
Hadoop支持亿级流量的秘密
目标:
- HDFS是如何从架构上解决单机内存受限问题的
- 揭秘HDFS能支撑亿级别流量的核心源码设计
思考
因为NameNode管理元数据,用户所有的操作请求都要操作NameNode,大一点的平台一天需要运行几十万,上百万的任务。一个任务会有很多的请求,这些所有的请求都到了NameNode(更新目录树),对于Namenode来说这就是亿级的流量,NameNode是如何支持亿级流量的呢?
HDFS如何管理元数据
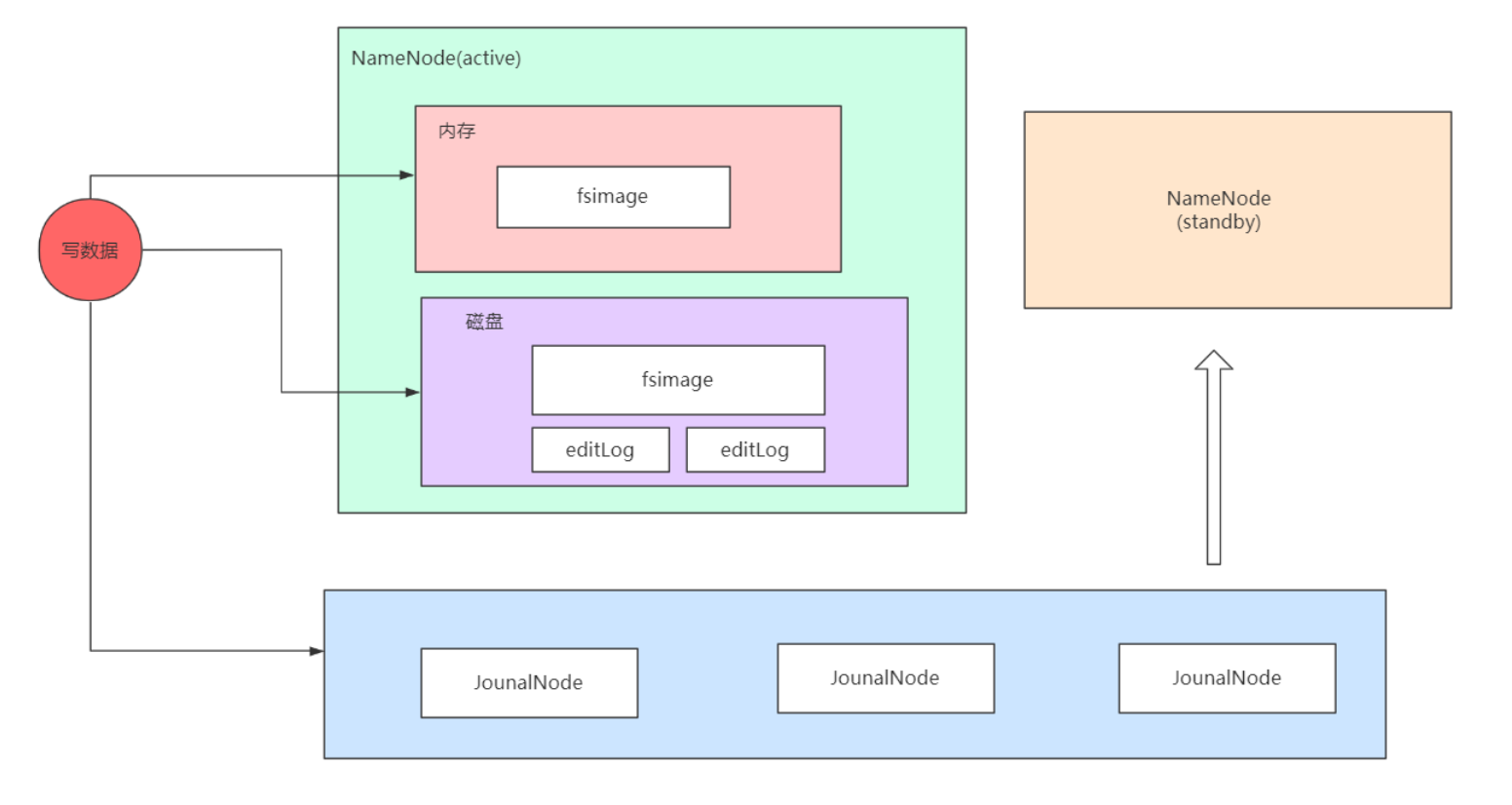
问题:磁盘并不支持高并发,怎么解决呢?
