大数据面试题解析之数据处理篇-Flink
1.Flink基础
1. 简单介绍一下 Flink
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。并且 Flink 提供了数据分布、容错机制以及资源管理等核心功能。Flink提供了诸多高抽象层的API以便用户编写分布式任务:
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
此外,Flink 还针对特定的应用领域提供了领域库,例如: Flink ML,Flink 的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。 Gelly,Flink 的图计算库,提供了图计算的相关API及多种图计算算法实现。
2. Flink相比传统的Spark Streaming区别?
这个问题是一个非常宏观的问题,因为两个框架的不同点非常之多。但是在面试时有非常重要的一点一定要回答出来:Flink 是标准的实时处理引擎,基于事件驱动。而 Spark Streaming 是微批(Micro-Batch)的模型。
下面我们就分几个方面介绍两个框架的主要区别:
-
架构模型Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor,Flink 在运行时主要包含:Jobmanager、Taskmanager和Slot。
-
任务调度Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图DAG,Spark Streaming 会依次创建 DStreamGraph、JobGenerator、JobScheduler。Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
-
时间机制Spark Streaming 支持的时间机制有限,只支持处理时间。 Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机制来处理滞后数据。
-
容错机制对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能会重复处理,不能做到恰好一次处理语义。Flink 则使用两阶段提交协议来解决这个问题。
3. Flink的组件栈有哪些?
根据 Flink 官网描述,Flink 是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。
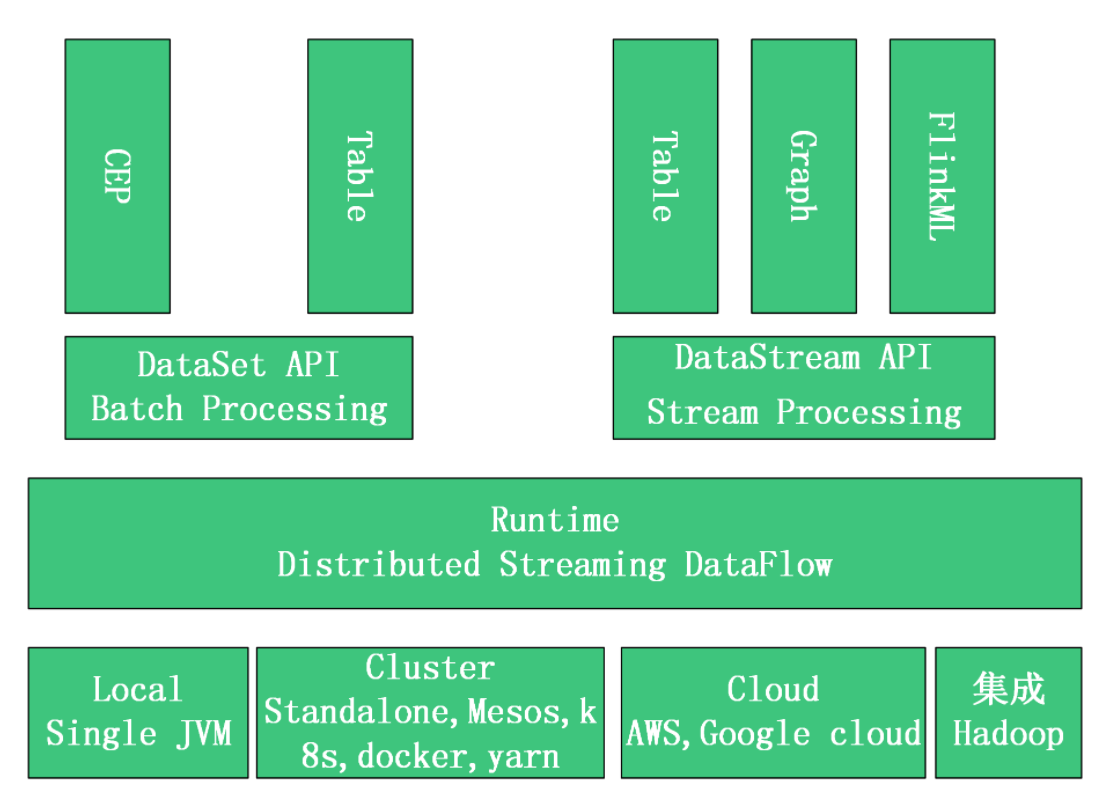
自下而上,每一层分别代表:Deploy 层:该层主要涉及了Flink的部署模式,在上图中我们可以看出,Flink 支持包括local、Standalone、Cluster、Cloud等多种部署模式。Runtime 层:Runtime层提供了支持 Flink 计算的核心实现,比如:支持分布式 Stream 处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。API层:API 层主要实现了面向流(Stream)处理和批(Batch)处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API,后续版本,Flink有计划将DataStream和DataSet API进行统一。Libraries层:该层称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
4.Flink 的运行必须依赖 Hadoop组件吗?
