
Redis持久化及高可用方案
一、持久化
Redis是内存数据库,宕机后数据会消失。为了快速恢复数据,需要提供持久化机制。Redis有俩种持久化方式:RDB和AOF。
1.1 RDB
RDB(Redis DataBase),是redis默认的存储方式,RDB方式是通过快照( snapshotting )完成的,不关注过程。
触发快照的方式:1. 符合自定义配置的快照规则;2. 执行save或者bgsave命令;3. 执行flushall命令;4. 执行主从复制操作 (第一次) 5. 在redis.conf中配置:save 多少秒内 数据变了多少。
save "" # 不使用RDB存储 不能主从 save 900 1 # 表示15分钟(900秒钟)内至少1个键被更改则进行快照。 save 300 10 # 表示5分钟(300秒)内至少10个键被更改则进行快照。 save 60 10000 # 表示1分钟内至少10000个键被更改则进行快照。
6. 命令显式触发,在客户端中输入:bgsave。
RDB执行流程(原理)
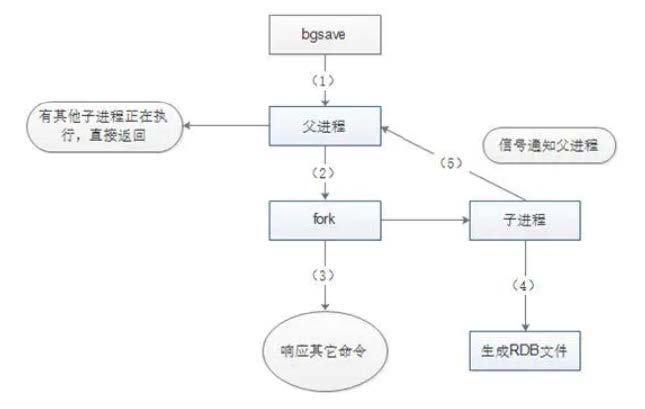
1. Redis父进程首先判断:当前是否在执行save,或bgsave/bgrewriteaof(aof文件重写命令)的子进程,如果在执行则bgsave命令直接返回。
2. 父进程执行fork(调用OS函数复制主进程)操作创建子进程,这个复制过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令。
3. 父进程fork后,bgsave命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令。
4. 子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换。(RDB始终完整)
5. 子进程发送信号给父进程表示完成,父进程更新统计信息。
6. 父进程fork子进程后,继续工作。
RDB优点:RDB是二进制压缩文件,占用空间小,便于传输(传给slaver)。主进程fork子进程,可以最大化Redis性能,主进程不能太大,Redis的数据量不能太大,复制过程中主进程阻塞。
缺点:不保证数据完整性,会丢失最后一次快照以后更改的所有数据。
1.2 AOF
AOF(append only file)是Redis的另一种持久化方式。默认不开启,开启AOF持久化后Redis 将所有对数据库进行过写入的命令(及其参数)(RESP)记录到 AOF 文件, 以此达到记录数据库状态的目的。当Redis重启后只要按顺序回放这些命令就会恢复到原始状态了。AOF会记录过程,RDB只管结果。
AOF开启配置redis.conf
# 可以通过修改redis.conf配置文件中的appendonly参数开启 appendonly yes # AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的。 dir ./ # 默认的文件名是appendonly.aof,可以通过appendfilename参数修改 appendfilename appendonly.aof
文件写入和保存
WRITE:根据条件,将 aof_buf 中的缓存写入到AOF文件。 SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
AOF保存模式:推荐每秒保存一次(也是默认设置),在这种模式中, SAVE原则上每隔一秒钟就会执行一次, 因为SAVE操作是由后台子线程(fork)调用的, 所以它不会引起服务器主进程阻塞。
1.3 RDB和AOF对比
1、RDB存某个时刻的数据快照,采用二进制压缩存储,AOF存操作命令,采用文本存储(混合)。
2、RDB性能高、AOF性能较低。
3、RDB在配置触发状态会丢失最后一次快照以后更改的所有数据,AOF设置为每秒保存一次,则最多丢2秒的数据。
4、Redis以主服务器模式运行,RDB不会保存过期键值对数据,Redis以从服务器模式运行,RDB会保存过期键值对,当主服务器向从服务器同步时,再清空过期键值对。AOF写入文件时,对过期的key会追加一条del命令,当执行AOF重写时,会忽略过期key和del命令。
二、慢查询优化
使用slowlog get 可以获得执行较慢的redis命令,针对该命令可以进行优化:
1、尽量使用短的key,对于value有些也可精简,能使用int就int。
2、避免使用keys *、hgetall等全量操作。
3、减少大key的存取,打散为小key。
4、将rdb改为aof模式,rdb fork子进程时主进程阻塞,redis大幅下降。关闭持久化(适合于数据量较小)或改成aof 命令式。
5、想要一次添加多条数据的时候可以使用管道。
6、尽可能地使用哈希存储。
7、尽量限制下redis使用的内存大小,这样可以避免redis使用swap分区或者出现OOM错误,避免内存与硬盘的swap。
三、高可用方案
3.1 主从配置
主Redis无需配置,从Redis修改redis.conf文件