分段加锁和双缓冲方案
分段加锁和双缓冲方案,解决了磁盘高并发的问题
- 分段加锁方案是代码上的设计
- 双缓冲方案是架构上的设计
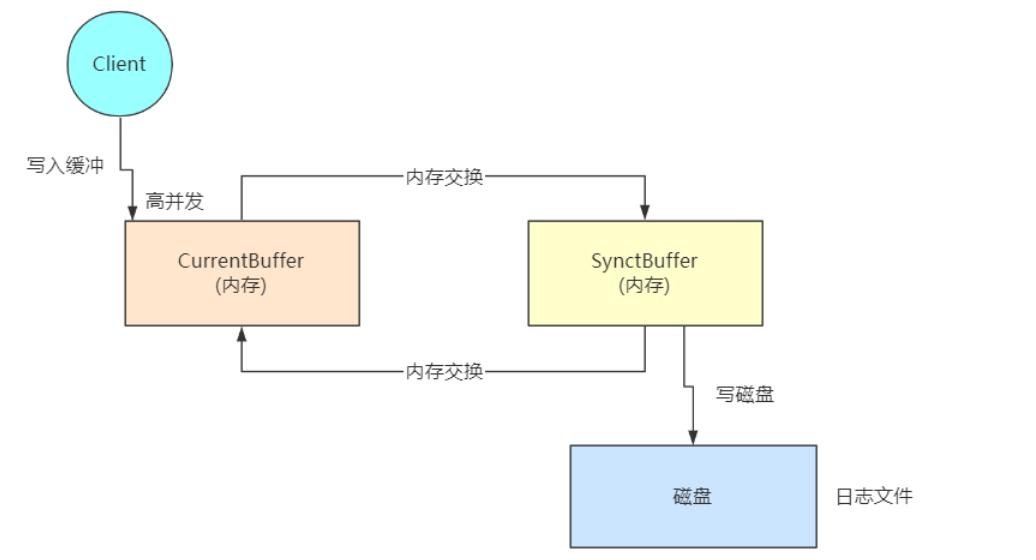
问题:内存满了怎么办?Hadoop团队这个地方没有设计好,需要我们对源码二次开发,进行优化。
代码实现:
import java.util.LinkedList;
public class FSEditLog {
private long txid=0L;
private DoubleBuffer editLogBuffer=new DoubleBuffer();
private volatile Boolean isSyncRunning = false;
private volatile Boolean isWaitSync = false;
private volatile Long syncMaxTxid = 0L;
/**
* 一个线程 就会有自己一个ThreadLocal的副本
*/
private ThreadLocal<Long> localTxid=new ThreadLocal<Long>();
public static void main(String[] args) {
//logEdit("mkdir /data")
}
public void logEdit(String content){
/**
* 因为我们要保证日志的ID要递增,唯一
*
* 线程1, 1
*/
synchronized (this){
//日志的ID号,元数据信息的ID号。
txid++;
/**
* 每个线程都会有自己的一个副本。
* 线程1,1
* 线程2,2
* 线程3,3
*/
localTxid.set(txid);
EditLog log = new EditLog(txid, content);
editLogBuffer.write(log);
} //释放锁
/**
* 内存1:
* 线程1,1 元数据1
* 线程2,2 元数据2
* 线程3,3 元数据3
*/
logSync();
}
private void logSync(){
/**
*
* 线程1,ID号:1
* 接下来,线程2过来了
* 接下来,线程3过来
*
* 接下来线程4进来了
* 接下来线程5进来了
*/
synchronized (this){
//当前是否正在往磁盘写数据,默认是false
//这个是值为true
if(isSyncRunning){
//线程2,获取当前的元数据日志的编号 2
//线程3,获取当前的元数据日志编号 3
//线程4, 获取当前的元数据日志编号 4
//线程5,获取当前的元数据日志编号 5
long txid = localTxid.get();
//5 <= 3
if(txid <= syncMaxTxid){
//直接返回,不需要干活了。
//因为已经有人肯定在帮他往磁盘上面去刷写数据了。
//所以他就不需要操作了
return;
}
//是否有人在等待,false
//线程5过来了,但是刚刚线程4把这个值改变了。true
if(isWaitSync){
//直接返回
return;
}
//重新赋值
isWaitSync = true;
while(isSyncRunning){
try {
//线程4就会在这儿等待
//释放锁
wait(2000);
}catch (Exception e){
e.printStackTrace();
}
}
//重新赋值
isWaitSync = false;
}
//交换内存,我是直接交换的内存,肯定是简单粗暴
//真正的源码里面是有判断。