Flink可以完全独立于Hadoop,在不依赖Hadoop组件下运行。但是做为大数据的基础设施,Hadoop体系是任何大数据框架都绕不过去的。Flink可以集成众多Hadooop 组件,例如Yarn、Hbase、HDFS等等。例如,Flink可以和Yarn集成做资源调度,也可以读写HDFS,或者利用HDFS做检查点。
5. 你们的Flink集群规模多大?
大家注意,这个问题看起来是问你实际应用中的Flink集群规模,其实还隐藏着另一个问题:Flink可以支持多少节点的集群规模?在回答这个问题时候,可以将自己生产环节中的集群规模、节点、内存情况说明,同时说明部署模式(一般是Flink on Yarn),除此之外,用户也可以同时在小集群(少于5个节点)和拥有 TB 级别状态的上千个节点上运行 Flink 任务。
6. Flink的基础编程模型了解吗?
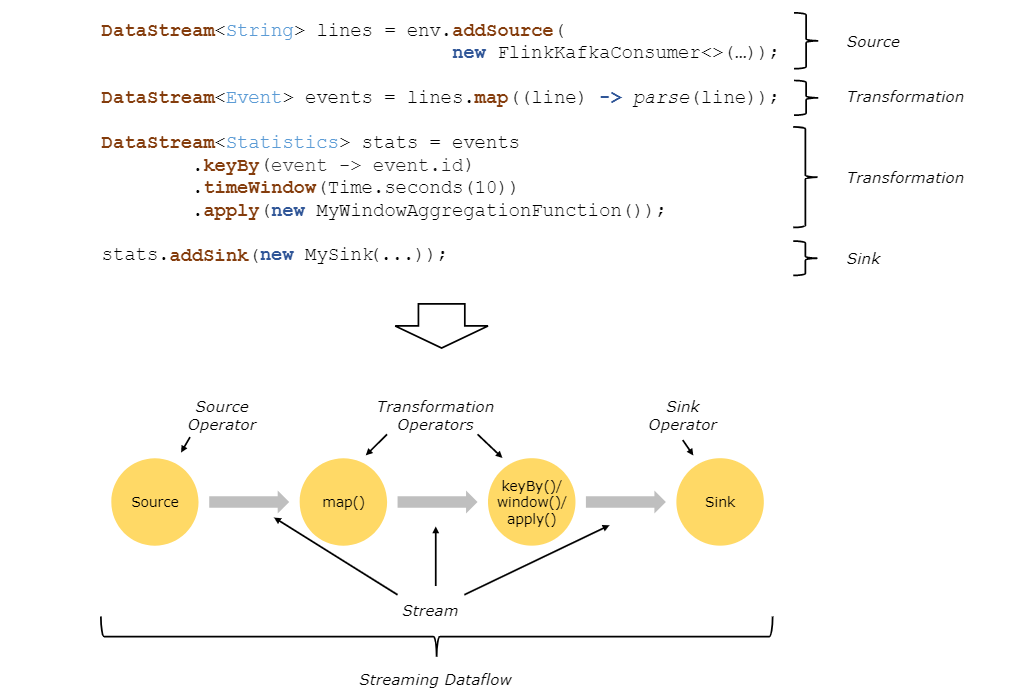
上图是来自Flink官网的运行流程图。通过上图我们可以得知,Flink 程序的基本构建是数据输入来自一个 Source,Source 代表数据的输入端,经过 Transformation 进行转换,然后在一个或者多个Sink接收器中结束。数据流(stream)就是一组永远不会停止的数据记录流,而转换(transformation)是将一个或多个流作为输入,并生成一个或多个输出流的操作。执行时,Flink程序映射到 streaming dataflows,由流(streams)和转换操作(transformation operators)组成。
