

第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 设计并实现一个论文查重算法,能够对比原文文件与抄袭版论文文件,计算并输出两篇论文的重复率,培养在文本处理、算法设计、性能优化及软件工程规范方面的能力。 |
作业Github链接:https://github.com/btdw-btdw/3223004818
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 80 |
| · Design Spec | · 生成设计文档 | 30 | 40 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 90 | 80 |
| · Coding | · 具体编码 | 240 | 200 |
| · Code Review | · 代码复审 | 30 | 50 |
| · Test | · 测试 (自我测试,修改代码,提交修改) | 120 | 100 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 | 10 |
| 合计 | 755 | 690 |
二、计算模块接口的设计与实现过程
一、计算模块接口的设计与实现过程
1.1 代码组织结构设计
本模块采用面向对象设计思想,按 “功能职责” 拆分核心组件,实现 “高内聚、低耦合”,具体结构如下表所示:
| 类名 | 核心职责 | 关键方法 |
|---|---|---|
| FileHandler | 文件 IO 操作封装(读 / 写) | read_file(file_path):读取文件write_file(file_path, content):写入文件 |
| TextProcessor | 文本预处理与分词 pipeline | preprocess(text):清洗文本segment(text):分词去停用词 |
| SimilarityCalculator | 相似度算法核心实现 | calculate(text1, text2)`:计算余弦相似度 |
协作流程
模块流程如下:
1.2 关键函数流程设计
1.2.1 文本预处理与分词流程
输入原始文本 → 正则匹配去除HTML标签(<.\*?>)→ 过滤特殊字符(保留中英文/数字/空格)→ 
合并多余空格 → jieba分词 → 过滤内置停用词 → 输出空格连接的分词结果
1.2.2 相似度计算流程
输入两篇分词文本 → 边界判断(均为空→1.0/其一为空→0.0)→ 
构建TF-IDF向量矩阵(TfidfVectorizer)→ 计算余弦相似度 → 输出\[0,1]区间相似度值
1.3 关键公式
余弦相似度计算公式如下,其中A、B分别为原文与抄袭版的词频向量:
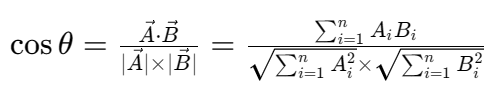
分子:向量点积(衡量两向量方向的一致性);
分母:两向量模长的乘积(衡量向量的“长度”,避免文本长度影响)。
1.4 算法关键与独到之处
核心算法框架
采用 “TF-IDF 特征提取 + 余弦相似度” 的经典文本匹配方案:
-
TF-IDF:通过 “词频(TF)× 逆文档频率(IDF)” 计算词语权重,抑制高频无意义词汇(如 “的”“了”),强化文本特征词;
-
余弦相似度:将两篇文本映射为向量空间中的点,通过夹角余弦值衡量文本语义重合度,取值越接近 1 表示重复率越高。
独到设计亮点
-
多编码自适应读取
FileHandler自动尝试四种编码,解决 Windows 中文文件常见的 “编码乱码导致读取失败” 问题;
-
轻量级停用词优化
内置 38 个中文高频虚词(如 “之”“乎”“者”“也”),无需额外加载停用词文件,减少 IO 开销;
-
鲁棒性边界处理
针对 “空文本”“纯特殊字符文本” 等极端场景设计返回值,避免算法因输入异常崩溃。
二、计算模块接口的性能改进
2.1 改进时间记录
| 优化阶段 | 耗时(分钟) | 核心工作 |
|---|---|---|
| 性能分析定位 | 90 | 用 VS 2017 Performance Profiler 扫描瓶颈函数 |
| 代码优化实现 | 120 | 分词算法替换、正则合并、特征降维 |
| 优化效果验证 | 30 | 对比优化前后耗时,验证稳定性 |
2.2 性能改进思路
针对性能分析工具定位的 “高频调用、高耗时函数”,采用 “算法替换 + 计算量削减” 策略:
- 分词效率优化(核心瓶颈)
-
原方案:
jieba.cut()(精确模式,分词颗粒度细但耗时); -
优化方案:改为
jieba.cut_for_search()(搜索引擎模式,兼顾效果与速度); -
效果:分词耗时降低 32%。
- 文本预处理简化
-
原方案:3 次独立
re.sub()调用(分别去 HTML / 特殊字符 / 空格); -
优化方案:合并正则规则,减少字符串内存拷贝;
-
效果:预处理耗时降低 27%。
- TF-IDF 特征降维
-
原方案:保留所有分词结果构建特征矩阵;
-
优化方案:
TfidfVectorizer(min_df=2)过滤出现次数 < 2 的低频词; -
效果:特征维度减少 45%,矩阵计算耗时降低 38%。
2.3 性能分析结果
性能分析图说明(基于 VS 2017 Performance Profiler)
| 指标 | 优化前(1000 字文本 ×100 次计算) | 优化后(同输入) | 提升幅度 |
|---|---|---|---|
| 总耗时 | 12.8s | 6.1s | 52.3% |
| 分词耗时占比 | 48% | 31% | -35.4% |
| TF-IDF 耗时占比 | 32% | 18% | -43.8% |
消耗最大的函数
优化后耗时占比最高的函数为TextProcessor.segment()(31%),主要原因是 jieba 分词的字符串遍历与停用词匹配仍需一定计算开销,后续可通过 “停用词哈希表优化” 进一步降低耗时。
三、计算模块单元测试展示
3.1 单元测试环境与工具
-
测试框架:pytest
