
MySQL事务及集群架构
一、ACID 特性
在关系型数据库管理系统中,一个逻辑工作单元要成为事务,必须满足这 4 个特性,即所谓的 ACID:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
原子性:事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。修改---》Buffer Pool修改---》刷盘。可能会有下面两种情况:
事务提交了,如果此时Buffer Pool的脏页没有刷盘,如何保证修改的数据生效? Redo
如果事务没提交,但是Buffer Pool的脏页刷盘了,如何保证不该存在的数据撤销?Undo
持久性:指的是一个事务一旦提交,它对数据库中数据的改变就应该是永久性的,后续的操作或故障不应该对其有任何影响,不会丢失。
隔离性:指的是一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对其他的并发事务是隔离的。
一致性:指的是事务开始之前和事务结束之后,数据库的完整性限制未被破坏。
二、事务
2.1 并发事务可能带来的问题
比如:更新丢失、脏读、不可重复读、幻读等。
更新丢失:当两个或多个事务更新同一行记录,会产生更新丢失现象。可以分为回滚覆盖和提交覆盖。回滚覆盖:一个事务回滚操作,把其他事务已提交的数据给覆盖了。提交覆盖:一个事务提交操作,把其他事务已提交的数据给覆盖了。
脏读:一个事务读取到了另一个事务修改但未提交的数据。
不可重复读: 一个事务中多次读取同一行记录不一致,后面读取的跟前面读取的不一致。
幻读: 一个事务中多次按相同条件查询,结果不一致。后续查询的结果和面前查询结果不同,多了或少了几行记录。
2.2 解决方案
MVCC(Multi Version Concurrency Control)被称为多版本控制,是指在数据库中为了实现高并发的数据访问,对数据进行多版本处理,并通过事务的可见性来保证事务能看到自己应该看到的数据版本。多版本控制很巧妙地将稀缺资源的独占互斥转换为并发,大大提高了数据库的吞吐量及读写性能。MVCC最大的好处是读不加锁,读写不冲突。
快照读:读取的是记录的快照版本(有可能是历史版本),不用加锁。(select)
当前读:读取的是记录的最新版本,并且当前读返回的记录,都会加锁,保证其他事务不会再并发修改这条记录。(select... for update 或lock in share mode,insert/delete/update)
三、锁
读锁(S锁):共享锁,针对同一份数据,多个读操作可以同时进行而不会互相影响。事务A对记录添加了S锁,可以对记录进行读操作,不能做修改,其他事务可以对该记录追加S锁,但是不能追加X锁,需要追加X锁,需要等记录的S锁全部释放。
写锁(X锁):排他锁,当前写操作没有完成前,它会阻断其他写锁和读锁。
悲观锁(Pessimistic Locking),是指在数据处理过程,将数据处于锁定状态,一般使用数据库的锁机制实现。从广义上来讲,前面提到的行锁、表锁、读锁、写锁、共享锁、排他锁等,这些都属于悲观锁范畴。
表级锁每次操作都锁住整张表,并发度最低。
常用命令如下:手动增加表锁。
lock table 表名称 read|write,表名称2 read|write;
查看表上加过的锁
show open tables;
删除表锁
unlock tables;
乐观锁: 是相对于悲观锁而言的,它不是数据库提供的功能,需要开发者自己去实现。在数据库操作时,想法很乐观,认为这次的操作不会导致冲突,因此在数据库操作时并不做任何的特殊处理,即不加锁,而是在进行事务提交时再去判断是否有冲突了。
乐观锁的使用:
查询商品信息
select (quantity,version) from products where id=1;
根据商品信息生成订单
insert into orders ...
insert into items ...