7. Flink集群有哪些角色?各自有什么作用?
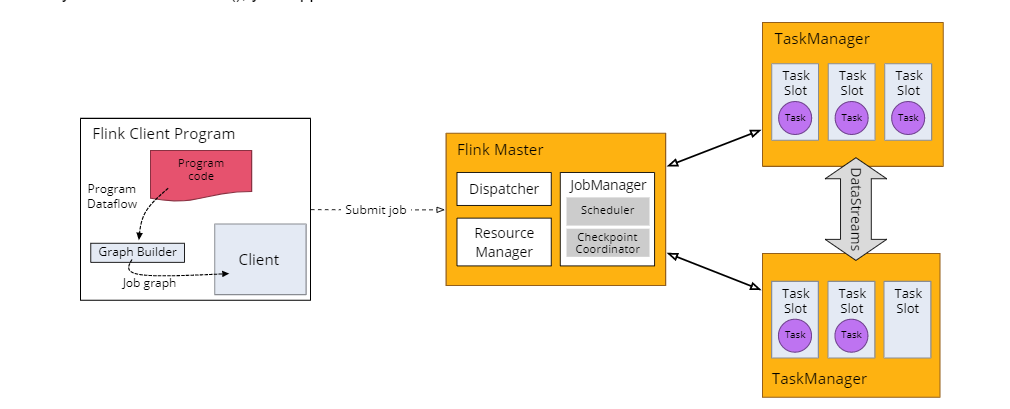
Flink 程序在运行时主要有 TaskManager,JobManager,Client三种角色。其中
-
JobManager扮演着集群中的管理者Master的角色,它是整个集群的协调者,负责接收Flink Job,协调检查点,Failover 故障恢复等,同时管理Flink集群中从节点TaskManager。
-
TaskManager是实际负责执行计算的Worker,在其上执行Flink Job的一组Task,每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。
-
Client是Flink程序提交的客户端,当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。
8. 说说 Flink 资源管理中 Task Slot 的概念
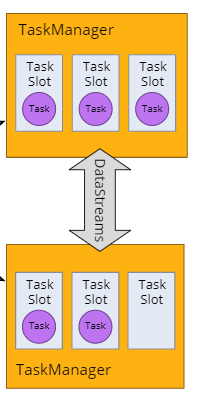
在Flink架构角色中我们提到,TaskManager是实际负责执行计算的Worker,TaskManager 是一个 JVM 进程,并会以独立的线程来执行一个task或多个subtask。为了控制一个 TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念。简单的说,TaskManager会将自己节点上管理的资源分为不同的Slot:固定大小的资源子集。这样就避免了不同Job的Task互相竞争内存资源,但是需要主要的是,Slot只会做内存的隔离。没有做CPU的隔离。
9. 说说 Flink 的常用算子?
Flink 最常用的常用算子包括:Map:DataStream → DataStream,输入一个参数产生一个参数,map的功能是对输入的参数进行转换操作。Filter:过滤掉指定条件的数据。KeyBy:按照指定的key进行分组。Reduce:用来进行结果汇总合并。Window:窗口函数,根据某些特性将每个key的数据进行分组(例如:在5s内到达的数据)
10. 你知道的Flink分区策略?
什么要搞懂什么是分区策略。分区策略是用来决定数据如何发送至下游。目前 Flink 支持了8种分区策略的实现。
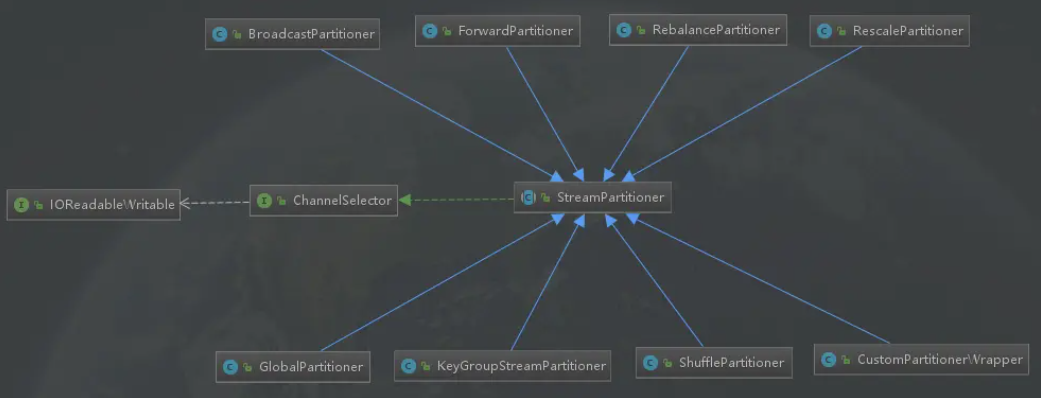
上图是整个Flink实现的分区策略继承图:
GlobalPartitioner数据会被分发到下游算子的第一个实例中进行处理。
ShufflePartitioner数据会被随机分发到下游算子的每一个实例中进行处理。
RebalancePartitioner 数据会被循环发送到下游的每一个实例中进行处理。
RescalePartitioner这种分区器会根据上下游算子的并行度,循环的方式输出到下游算子的每个实例。这里有点难以理解,假设上游并行度为2,编号为A和B。下游并行度为4,编号为1,2,3,4。那么A则把数据循环发送给1和2,B则把数据循环发送给3和4。假设上游并行度为4,编号为A,B,C,D。下游并行度为2,编号为1,2。那么A和B则把数据发送给1,C和D则把数据发送给2。
BroadcastPartitioner广播分区会将上游数据输出到下游算子的每个实例中。适合于大数据集和小数据集做Jion的场景。
ForwardPartitioner用于将记录输出到下游本地的算子实例。它要求上下游算子并行度一样。简单的说,ForwardPartitioner用来做数据的控制台打印。
KeyGroupStreamPartitioner Hash分区器。会将数据按 Key 的 Hash 值输出到下游算子实例中。CustomPartitionerWrapper 用户自定义分区器。需要用户自己实现Partitioner接口,来定义自己的分区逻辑。例如:
static class CustomPartitioner implements Partitioner<String> {

 浙公网安备 33010602011771号
浙公网安备 33010602011771号