、sin(0)、cos(0)等等,为了简化表达式树层次,省去sin(0),将该表达式因子进行格式化重构(牺牲时间换取简化)
2.三角优化的细节:三角函数内部应为表达式因子,根据内部因子输出结果的字符串判断是否取反:
具体为判断首字符是否为负号,若是则将hashmap中所有系数取反,并解析新的表达式因子。
六、结语及体会
首先感谢本次作业的过程中帮助我的同学和助教,今后面对更大的挑战大家还要继续加油。
其次是我本单元的一些反省:一是没能很好地应用实验课的内容到作业上来,比如对sin((1))的处理,按照我的最初的做法会得到嵌套表达式,后来我的策略是对表达式重新解析(remake)了一遍才降低了深度,但这种方法太过简单粗暴,而实验课上的simplify方法则十分适合处理该问题,下次我需要更重视实验与作业结合。二是有关数据测试的相关知识还需要像其他同学学习。
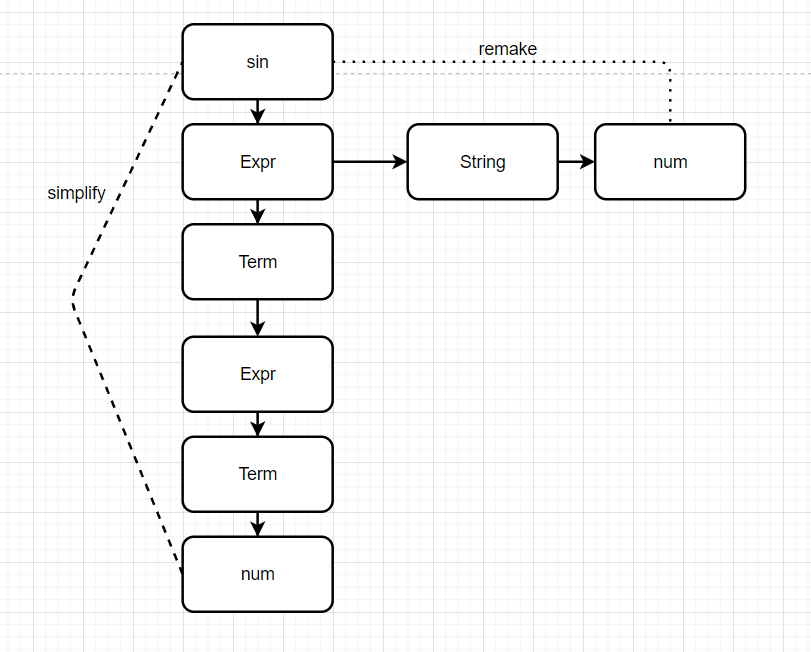
最后,在本次作业中遇到的每一个问题都很有挑战性,我体会到了当没有绝对好的办法时,也要大胆尝试,“摸着石头过河”会比原地踏步或者跟随他人脚步发现更多惊喜。
总之,希望我能在未来更大的挑战前再接再厉,共勉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号