修改商品库存
update products set quantity=quantity-1,version=version+1where id=1 and version=#{version};
死锁与解决方案
①表级锁死锁
产生原因:用户A访问表A(锁住了表A),然后又访问表B;另一个用户B访问表B(锁住了表B),然后企图访问表A;这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B才能继续,同样用户B要等用户A释放表A才能继续,这就死锁就产生了。
解决方案:这种死锁比较常见,是由于程序的BUG产生的,除了调整的程序的逻辑没有其它的办法。仔细分析程序的逻辑,对于数据库的多表操作时,尽量按照相同的顺序进行处理,尽量避免同时锁定两个资源,如操作A和B两张表时,总是按先A后B的顺序处理, 必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源。
②行级锁死锁
产生原因1:如果在事务中执行了一条没有索引条件的查询,引发全表扫描,把行级锁上升为全表记录锁定(等价于表级锁),多个这样的事务执行后,就很容易产生死锁和阻塞,最终应用系统会越来越慢,发生阻塞或死锁。
解决方案:SQL语句中不要使用太复杂的关联多表的查询;使用explain“执行计划"对SQL语句进行分析,对于有全表扫描和全表锁定的SQL语句,建立相应的索引进行优化。
产生原因2:两个事务分别想拿到对方持有的锁,互相等待,于是产生死锁。
解决方案2: 在同一个事务中,尽可能做到一次锁定所需要的所有资源按照id对资源排序,然后按顺序进行处理。
③共享锁转换为排他锁
产生原因:事务A查询一条纪录,然后更新该条纪录;此时事务B也更新该条纪录,这时事务B的排他锁由于事务A有共享锁,必须等A释放共享锁后才可以获取,只能排队等待。事务A再执行更新操作时,此处发生死锁,因为事务A需要排他锁来做更新操作。但是,无法授予该锁请求,因为事务B已经有一个排他锁请求,并且正在等待事务A释放其共享锁。
解决方案:对于按钮等控件,点击立刻失效,不让用户重复点击,避免引发同时对同一条记录多次操作;使用乐观锁进行控制。乐观锁机制避免了长事务中的数据库加锁开销,大大提升了大并发量下的系统性能。需要注意的是,由于乐观锁机制是在我们的系统中实现,来自外部系统的用户更新操作不受我们系统的控制,因此可能会造成脏数据被更新到数据库中;
死锁排查:
查看死锁日志
通过show engine innodb status命令查看近期死锁日志信息。
使用方法:1、查看近期死锁日志信息;2、使用explain查看下SQL执行计划查看锁状态变量
通过show status like'innodb_row_lock%‘命令检查状态变量,分析系统中的行锁的争夺情况
Innodb_row_lock_current_waits:当前正在等待锁的数量
Innodb_row_lock_time:从系统启动到现在锁定总时间长度
Innodb_row_lock_time_avg: 每次等待锁的平均时间
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次锁的时间
Innodb_row_lock_waits:系统启动后到现在总共等待的次数
如果等待次数高,而且每次等待时间长,需要分析系统中为什么会有如此多的等待,然后着手定制优化。
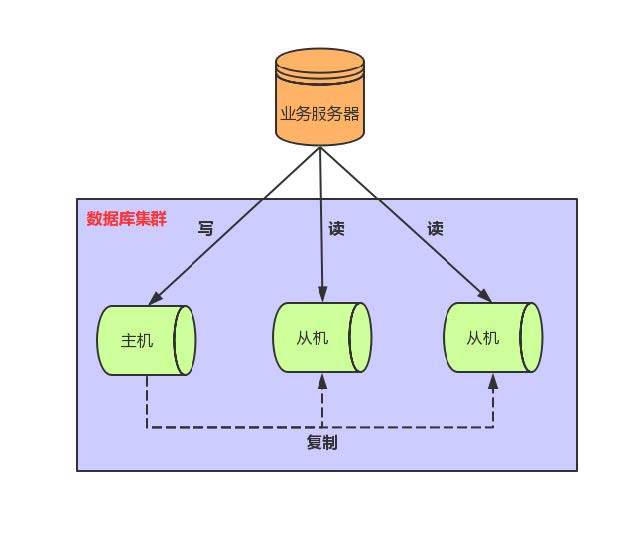
三、集群架构
3.1 主从模式
MySQL主从模式是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,从节点可以复制主数据库中的所有数据库,或者特定的数据库,或者特定的表。
实现步骤:主库将数据库的变更操作记录到Binlog日志文件中,从库读取主库中的Binlog日志文件信息写入到从库的Relay Log中继日志中,从库读取中继日志信息在从库中进行Replay,更新从库数据信息。
3.2 半同步复制