//如果来不来就直接交换内存,频繁的交换内存,也是很影响性能的。
editLogBuffer.setReadyToSync();
if(editLogBuffer.currentBuffer.size() > 0) {
//获取当前 内存2(正在往磁盘上面写数据的那个内存)
//里面元数据日志日志编号最大的是多少
syncMaxTxid = editLogBuffer.getSyncMaxTxid();
}
//说明接下来就要往磁盘上面写元数据日志信息了。
isSyncRunning = true;
} //释放锁
//往磁盘上面写数据(这个操作是很耗费时间的)
/**
* 线程1:在内存2(元数据1,元数据2,元数据3)把数据写到磁盘上面
*
* 线程4:在内存2(元数据4,元数据5)把数据写到磁盘上面
*
*
*/
editLogBuffer.flush(); //这个地方写完了。
synchronized (this) {
//状态恢复
isSyncRunning = false;
//唤醒当前wait的线程。
notify();
}
}
/**
* 使用了面向对象的思想,把一条日志看成一个对象。
* 日志信息,或者就是我们说的元数据信息。
*/
class EditLog{
//日志的编号,递增,唯一。
long txid;
//日志内容
String content;//mkdir /data
//构造函数
public EditLog(long txid,String content){
this.txid = txid;
this.content = content;
}
//方便我们打印日志
@Override
public String toString() {
return "EditLog{" +
"txid=" + txid +
", content='" + content + '\'' +
'}';
}
}
/**
* 双缓冲算法
*/
class DoubleBuffer{
//内存1
LinkedList<EditLog> currentBuffer = new LinkedList<EditLog>();
//内存2
LinkedList<EditLog> syncBuffer= new LinkedList<EditLog>();
/**
* 把数据写到当前内存
* @param log
*/
public void write(EditLog log){
currentBuffer.add(log);
}
/**
* 两个内存交换数据
*/
public void setReadyToSync(){
LinkedList<EditLog> tmp= currentBuffer;
currentBuffer = syncBuffer;
syncBuffer = tmp;
}
/**
* 获取当前正在刷磁盘的内存里的ID最大的值。
* @return
*/
public Long getSyncMaxTxid(){
return syncBuffer.getLast().txid;
}
/**
* 就是把数据涮写到磁盘上面
* 为了演示效果,所以我们把打印出来
*/
public void flush(){
for(EditLog log:syncBuffer){
//这儿就是把数据写到磁盘
//我这儿没还有真的写到磁盘,打印了一下。
System.out.println("存入磁盘日志信息:"+log);
}
//清空内存
syncBuffer.clear();
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号