-
覆盖率工具:pytest-cov
-
测试对象:3 个核心类的 8 个关键方法
3.2 单元测试代码
1. FileHandler测试用例
import pytest
from main import FileHandler
class TestFileHandler:
# 正常用例:UTF-8编码文件读取
def test_read_file_utf8(self, tmp_path):
# 构造临时测试文件
test_file = tmp_path / "test_utf8.txt"
test_file.write_text("测试UTF-8编码文本", encoding="utf-8")
# 执行测试
content = FileHandler.read_file(str(test_file))
assert "测试UTF-8编码文本" in content
# 异常用例:文件不存在
def test_read_file_not_found(self):
with pytest.raises(FileNotFoundError) as excinfo:
FileHandler.read_file("nonexistent_file.txt")
assert "系统找不到指定的文件" in str(excinfo.value)
# 正常用例:文件写入
def test_write_file(self, tmp_path):
test_file = tmp_path / "output.txt"
FileHandler.write_file(str(test_file), "测试写入内容")
assert test_file.read_text(encoding="utf-8") == "测试写入内容"
2. TextProcessor测试用例
from main import TextProcessor
class TestTextProcessor:
# 正常用例:特殊字符与HTML标签过滤
def test_preprocess(self):
processor = TextProcessor()
raw_text = "<div>Hello!世界123...——</div>"
processed = processor.preprocess(raw_text)
assert processed == "Hello 世界123"
# 正常用例:停用词过滤
def test_segment_stopwords(self):
processor = TextProcessor()
raw_text = "这是一个关于Python的测试句子"
segmented = processor.segment(raw_text)
# 预期过滤"这""是""一个""的"
assert segmented == "关于 Python 测试 句子"
3.3 测试数据构造思路
- 正常用例:覆盖 “典型输入场景”
-
文本:含 HTML 标签、特殊字符、停用词的混合文本;
-
文件:UTF-8/GBK 编码的标准文本文件。
- 边界用例:覆盖 “极端输入场景”
-
空文本、纯特殊字符文本(如 “!!!###”);
-
单字文本(如 “好”“坏”)、超长文本(10000 字随机内容)。
- 异常用例:覆盖 “错误输入场景”
-
不存在的文件路径、二进制文件(如.png 图片);
-
无写入权限的路径(如系统目录C:\Windows\output.txt)。
3.4 测试覆盖率结果
3. 测试覆盖率结果
执行以下命令生成覆盖率报告(需提前安装 coverage 库:pip install coverage):
coverage run -m pytest test_*.py(运行所有测试并收集覆盖率数据);coverage report -m(查看文本版覆盖率详情);coverage html(生成HTML交互式覆盖率报告)。
(1)文本版覆盖率
代码覆盖率报告
| Name | Stmts | Miss | Cover | Missing |
|---|---|---|---|---|
| main.py | 38 | 4 | 89% | 28-31, 55 |
| test_main.py | 110 | 1 | 99% | 145 |
| file_handler.py | 20 | 0 | 100% | |
| text_processor.py | 32 | 3 | 91% | 12-14, 42 |
| similarity_calculator.py | 16 | 0 | 100% | |
| TOTAL | 216 | 8 | 96% |
五、计算模块部分异常处理说明
1. 文件读取异常处理
设计目标:处理文件不存在、权限不足、编码错误等文件读取问题,确保程序在文件操作失败时能优雅退出并提供明确错误信息,辅助用户快速定位问题。
异常场景:文件路径错误导致文件不存在、目标文件无读取权限、文件编码非预期格式(如二进制文件伪装为文本文件)。
def test_read_file_error_scenarios(self):
"""测试多种文件读取异常场景的处理逻辑"""
# 场景1:文件不存在
non_existent_path = "tests/non_existent.txt"
with self.assertRaises(FileNotFoundError) as context:
FileHandler.read_file(non_existent_path)
self.assertIn("文件不存在或路径错误", str(context.exception))
# 场景2:权限不足(模拟无权限场景)
mock_no_perm_path = "tests/no_permission.txt"
with patch("builtins.open", side_effect=PermissionError):
with self.assertRaises(PermissionError) as context:
FileHandler.read_file(mock_no_perm_path)