为了提升数据安全,MySQL让Master在某一个时间点等待Slave节点的ACK(Acknowledgecharacter)消息,接收到ACK消息后才进行事务提交,这也是半同步复制的基础。
3.3 并行复制
采用多线程,基于上述SQL Thread多线程思想不断优化,减少复制延迟。
3.4 读写分离
互联网业务中,往往读多写少,这时候数据库的读会首先成为数据库的瓶颈。如果我们已经优化了SQL,但是读依旧还是瓶颈时,这时就可以选择“读写分离”架构。读写分离首先需要将数据库分为主从库,一个主库用于写数据,多个从库完成读数据的操作,主从库之间通过主从复制机制进行数据的同步。
读写分离会产生主从同步延迟,解决方案:
写后立刻读:在写入数据库后,某个时间段内读操作就去主库,之后读操作访问从库。
二次查询: 先去从库读取数据,找不到时就去主库进行数据读取。该操作容易将读压力返还给主库,为了避免恶意攻击,建议对数据库访问API操作进行封装,有利于安全和低耦合。
根据业务特殊处理:根据业务特点和重要程度进行调整,比如重要的,实时性要求高的业务数据读写可以放在主库。对于次要的业务,实时性要求不高可以进行读写分离,查询时去从库查询。
3.5 双主模式
单主如果发生单点故障,从库切换成主库还需要作改动。因此如果是双主或者多主,就会增加MySQL入口,提升了主库的可用性。双主双写容易发生ID冲突,更新丢失等问题,建议双主单写。
3.6 MMM架构
MMM(Master-Master Replication Manager for MySQL)是一套用来管理和监控双主复制,支持双主故障切换的第三方软件。MMM 使用Perl语言开发,虽然是双主架构,但是业务上同一时间只允许一个节点进行写入操作。
故障处理:MMM 包含writer和reader两类角色,分别对应写节点和读节点。当 writer节点出现故障,程序会自动移除该节点上的VIP写操作切换到Master2,并将Master2设置为writer将所有Slave节点会指向Master2。
3.7 MHA架构
MHA(Master High Availability)是一套比较成熟的 MySQL高可用方案,也是一款优秀的故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。MHA还支持在线快速将Master切换到其他主机,通常只需0.5-2秒。
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。负责检测master是否宕机、控制故障转移、检查MySQL复制状况等。MHA Node运行在每台MySQL服务器上,不管是Master角色,还是Slave角色,都称为Node,是被监控管理的对象节点,负责保存和复制master的二进制日志、识别差异的中继日志事件并将其差异的事件应用于其他的slave、清除中继日志。
MHA故障处理机制:把宕机master的binlog保存下来,根据binlog位置点找到最新的slave,用最新slave的relay log修复其它slave,将保存下来的binlog在最新的slave上恢复。将最新的slave提升为master,将其它slave重新指向新提升的master,并开启主从复制。
MHA优点:自动故障转移快,主库崩溃不存在数据一致性问题,性能优秀,支持半同步复制和异步复制,一个Manager监控节点可以监控多个集群。
3.7 主备切换
主备切换是指将备库变为主库,主库变为备库,有可靠性优先和可用性优先两种策略。
3.8 分库分表
垂直拆分有垂直分库,垂直分表俩种方案。
垂直分库:如将用户表和订单表分别拆到不同的库中。
垂直分表:将一张表中不常用的字段拆分到另一张表中。
垂直拆分优点: 拆分后业务清晰,拆分规则明确;易于数据的维护和扩展;可以使得行数据变小,一个数据块 (Block) 就能存放更多的数据,在查询时就会减少 I/O 次数;可以达到最大化利用Cache的目的,具体在垂直拆分的时候可以将不常变的字段放一起,将经常改变的放一起;便于实现冷热分离的数据表设计模式。