# slaveof <masterip> <masterport> # 表示当前【从服务器】对应的【主服务器】的IP是192.168.10.135,端口是6379。 replicaof 127.0.0.1 6379
读写分离:一主多从,主从同步,主负责写,从负责读。提升Redis的性能和吞吐量。
数据容灾:从机是主机的备份,主机宕机,从机可读不可写。默认情况下主机宕机后,从机不可为主机。利用哨兵可以实现主从切换,坐到高可用。
3.2 哨兵模式
哨兵(sentinel)是Redis的高可用性(High Availability)的解决方案。由一个或多个sentinel实例组成sentinel集群可以监视一个或多个主服务器和多个从服务器。当主服务器进入下线状态时,sentinel可以将该主服务器下的某一从服务器升级为主服务器继续提供服务,从而保证redis的高可用性。
部署方案
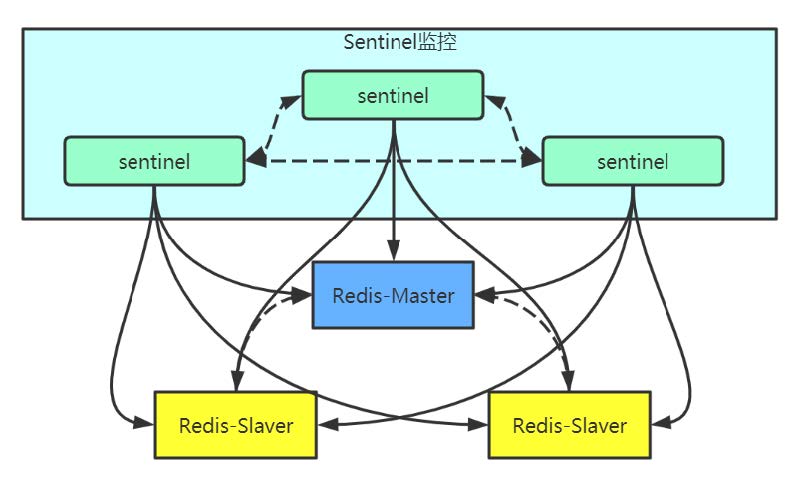
启动Sentinel: Sentinel是一个特殊的Redis服务器,不会进行持久化。Sentinel实例启动后,每个Sentinel会创建2个连向主服务器的网络连接。命令连接:用于向主服务器发送命令,并接收响应; 订阅连接:用于订阅主服务器。
获取从服务器信息:当Sentinel发现主服务器有新的从服务器出现时,Sentinel还会向从服务器建立命令连接和订阅连接。在命令连接建立之后,Sentinel还是默认10s一次,向从服务器发送info命令,并记录从服务器的信息。
检测主观下线状态:Sentinel每秒一次向所有与它建立了命令连接的实例(主服务器、从服务器和其他Sentinel)发送PING命令。实例在down-after-milliseconds毫秒内返回无效回复(除了+PONG、-LOADING、-MASTERDOWN外)。实例在down-after-milliseconds毫秒内无回复(超时),Sentinel就会认为该实例主观下线(SDown)。
检查客观下线状态:如果达到Sentinel配置中的quorum数量的Sentinel实例都判断主服务器为主观下线,则该主服务器就会被判定为客观下线(ODown)。
选举Leader Sentinel:当一个主服务器被判定为客观下线后,监视这个主服务器的所有Sentinel会通过选举算法(raft),选出一个Leader Sentinel去执行failover(故障转移)操作。
1、该Sentinel会先看看自己有没有投过票,如果自己已经投过票给其他Sentinel了,在一定时间内自己就不会成为Leader。
2、如果该Sentinel还没投过票,那么它就成为Candidate。
3、Sentinel需要完成几件事情:更新故障转移状态为start, 当前epoch加1,相当于进入一个新term,在Sentinel中epoch就是Raft协议中的term。向其他节点发送is-master-down-by-addr 命令请求投票。命令会带上自己的epoch。给自己投一票(leader、leader_epoch)。
4、当其它哨兵收到此命令时,可以同意或者拒绝它成为领导者;(通过判断epoch)。
5、Candidate会不断的统计自己的票数,直到他发现认同他成为Leader的票数超过一半而且超过它配置的quorum,这时它就成为了Leader。
6、其他Sentinel等待Leader从slave选出master后,检测到新的master正常工作后,就会去掉客观下线的标识。
故障转移:1.它会将失效Master的其中一个Slave升级为新的Master , 并让失效Master的其他Slave改为复制新的Master ;2. 当客户端试图连接失效的Master时,集群也会向客户端返回新Master的地址,使得集群可以使用现在的Master替换失效Master。3. Master和Slave服务器切换后,Master的redis.conf 、Slave 的redis.conf 和sentinel.conf 的配置文件的内容都会发生相应的改变,即Master主服务器的redis.conf配置文件中会多一行replicaof的配置,sentinel.conf的监控目标会随之调换。
分区:分区是将数据分布在多个Redis实例(Redis主机)上,以至于每个实例只包含一部分数据。
分区方式:1.根据id数字的范围分区。好处:实现简单,方便迁移和扩展。缺点:热点数据分部不均,性能损失。非数字型key比如uuid无法使用(可使用雪花算法替代)。 2. hash分区,使用简单的hash算法即可。Redis实例=hash(key)%N,key是要分区的键如user_id, N是Redis实例个数。好处:支持任何类型的key,热点分布较均匀,性能好。缺点:迁移复杂,需重新计算,扩展性差(利用一致性hash环)。 3. Client端分区,对于一个给定的key, 客户端直接选择正确的节点来进行读写。4.proxy端分区 5. 官方cluster分区

 浙公网安备 33010602011771号
浙公网安备 33010602011771号