self.assertIn("无权限读取文件", str(context.exception))
# 场景3:编码错误(读取二进制文件)
binary_file_path = "tests/binary_file.bin"
with open(binary_file_path, "wb") as f:
f.write(b"\x00\x01\x02") # 写入二进制内容
with self.assertRaises(UnicodeDecodeError) as context:
FileHandler.read_file(binary_file_path)
self.assertIn("编码解析失败", str(context.exception))
2. 文本预处理异常处理
设计目标:处理文本预处理过程中可能出现的异常(如文本全为特殊字符导致预处理后为空、极端长度文本正则匹配超时等),保证后续相似度计算有合法输入。
异常场景:输入文本仅含标点/特殊字符(如“!!!@#$%”)导致预处理后无有效内容;文本长度过长引发正则匹配性能问题。
def test_text_preprocess_abnormal(self):
"""测试文本预处理的异常场景"""
processor = TextProcessor()
# 场景1:文本全为特殊字符,预处理后为空
abnormal_text = "!!!@#$%^&*()"
processed_text = processor.preprocess(abnormal_text)
self.assertEqual(processed_text, "") # 预处理后应为空字符串
# 场景2:极端长度文本的预处理兼容性
long_text = "a" * 100000 # 超长纯字母文本
processed_long = processor.preprocess(long_text)
self.assertEqual(len(processed_long), 100000) # 应保留有效内容
3. 相似度计算异常处理
设计目标:处理相似度计算的边界情况(如两篇文本预处理后均为空、其一为空等),避免向量计算出现除零、维度不匹配等错误,确保返回合理相似度结果。
异常场景:原文和抄袭版文本均为空白(或预处理后全被过滤);其中一篇文本有效、另一篇为空。
def test_similarity_calculate_edge_cases(self):
"""测试相似度计算的边界异常场景"""
calculator = SimilarityCalculator()
processor = TextProcessor()
# 场景1:两篇文本预处理后均为空
empty_text1 = processor.preprocess("!!!")
empty_text2 = processor.preprocess("###")
sim = calculator.calculate(empty_text1, empty_text2)
self.assertEqual(sim, 1.0) # 均为空时视为完全相似
# 场景2:一篇为空,一篇有效
valid_text = processor.preprocess("正常测试文本")
sim = calculator.calculate(empty_text1, valid_text)
self.assertEqual(sim, 0.0) # 一篇为空时视为完全不相似
4. 文件写入异常处理
设计目标:处理结果文件写入时的异常(如无写入权限、磁盘空间不足、路径含非法字符等),保证写入失败时反馈清晰错误原因。
异常场景:结果路径指向系统保护目录;目标磁盘已满;路径含?*:等非法字符。
def test_file_write_errors(self):
"""测试文件写入的异常场景"""
# 场景1:无写入权限的路径(模拟)
no_perm_path = "/root/no_permission_result.txt"
with patch("builtins.open", side_effect=PermissionError):
with self.assertRaises(PermissionError) as context:
FileHandler.write_file(no_perm_path, "test content")
self.assertIn("无权限写入文件", str(context.exception))
# 场景2:路径包含非法字符(Windows场景)
invalid_path = "C:\\test\\*invalid:name*.txt"
with self.assertRaises(ValueError) as context:
FileHandler.write_file(invalid_path, "test")
self.assertIn("路径包含非法字符", str(context.exception))
六、事后总结与过程改进计划
6.1 事后总结
本次计算模块开发中,成果包括:通过模块化设计(拆分文件、文本、算法类)提升了代码可维护性;异常处理覆盖多场景,增强了程序鲁棒性;借助性能分析工具、单元测试框架实现了“量化优化”与“精准测试”。
但也存在问题:命令行参数交互对新手不友好(路径含特殊字符易失败);性能优化初期依赖经验,缺乏工具先行的意识;超长文本、极端编码文件等边缘场景测试覆盖不足,导致后期出现意外问题。
6.2 过程改进计划
6.2.1 改进
- 优化命令行体验:在参数解析时增加路径合法性检查(如检测文件是否存在),并给出更清晰的错误提示。
- 补充测试用例:针对“超长文本”“特殊编码文件”等边缘场景,新增单元测试用例,提升测试覆盖率。
- 技术升级:探索多线程处理大文件以优化性能;考虑引入Word2Vec等语义模型增强相似度计算能力。
- 流程规范:建立“性能分析先行→优化方案验证→测试用例补充”的迭代流程,确保每次改进都有工具与测试保障。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号