垂直拆分缺点:主键出现冗余,需要管理冗余列;会引起表连接JOIN操作,可以通过在业务服务器上进行join来减少数据库压力,提高了系统的复杂度;依然存在单表数据量过大的问题;事务处理复杂。
水平拆分是通过某个字段或多个,根据某种规则将数据拆分到多个库或多个表中。解决表中记录过多问题。垂直拆分是解决表过多或者表字段过多问题。
水平拆分优点:拆分规则设计好,join操作基本可以数据库做;不存在单库大数据,高并发的性能瓶颈;切分的表的结构相同,应用层改造较少,只需要增加路由规则即可;提高了系统的稳定性和负载能力。
水平拆分缺点:拆分规则难以抽象;跨库Join性能较差;分片事务的一致性难以解决;数据扩容的难度和维护量极大。
3.9 分片策略
分片(Sharding)就是用来确定数据在多台存储设备上分布的技术。Shard这个词的意思是“碎片”,如果将一个数据库当作一块大玻璃,将这块玻璃打碎,那么每一小块都称为数据库的碎片(Database
Sharding)。将一个数据库打碎成多个的过程就叫做分片,分片是属于横向扩展方案。
分片:表示分配过程,是一个逻辑上概念,表示如何实现。
分库分表:表示分配结果,是一个物理上概念,表示最终实现的结果。
分片策略:
基于范围分片:根据特定字段的范围进行拆分,比如用户ID、订单时间、产品价格等。例如:{[1 - 100] => Cluster A, [101 - 199] => Cluster B}
优点:新的数据可以落在新的存储节点上,如果集群扩容,数据无需迁移。
缺点:数据热点分布不均,数据冷热不均匀,导致节点负荷不均。
哈希取模分片:整型的Key可直接对设备数量取模,其他类型的字段可以先计算Key的哈希值,然后再对设备数量取模。假设有n台设备,编号为0 ~ n-1,通过Hash(Key) % n就可以确定数据所在的设备编号。该模式也称为离散分片。A:1,6,11,16,21 B:2,7,12,17,22 C:3,8,13,18,23 D:4,9,14,19,24 E:5,10,15,20,25
优点:实现简单,数据分配比较均匀,不容易出现冷热不均,负荷不均的情况。
缺点:扩容时会产生大量的数据迁移,比如从n台设备扩容到n+1,绝大部分数据需要重新分配和迁移。
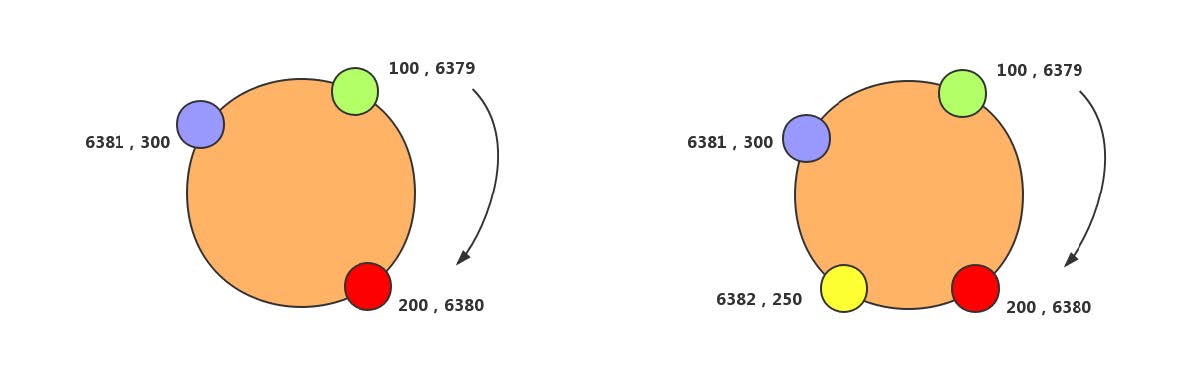
一致性哈希分片:采用Hash取模的方式进行拆分,后期集群扩容需要迁移旧的数据。使用一致性Hash算法能够很大程度的避免这个问题,所以很多中间件的集群分片都会采用一致性Hash算法。一致性Hash是将数据按照特征值映射到一个首尾相接的Hash环上,同时也将节点(按照IP地址或者机器名Hash)映射到这个环上。对于数据,从数据在环上的位置开始,顺时针找到的第一个节点即为数据的存储节点。Hash环示意图与数据的分布如下。
3.9 扩容方案
当系统用户进入了高速增长期时,即便是对数据进行分库分表,但数据库的容量,还有表的数据量也总会达到天花板。当现有数据库达到承受极限时,就需要增加新服务器节点数量进行横向扩容。
停机扩容:站点发布一个公告,例如:“为了为广大用户提供更好的服务,本站点将在今晚00:00-2:00之间升级,给您带来不便抱歉";时间到了,停止所有对外服务;新增n个数据库,然后写一个数据迁移程序,将原有x个库的数据导入到最新的y个库中。比如分片规则由%x变为%y;数据迁移完成,修改数据库服务配置,原来x个库的配置升级为y个库的配置重启服务,连接新库重新对外提供服务
平滑扩容:平滑扩容方案能够实现n库扩2n库的平滑扩容,增加数据库服务能力,降低单库一半的数据量。其核心原理是:成倍扩容,避免数据迁移。步骤:①新增成倍数据库,配置双主进行数据同步。②数据同步完成之后,配置双主双写。③数据同步完成后,删除双主同步,修改数据库配置,并重启。④此时已经扩容完成,但此时的数据并没有减少,新增的数据库跟旧的数据库一样多的数据,此时还需要写一个程序,清空数据库中多余的数据。适用场景:大型网站,对高可用要求高的服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号